

티스토리 뷰
Paper/TTS
[Paper 리뷰] FillerSpeech: Towards Human-Like Text-to-Speech Synthesis with Filler Insertion and Filler Style Control
feVeRin 2025. 12. 15. 12:45반응형
FillerSpeech: Towards Human-Like Text-to-Speech Synthesis with Filler Insertion and Filler Style Control
- Human-like conversational speech synthesis를 위해서는 natural filler insertion이 가능해야 함
- FillerSpeech
- Filler style을 tokenize 하고 input text에 대한 cross-attention을 적용
- 추가적으로 natural filler insertion이 가능한 Large Language Model-based filler prediction을 도입
- 논문 (EMNLP 2025) : Paper Link
1. Introduction
- HierSpeech, VoiceCraft와 같은 최신 Text-to-Speech (TTS) model은 high-quality audio generation이 가능하지만, 여전히 human-like conversational speech를 생성하는 데는 한계가 있음
- 특히 'um', 'uh', 'well'과 같은 filler는 natural human conversation을 위한 필수 요소에 해당함
- Synthesized speech에서는 해당 filler가 missing 되는 경우가 많으므로 human-like naturalness를 달성하기 어려움 - 이를 해결하기 위해 기존에는 filler에 대한 separate acoustic model을 활용하거나 filler insertion을 위한 sampling-based approach를 활용함
- BUT, 해당 방식은 textual context에 대한 coherence가 떨어지고 text-based control이 어렵다는 한계가 있음
- 특히 'um', 'uh', 'well'과 같은 filler는 natural human conversation을 위한 필수 요소에 해당함
-> 그래서 더 나은 filler insertion과 filler style control이 가능한 FillerSpeech를 제안
- FillerSpeech
- Controllable filler style을 위해 filler style attribute를 tokenize 하고 해당 word-level style token을 incorporate 하는 cross-attention을 적용
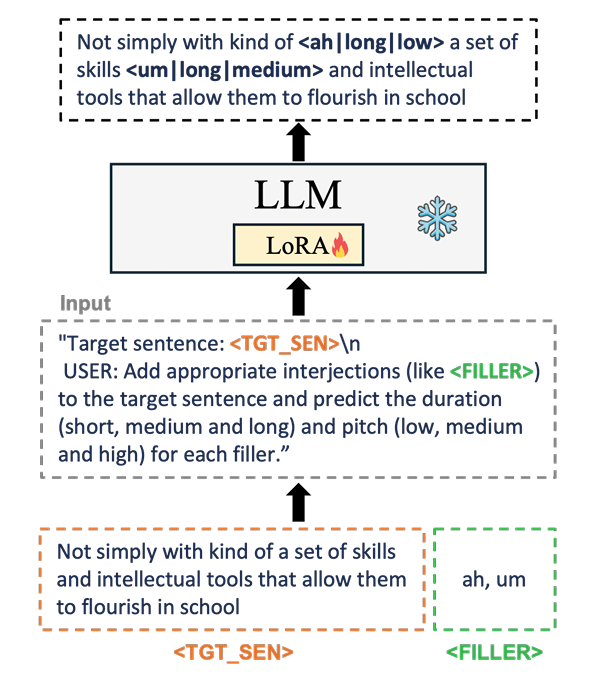
- 추가적으로 text encoder에 pitch predictor를 integrate하고 filler selection을 위한 Large Language Model (LLM)-based filler prediction을 도입
< Overall of FillerSpeech >
- Filler token과 LLM-based prediction을 활용한 Filler-controllable TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- FillerSpeech는 filler style token과 pitch predictor, cross-attention을 활용하여 synthesized speech의 speaking style을 modulate 함
- 추가적으로 논문은 LLM을 fine-tuning 하여 filler insertion과 해당 style attribute를 predict 함
- Tokenization of Filler
- 논문은 각 filler word를 indivisible token으로 처리하지 않고 filler에 대한 phoneme-based tokenization을 활용함
- Distinct filler word 수는 phoneme 수 보다 훨씬 적으므로 phoneme-level tokenization을 활용하면 filler를 regular word와 smoothly integrate 할 수 있음
- 특히 filler style을 위해 pitch, duration를 discrete label을 통해 tokenize 함
- Pitch, duration이 부족한 regular word는 null label에 assign 됨
- 추가적으로 pitch는 speaker gender와 strongly correlate 되어 있으므로 gender에 따라 pitch label을 further tokenize 함

- Filler Style Control
- Encoder를 phoneme-level에서 filler의 pitch에 condition 하기 위해, 논문은 pitch token을 embedding 하고 phoneme-level resolution에 대해 expand 한 다음, text의 phoneme embedding과 concatenate 함
- 이때 encoder는 synthesized speech에 filler를 further integrate 하기 위해 phoneme-level text representation과 word-level pitch embedding 간의 cross-attention을 compute 함
- Duration control을 위해 논문은 duration token을 embed 하고 text representation과 함께 duration predictor input으로 사용함
- 더 나은 filler style control을 위해 training 중에 dedicated pitch predictor를 통해 text representation으로부터 pitch value를 estimate 함
- 해당 explicit pitch modeling을 기반으로 text encoder는 natural filler generation과 effective style control을 위한 prosodic characteristic을 capture 할 수 있음
- Prior Loss for Filler Representation
- 논문은 encoder output과 target mel-spectrogram 간의 prior loss를 compute 함
- 이때 filler는 text에서 small fraction 만을 차지하고 style token은 filler-containing segment에서만 exclusively appear 하므로 sampling을 적용하면 해당 filler를 exclude 할 수 있음
- 따라서 FillerSpeech는 encoder output을 sampling 하지 않고 모든 encoder output을 사용함 - Prior loss를 compute 한 다음에는 training efficiency를 위해 encoder output의 subset을 sampling 함
- 이때 filler는 text에서 small fraction 만을 차지하고 style token은 filler-containing segment에서만 exclusively appear 하므로 sampling을 적용하면 해당 filler를 exclude 할 수 있음
- Flow Matching Decoder
- FillerSpeech의 decoder는 flow matching framework를 기반으로 구축됨
- 여기서 flow matching은 simple prior distribution $p_{0}$와 complex data distribution $q(x)$를 connect 하는 probabiltiy path를 modeling 함
- 즉, time $t$에 따라 sample의 transformation을 govern 하는 vector field $v_{t}(x)$를 define 함:
(Eq. 1) $ \frac{d}{dt}\phi_{t}(x)=v_{t}(\phi_{t}(x));\,\,\,\phi_{0}(x)=x$
- $\phi_{t}(x)$ : prior distribution에서 target distribution으로의 sample trajectory - Optimal Transport Conditional Flow Matching (OT-CFM)에서 training objective는 predicted vector field $v_{t}(x)$와 ideal vector field $u_{t}(x)$ 간의 difference를 minimize 하는 것과 같음:
(Eq. 2) $\mathcal{L}(\theta)=\mathbb{E}_{t,x_{0},x_{1}}\left|\left|u_{t}^{OT}\left( \phi_{t}^{OT}(x)|x_{1}\right)-v_{t}\left(\phi_{t}^{OT}(x)|\mu;\theta\right)\right|\right|^{2}$
- (Eq. 2)는 decoder가 latent noise에서 mel-spectrogram으로의 smooth transformation을 학습하도록 함
- 특히 trajectory에 대해 linearly change 하는 vector field $u_{t}(x)$는 synthesis step을 크게 줄일 수 있음
- LLM-based Filler Prediction
- Input text를 기반으로 natural filler를 insert 하기 위해 LLM-based filler prediction module을 도입함
- 이때 LLM의 catastrophic forgetting을 mitigate 하기 위해 LoRA를 사용하여 LLM을 fine-tuning 함
- 먼저 single model이 다양한 filler prediction scenario를 handle 할 수 있도록 다양한 specification level을 가진 instruction prompt를 구성함
- 해당 prompt는 filler type이 specify 된 경우, filler type과 position이 모두 주어진 경우, potential filler candidate가 주어진 경우, filler position만 specify 된 경우를 포함함
- 각 scenario에서 filler prediction model은 duration, pitch, 제공되지 않은 type과 같은 remaining characteristic을 predict 하도록 training 됨
- LLM은 TTS model과 separately training 되고, 추론 시에는 필요에 따라 LLM-based filler prediction을 활용할 수 있음
3. Experiments
- Settings
- Dataset : LibriHeavy
- Comparisons : Matcha-TTS
- Results
- 전체적으로 FillerSpeech의 성능이 가장 우수함

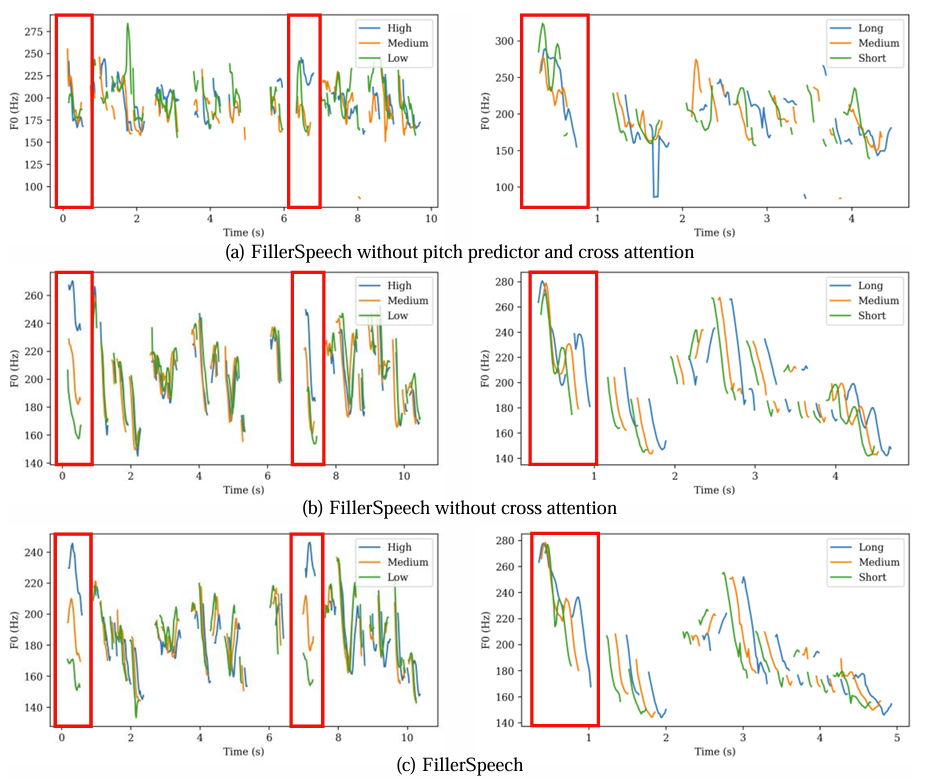
- Filler Style Control
- FillerSpeech는 뛰어난 pitch control이 가능함
- LLM-based Filler Prediction
- Vicuna-7B+LoRA 조합을 사용했을 때 최고의 filler prediction이 가능함

- Naturalness 측면에서도 Vicuna-7B가 가장 우수함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글