

 [Paper 리뷰] MM-TTS: Multi-Modal Prompt Based Style Transfer for Expressive Text-to-Speech Synthesis
[Paper 리뷰] MM-TTS: Multi-Modal Prompt Based Style Transfer for Expressive Text-to-Speech Synthesis
MM-TTS: Multi-Modal Prompt Based Style Transfer for Expressive Text-to-Speech SynthesisText-to-Speech에서 style transfer는 style information을 text context에 반영하여 특정 style을 가진 음성을 생성하는 것을 목표로 함BUT, 기존의 style transfer 방식들은 fixed emotional label이나 reference clip에 의존하므로 flexible 한 style transfer의 한계가 있음MM-TTS생성되는 음성의 style을 control 하기 위해 reference speech, emotional facial image, text description 등을 포함하는..
 [Algorithm] 신장 트리 - 프림 / 크루스칼 알고리즘
[Algorithm] 신장 트리 - 프림 / 크루스칼 알고리즘
* Python을 기준으로 합니다 신장 트리 (Spanning Tree) - 프림 / 크루스칼 알고리즘 - 개념 신장 트리 : 모든 노드와 연결되어 있으면서 사이클이 존재하지 않는 부분 그래프 이때 간선 개수는 노드의 개수 보다 하나 적음 최소 신장 트리 (Minimum Spanning Tree, MST) : 가중치 합이 최소인 신장 트리 - 이때 구해지는 최소 신장 트리는 여러 개일 수 있음 최소 신장 트리 구하기 공통적으로 그리디 전략을 이용하고, $E$개의 노드 $V$개의 간선에 대해 $O(E \log V)$의 time complexity를 가짐 프림 알고리즘 (Prim Algorithm) 임의의 노드를 선택하여 최소 신장 트리에 추가 최소 신장 트리와 연결되어 있는 노드 중에서 가장 가중치가 작은..
 [Paper 리뷰] LangWave: Realistic Voice Generation based on High-Order Langevin Dynamics
[Paper 리뷰] LangWave: Realistic Voice Generation based on High-Order Langevin Dynamics
LangWave: Realistic Voice Generation based on High-Order Langevin DynamicsDiffusion model은 음성 생성에서 우수한 성능을 보이고 있지만 대부분 first-order stochastic differential equation이나 equivalent diffusion model에 의존함LangWave기존의 first-order method에서 벗어나 third-order Langevin dynamical system을 활용하여 waveform을 생성Ambient Euclidean space에서 voice wave diffusion, position, velocity, acceleration을 동시에 모델링하여 white noise에서 wa..
 [Paper 리뷰] SoundStream: An End-to-End Neural Audio Codec
[Paper 리뷰] SoundStream: An End-to-End Neural Audio Codec
SoundStream: An End-to-End Neural Audio CodecSpeech-tailored codec이 목표로 하는 bitrate로 음성, 음악, general audio를 효율적으로 compress 할 수 있도록 neural audio codec이 필요함SoundStreamFully-convolutional encoder/decoder와 residual vector quantizer로 구성된 architecture를 활용하여 end-to-end 방식으로 training 됨Training 시에는 adversarial loss와 reconstruction loss를 결합하여 quantized embedding에서 고품질 audio를 생성할 수 있도록 함Quantizer layer에 str..
 [Paper 리뷰] EnCodec: High-Fidelity Neural Audio Compression
[Paper 리뷰] EnCodec: High-Fidelity Neural Audio Compression
EnCodec: High Fidelity Neural Audio Compression Neural network를 사용하여 real-time, high-fidelity의 audio codec을 구성할 수 있음 EnCodec End-to-End 방식으로 학습된 quantized latent space를 가지는 streaming encoder-decoder architecture를 활용 Artifact를 줄이고 고품질의 sample을 합성하기 위해 multi-scale spectrogram adversary를 사용하여 training을 단순화하고 속도를 향상함 이때 training을 stabilize 할 수 있는 loss balancer mechanism을 도입 논문 (Meta AI 2022) : Paper..
 [Algorithm] 다이나믹 프로그래밍
[Algorithm] 다이나믹 프로그래밍
* Python을 기준으로 합니다 다이나믹 프로그래밍 (Dynamic Programming) - 개념 다이나믹 프로그래밍 (동적 계획법) : 전체 문제를 각각의 부분 문제로 나눈 다음 하나의 결과로 합쳐서 해결하는 방법 즉, 전체 문제를 부분 문제로 나누어 해결할 수 있어야 하고 동시에 중복되는 부분 문제가 존재하는 경우 사용 다이나믹 프로그래밍의 구현 메모이제이션 (Memoization) : 하향식 (Top-down) 방식 - 주어진 문제를 작은 부분 문제로 나누어 가면서 전체 문제를 해결하는 방식 - 재귀를 기반으로 이전 값들이 모두 계산되어 있다는 가정 하에 나머지 계산을 수행함 타뷸레이션 (Tabulation) : 상향식 (Bottom-up) 방식 - 작은 부분 문제부터 해결한 다음, 해당 과정을..
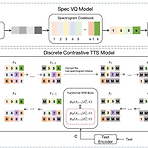 [Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
[Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation Text-to-Speech에서 latent diffusion model을 우수한 성능을 보이고 있지만, resource consumption이 크고 추론 속도가 느림 DCTTS Discrete diffusion model과 contrastive learning을 결합한 text-to-speech 모델 간단한 text encoder와 VQ model을 사용하여 raw data를 discrete space로 compress 한 다음, discrete space에서 diffusion model을 training 함 이때 diffusion step 수를 줄..
 [Algorithm] 그리디
[Algorithm] 그리디
* Python을 기준으로 합니다 그리디 (Greedy) - 개념 그리디 전략 : 각 단계에서 최적의 결과만을 선택하여 문제를 해결하는 방식 이전 선택이 이후 선택에 영향을 주지 않으면서, 부분 문제에 대한 해가 전체 문제의 최적 해로 구성되는 Greedy Choice Property를 가지는 최적 부분 구조 문제에 적용 가능 그리디 적용 가능 예시 : 다익스트라, 분할 가능 배낭 문제, 거스름돈 나누기, 회의실 배정 문제, 신장 트리 (프림, 크루스칼 알고리즘) 그리디를 적용할 수 없는 경우 : 0-1 배낭 문제, 외판원 순회, 이진 트리의 최적 합 경로 - 구현 1. 분할 가능 배낭 문제 무게 $w$와 가치 $v$인 $n$개의 물건들을 배낭에 넣을 때, 물건들의 가치의 합이 최대가 되도록 배낭을 채우..
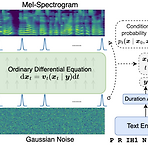 [Paper 리뷰] VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
[Paper 리뷰] VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching Text-to-Speech에서 diffusion model은 우수한 성능을 보이고 있지만 sampling complexity로 인해 비효율적임 VoiceFlow 제한된 sampling step으로도 고품질의 합성을 수행할 수 있는 rectified flow matching을 활용 Text input을 condition으로 하여 mel-spectrogram을 ordinary differential equation을 통해 추정 Rectified flow는 효율적인 합성을 위해 sampling trajectory를 straighten 함 논문 (ICASSP 2024) : Paper Link 1...