

 [Paper 리뷰] EATS: End-to-End Adversarial Text-to-Speech
[Paper 리뷰] EATS: End-to-End Adversarial Text-to-Speech
EATS: End-to-End Adversarial Text-to-SpeechText-to-Speech pipeline은 일반적으로 multiple stage 방식으로 구성됨EATSNormalized text나 phoneme에서 end-to-end 방식으로 음성을 합성하는 모델Feed-forward generator와 token length prediction에 기반한 differentiable alignment search를 통해 효과적인 training과 추론을 지원Adversarial feedback과 prediction loss를 조합하여 high-fidelity의 음성을 합성추가적으로 생성된 audio의 temporal variation을 capture 할 수 있는 dynamic time war..
 [Paper 리뷰] MSMC-TTS: Multi-Stage Multi-Codebook VQ-VAE based Neural TTS
[Paper 리뷰] MSMC-TTS: Multi-Stage Multi-Codebook VQ-VAE based Neural TTS
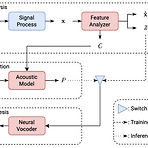
MSMC-TTS: Multi-Stage Multi-Codebook VQ-VAE based Neural TTSVector-quantized, compact speech representation을 도입하여 neural text-to-speech의 성능을 향상할 수 있음MSMC-TTSVector-Quantized Variational AutoEncoder based feature를 채택하여 acoustic feature를 서로 다른 time resolution의 sequence로 encoding 하고, 이를 multiple codebook으로 quantize 함Prediction 과정에서는 multi-stage predictor는 Euclidean distance와 triplet loss를 최소화하여 inp..
 [Paper 리뷰] DenoiSpeech: Denoising Text to Speech with Frame-level Noise Modeling
[Paper 리뷰] DenoiSpeech: Denoising Text to Speech with Frame-level Noise Modeling
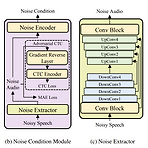
DenoiSpeech: Denoising Text to Speech with Frame-level Noise ModelingText-to-Speech 모델을 학습하기 위해서는 고품질의 speech data가 필요하지만, 대부분 noisy speech를 포함하고 있음DenoiSpeechNoisy speech data를 사용하여 clean speech를 합성할 수 있는 Text-to-Speech 모델모델과 jointly train 되는 noise condition module을 사용하여 fine-grained frame-level noise를 모델링하여 real-world noisy speech를 처리함논문 (ICASSP 2021) : Paper Link1. IntroductionText-to-Speech ..
 [Paper 리뷰] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
[Paper 리뷰] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
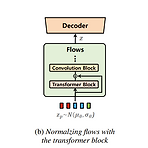
VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture DesignSingle-stage text-to-speech model은 기존의 two-stage 방식보다 더 우수한 합성 품질을 보이고 있지만, phoneme conversion에 대한 dependency와 computational efficiency 측면에서 개선이 필요함VITS2기존의 VITS structure를 개선하여 보다 natural 한 음성 합성과 multi-speaker에서 더 나은 speaker similarity를 지원Fully end-to-end single-stage approac..
 [Paper 리뷰] SANE-TTS: Stable and Natural End-to-End Multilingual Text-to-Speech
[Paper 리뷰] SANE-TTS: Stable and Natural End-to-End Multilingual Text-to-Speech
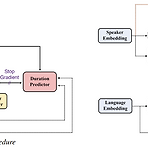
SANE-TTS: Stable and Natural End-to-End Multilingual Text-to-SpeechStable 하고 natural 한 end-to-end multilingual text-to-speech 모델이 필요함SANE-TTSMultilingual synthesis의 naturalness를 향상하기 위해 domain adversarial training을 도입추가적으로 speaker regularization loss를 적용하여 duration predictor의 speaker embedding을 zero-vector로 대체해 cross-lingual synthesis를 stablize 함논문 (INTERSPEECH 2021) : Paper Link1. IntroductionM..
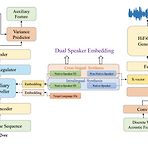 [Paper 리뷰] DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
[Paper 리뷰] DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-SpeechCross-lingual text-to-speech는 speaker timbre를 정확하게 retain 하면서 nativeness를 반영하는 것이 어려움DSE-TTSMel-spectrogram 보다 더 적은 speaker information을 포함하는 vector-quantized acoustic feature를 활용해당 acoustic feature를 기반으로 speaking style을 반영하는 Dual Speaker Embedding을 도입- 한 embedding은 linguistic speaking stlye을 학습하기 위해 acoustic model에 전달되고,- 다른 embedd..