

 [Paper 리뷰] XTTS: A Massively Multilingual Zero-Shot Text-to-Speech Model
[Paper 리뷰] XTTS: A Massively Multilingual Zero-Shot Text-to-Speech Model
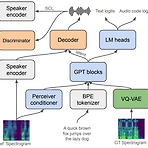
XTTS: A Massively Multilingual Zero-Shot Text-to-Speech Model대부분의 zero-shot multi-speaker text-to-speech 모델은 single language만 지원함XTTS16개의 다양한 low/medium resource language로 task를 확장Multilingual training을 지원하고 voice cloning을 개선하여 빠른 training/추론 속도를 달성논문 (INTERSPEECH 2024) : Paper Link1. IntroductionZero-shot multi-speaker Text-to-Speech (ZS-TTS)는 few-second speech를 기반으로 unseen speaker에 대한 음성 합성을 목..
 [Paper 리뷰] NaturalSpeech: End-to-End Text-to-Speech Synthesis with Human-Level Quality
[Paper 리뷰] NaturalSpeech: End-to-End Text-to-Speech Synthesis with Human-Level Quality
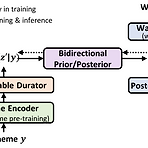
NaturalSpeech: End-to-End Text-to-Speech Synthesis with Human-Level QualityText-to-Speech에서 human-level quality를 판단하는 것은 어려움NaturalSpeechHuman-level quality를 달성하기 위해 variational auto-encoder를 활용한 end-to-end text-to-speech 모델Phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, VAE memory mechanism을 포함논문 (PAMI 2024) : Paper Link1. IntroductionText-to-Spee..
 [Paper 리뷰] ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
[Paper 리뷰] ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph ReadingText-to-Speech는 sentence에서는 우수한 성능을 보이고 있지만, paragraph/long-form reading에서는 어려움이 있음ContextSpeechGlobal text와 speech context를 sentence encoding에 incorporate 하는 memory-cached recurrence mechanism을 도입Hierarchically-structured textual semantics를 구성하여 global context enhancement의 scope를 향상추가적으로 linearized self-attention을 채택해 e..
 [Paper 리뷰] SALTTS: Leveraging Self-Supervised Speech Representations for Improved Text-to-Speech Synthesis
[Paper 리뷰] SALTTS: Leveraging Self-Supervised Speech Representations for Improved Text-to-Speech Synthesis
SALTTS: Leveraging Self-Supervised Speech Representations for Improved Text-to-Speech SynthesisText-to-Speech에서 richer representation을 반영하기 위해 Self-Supervised Learning model을 활용할 수 있음SALTTSSelf-Supervised Learning representation을 reconstruct 하기 위해 encoder layer를 통해 FastSpeech2 encoder의 length-regulated output을 전달함SALTTS-parallel에서 해당 encoder representation은 auxiliary reconstruction loss로 사용되고, S..
 [Paper 리뷰] Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder for High Fidelity Flow-based Speech Synthesis
[Paper 리뷰] Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder for High Fidelity Flow-based Speech Synthesis
Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder for High Fidelity Flow-based Speech SynthesisText-to-Speech 모델은 주로 mel-spectrogram과 같은 low-resolution intermediate representation에 의존하므로 vocoder와 acoustic model 간의 mismatch가 존재함Glow-WaveGANPre-designed intermediate representation에 의존하지 않고 GAN과 결합된 VAE를 사용하여 speech에서 latent representation을 직접 학습이후 flow-based aco..
 [Paper 리뷰] GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
[Paper 리뷰] GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
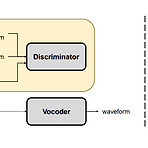
GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech SynthesisMulti-speaker text-to-speech 모델을 fine-tuning 하여 limited training data로 다양한 speaker의 음성을 합성할 수 있음- BUT, 여전히 real speech sample과 비교하여 합성 결과의 품질이 떨어짐GANSpeechNon-autoregressive Text-to-Speech 모델에 adversarial training을 적용추가적으로 adversarial training에서 사용되는 feature matching loss에 대한 automatic scaling method를 도입논문 (INTERSPEE..