

티스토리 뷰
Paper/TTS
[Paper 리뷰] Word-Level Emotional Expression Control in Zero-Shot Text-to-Speech Synthesis
feVeRin 2025. 11. 14. 13:45반응형
Word-Level Emotional Expression Control in Zero-Shot Text-to-Speech Synthesis
- 대부분의 emotional Text-to-Speech는 word-level control이 어려움
- WeSCon
- Pre-trained zero-shot Text-to-Speech model로부터 emotion, speaking rate를 control 하는 self-training framework
- Word-level expressive synthesis를 guide 하기 위한 transition-smoothing strategy, dynamic speed control mechanism을 도입
- 추론 시에는 dynamic emotional attention bias mechanism을 incorporate
- 논문 (NeurIPS 2025) : Paper Link
1. Introduction
- Text-to-Speech (TTS) model은 timbre, emotion, speaking rate 등을 control 할 수 있어야 함
- SPEAR-TTS, VALL-E, NaturalSpeech3와 같은 zero-shot TTS model은 reference speech sample에서 timbre, emotion, speaking rate 등을 cloning 함
- BUT, 해당 model에서 emotional, speaking rate control은 utterance-level로 제한됨 - 특히 emotional expression과 speaking rate는 single sentence 내에서도 dynamic 하게 나타나므로, natural, expressive synthesis를 위해서는 word-level control이 필요함
- BUT, word-level control을 위해서는 다음의 한계점을 고려해야 함:
- Word-level expression control은 multiple emotional speech prompt를 필요로 함
- Fine-grained expression control을 위해서는 time-aligned emotion transition을 가진 large-scale emotional speech dataset이 필요함
- SPEAR-TTS, VALL-E, NaturalSpeech3와 같은 zero-shot TTS model은 reference speech sample에서 timbre, emotion, speaking rate 등을 cloning 함
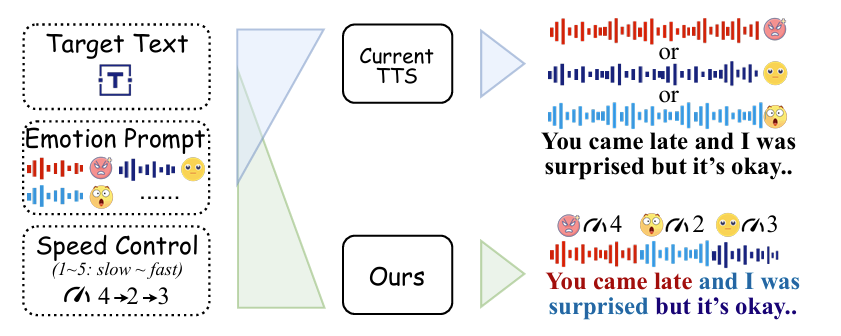
-> 그래서 speech dataset에 대한 의존성 없이 효과적인 word-level control을 제공할 수 있는 WeSCon을 제안
- WeSCon
- Two-stage self-training framework를 활용해 small speech data 만으로도 emotion control을 지원
- First stage에서는 transition-smoothing module과 dynamic speed control mechanism을 incorporate 한 multi-round inference framework를 구축
- Second stage에서는 original TTS model을 student로 repurpose 하고 first-stage teacher의 supervision 하에서 training을 수행
< Overall of WeSCon >
- Multi-round inference mechanism과 self-training framework를 활용한 word-level emotion control method
- 결과적으로 기존보다 더 나은 controllability를 달성
2. Method
- Overview
- WeSCon은 small emotional speech data를 만으로도 pre-trained zero-shot TTS model에서 word-level control을 지원하기 위해 two-stage self-training framework를 활용함
- First stage에서는 transition-smoothing과 dynamic speaking rate control을 포함한 multi-round inference를 도입해 word-level expression variation을 가진 speech를 생성함
- Second stage에서는 first-stage model을 teacher로 사용하여 Dynamic Emotional Attention Bias (DEAB)가 적용된 original TTS model을 guide 함
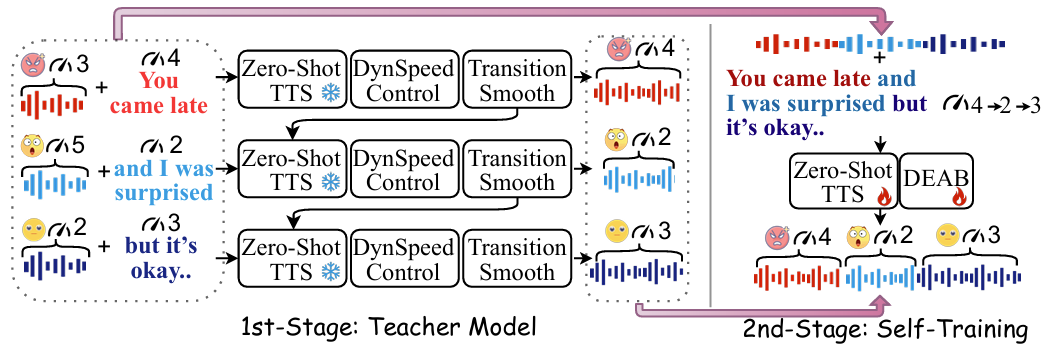
- Teacher Model
- Word-Level Emotion Control
- 논문은 TTS backbone으로 CosyVoice2를 채택하고, model의 word-level emotion control을 위해 Multi-Round Inference strategy를 도입함
- BUT, 해당 방식은 segment boundary에서 unnatural acoustic discontinuity가 발생할 수 있음 - 따라서 논문은 inference round 간의 coherence를 향상하기 위해, non-causal Transformer와 convolutional layer로 구성된 lightweight content aligner를 도입하여 Transition-Smoothing mechanism을 구축함
- 이때 aligner는 Automatic Speech Recognition (ASR) data로 training 되어 emotional supervision 없이 각 speech token에 대응하는 text token을 predict 함 - 추론 시 input text는 user-defined emotion plan에 따라 segment 됨
- 각 inference round에서 previous round의 final text와 speech token은 current prompt에 append 되어 explicit tail-to-head linkage를 구성함
- 결과적으로 이는 CosyVoice2의 continuation-style generation과 natually align 되어 smooth, coherent emotional transition을 지원함
- 논문은 TTS backbone으로 CosyVoice2를 채택하고, model의 word-level emotion control을 위해 Multi-Round Inference strategy를 도입함
- Word-Level Speaking Rate Control
- 논문은 single utterance 내에서 speaking rate를 word-level로 control 하기 위해 추가적으로 Dynamic Speed Control mechanism을 도입함
- Dynamic speed control은 nearest-neighbor interpolation이나 downsampling을 활용하여 prompt speech token을 adjust 하는 것을 목표로 함
- 여기서 interpolation은 prompt length를 extend 하여 generated speech를 slow down 하고 downsampling은 prompt를 shorten 하여 speaking rate를 빠르게 함
- 결과적으로 해당 dynamic speed control을 multi-round inference process에 integrate 함으로써 speaking rate를 word-level에 따라 dynamically control 할 수 있음
- Speaker Consistency
- CosyVoice2의 Language Model (LM)에서 speech token은 주로 semantic information을 encoding 하지만, 해당 speech token은 여전히 speaker-related information을 leak 할 수 있음
- 한편으로 flow matching은 generated speech token을 specified target speaker voice로 변환함
- 즉, LM에서 multi-round inference process 동안 speaker-inconsistency를 avoid 할 수 있다면 flow matching의 final output에서도 speaker-consistency를 보장할 수 있음
- 따라서 논문은 Speaker-Aware Prompt Selection strategy를 채택하여 multi-round inference 중에 same speaker의 서로 다른 emotional prompt를 select 함
- 이후 target speaker의 reference sample을 randomly select 하여 flow matching에 speaker identity를 제공함
- CosyVoice2의 Language Model (LM)에서 speech token은 주로 semantic information을 encoding 하지만, 해당 speech token은 여전히 speaker-related information을 leak 할 수 있음

- Self-Training
- 앞선 multi-round inference framework를 통해 word-level control을 수행할 수 있지만, non-causal content aligner, multi-round inference, tail-to-head linkage로 인한 complexity가 존재함
- 따라서 controllability를 유지하면서 해당 overhead를 줄이기 위해, Self-Training strategy를 도입함
- 이때 first-stage model은 original TTS model을 supervise 하는 teacher로 사용되고, Dynamic Emotional Attention Bias (DEAB)를 가지는 student model은 end-to-end inference를 통해 word-level control을 학습함
- Self-Training with Teacher-Generated Emotion-Transition Speech
- 논문은 teacher model의 fine-grained controllability를 end-to-end model로 transfer 하기 위해 Self-Training strategy를 활용함
- 특히 first-stage teacher model은 student model이 word-level controllability를 학습하도록 함
- 먼저 GPT-4o를 사용하여 emotion-transition text sequence를 생성하고, public emotional speech와 pair 함
- 이후 teacher는 word-level variation을 가지는 emotion, speaking rate를 기반으로 speech를 생성함
- 해당 output은 expressive similarity, character accuracy에 따라 filtering 되고 student model은 small learning rate로 filtering 된 supervision에 대해 fine-tuning 됨
- Dynmaic Emotional Attention Bias (DEAB)
- Input structure를 $\{Ⓢ, \mathbf{C}^{prompt\,\text{I}},\mathbf{C}^{prompt\,\text{II}},...,\mathbf{C}^{tgt},Ⓑ, \mathbf{S}^{prompt \,\text{I}},\mathbf{S}^{prompt\,\text{II}},...,\mathbf{S}^{tgt}\}$이라고 하자
- $\mathbf{C}^{prompt\, \text{i}},\mathbf{S}^{prompt\,\text{i}}$ : 각각 $i$-th emotional prompt의 text/speech token
- $\mathbf{C}^{tgt}$ : target text token sequence, $\mathbf{S}^{tgt}$ : supervision으로 사용되는 speech token sequence
- Ⓢ, Ⓑ : text, speech의 beginning - 해당 structure는 CosyVoice2의 original input format $\{Ⓢ,\mathbf{C}, Ⓑ,\mathbf{S}\}$와 fully compatible 하고, pre-trained model의 autoregressive pattern을 preserving 함
- 해당 unified format 내에서 word-level emotional variation을 further encode 하기 위해, 논문은 emotional segment의 boundary를 mark 하는 explicit emotion indicator token을 insert 하여 text-side input을 extend 함
- 그러면 Ⓑ 앞의 final input sequence는 $\{Ⓢ,E^{\text{I}},\mathbf{C}^{prompt \,\text{I}},E^{\text{II}},\mathbf{C}^{prompt\,\text{II}},...\}$가 됨
- $E^{i}$ : generation 시 model이 emotion transition을 modulate 하도록 guide 하는 soft anchor
- 앞선 data formatting은 CosyVoice2와의 generalization을 preserve 할 수 있지만 synthesis 중에 model이 emotion-inconsistent prompt에 incorrectly attend 할 수 있다는 문제점이 있음
- 이를 해결하기 위해 논문은 predicted emotional trajectory를 기반으로 model을 emotion-relevant prompt region으로 focus 하는 Dynamic Attention Bias mechanism을 도입함
- 특히 historical context에서 각 speech token $\mathbf{S}^{tgt}_{t}$에 대해 token-level emotion label $E_{t}^{tgt}$을 predict 하는 causal lightweight Transformer를 활용함
- 이후 predicted emotion sequence를 사용하여 각 Transformer layer에서 Dynamic Attention Bias mechanism을 적용함
- 먼저 text-speech representation을 predicted emotion feature와 concatenate 하고 linear layer를 통해 project 함
- 이때 output에서 하나의 path는 residual을 add 하여 next layer로 feed 하고, other path는 MLP, softmax를 통과하여 weight vector $\omega \in\mathbb{R}^{1\times 7}$을 생성함
- 이후 $\omega$는 7개의 pre-defined attention bias template $\mathbf{B}^{temp}\in\mathbb{R}^{7\times T\times T}$과 linearly combine 되어 dynamic attention bias를 compute 함
- 결과적으로 bias는 다음과 같이 얻어짐:
(Eq. 1) $ \mathbf{B}^{bias}=\sum_{i=0}^{6}\omega_{i}\cdot \mathbf{B}_{i}^{temp}$
- 그러면 bias를 softmax-normalized attention과 multiply 하여 current emotional context와 align 되는 region을 selectively emphasis 할 수 있음
- 이때 final self-attention output은:
(Eq. 2) $\mathbf{O}=\left(\frac{\text{Softmax}\left(\frac{\mathbf{QK}^{\top}}{\sqrt{d}}\right)\odot \mathbf{B}^{bias}}{\sum_{j=1}^{T}\left[ \text{Softmax}\left(\frac{\mathbf{QK}^{\top}}{\sqrt{d}}\right)\odot \mathbf{B}^{bias}\right]}_{:,j}\right)\mathbf{V}$
- $\mathbf{Q},\mathbf{K},\mathbf{V}\in\mathbb{R}^{H\times T\times d}$ : multi-head $H$ query/key/value
- $d$ : attention head dimension, $\odot$ : element-wise multiplication - 이를 통해 model은 각 generation step에서 emotionally-relevant prompt segment에 dynamically focus 할 수 있고, generation과 intended emotional trajectory 간의 alignment를 향상할 수 있음
- 이때 final self-attention output은:
- Input structure를 $\{Ⓢ, \mathbf{C}^{prompt\,\text{I}},\mathbf{C}^{prompt\,\text{II}},...,\mathbf{C}^{tgt},Ⓑ, \mathbf{S}^{prompt \,\text{I}},\mathbf{S}^{prompt\,\text{II}},...,\mathbf{S}^{tgt}\}$이라고 하자
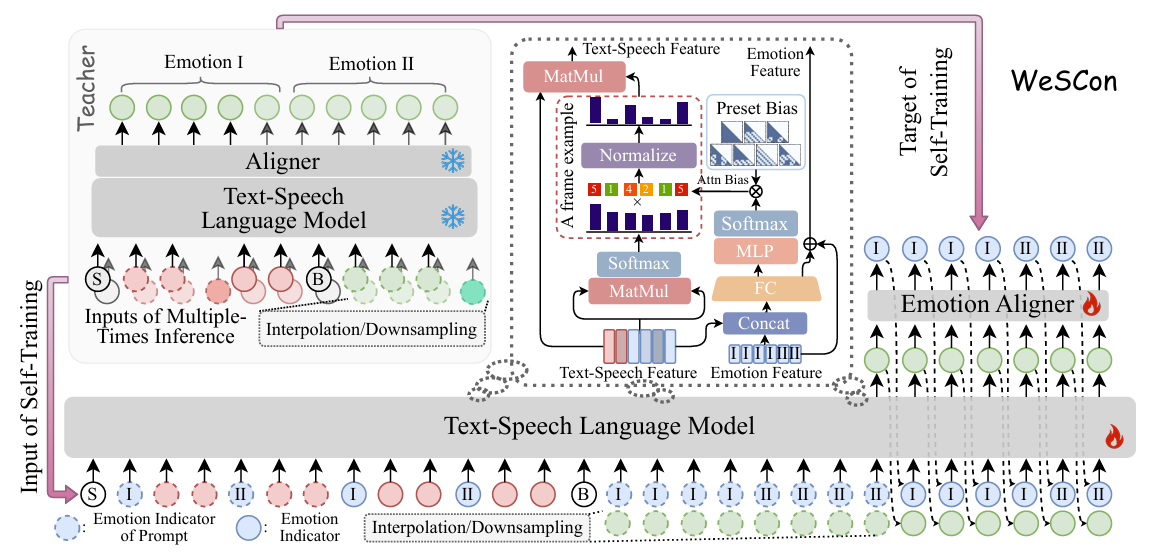
- Training Setup
- WeSCon은 two-stage training을 채택함
- First stage에서는 smooth transition을 보장하기 위해 content aligner를 training 하고, second stage에서는 self-training strategy를 활용하여 teacher model의 ability를 original TTS model로 transfer 함 - First Stage (Teacher Model)
- 논문은 forced alignment를 사용하여 transcript와 speech 간의 token-level alignment를 생성하고 content aligner의 supervision으로 사용함
- 이때 TTS model은 freeze 됨 - Input text와 speech token sequence를 각각 $\mathbf{C},\mathbf{S}$, 각 label이 하나의 $V_{1}$ token class에 해당하는 aligned target token sequence를 $\mathbf{Y}^{token}\in\mathbb{N}^{T}$라고 하자
- $\mathbf{Y}^{bd}\in\mathbb{R}^{T\times 1}$을 content boundary detection을 위한 binary label sequence라고 하면
- Content aligner는 token-level content classification loss와 binary boundary detection loss로 jointly training 됨:
(Eq. 3) $\mathcal{L}_{aligner}=-\sum_{t=T^{C}}^{T^{S}-1}\log p\left(Y_{t}^{token}| Ⓢ, \mathbf{C}, Ⓑ,\mathbf{S};\theta^{tts},\theta^{ca}\right)-\log p\left(Y_{t}^{bd}|Ⓢ,\mathbf{C},Ⓑ,\mathbf{S};\theta^{tts},\theta^{ca}\right)$
- $T^{C}, T^{S}$ : 각각 text, speech의 last frame index, $T=T^{S}-T^{C}$ : total speech token 수
- $\theta^{ca}$ : content aligner의 learnable parameter, $\theta^{tts}$ : frozen TTS model parameter - 추가적으로 loss computation 시 class weighting을 적용하여 over-represented silence token의 impact를 줄이고 boundary label distribution의 imbalance를 해결함
- 논문은 forced alignment를 사용하여 transcript와 speech 간의 token-level alignment를 생성하고 content aligner의 supervision으로 사용함
- Second Stage (Self-Training)
- Teacher model은 emotion label을 가진 GPT-4o-generated text를 사용한 multi-round inference를 통해 supervision을 생성함
- 여기서 token-level emotion label은 emotion-text correspondence에 따라 align 됨 - Student model은 다음 2가지 objective를 통해 optimize 됨
- Speech token prediction을 위한 negative log-likelihood:
(Eq. 4) $\mathcal{L}_{tts}=-\sum_{t=T^{prompt}}^{T^{tgt}-1}\log p\left(\mathbf{S}^{tgt}_{t}|Ⓢ,\mathbf{C}^{prompt},\mathbf{C}^{tgt},\mathbf{E}^{text},Ⓑ, \mathbf{E}^{speech}_{<t}, \mathbf{S}^{prompt},\mathbf{S}^{tgt}_{<t};\theta^{tts},\theta^{ea}\right)$
- $\mathbf{C},\mathbf{S}$ : 각각 text, speech token, $\mathbf{E}$ : text-level/token-level emotion label
- $\theta^{tts}, \theta^{ea}$ : 각각 TTS model, emotion aligner parameter - Emotion prediction을 위한 token-level cross-entropy loss:
(Eq. 5) $ \mathcal{L}_{e}=-\sum_{t=T^{prompt}}^{T^{tgt}-1}\log p\left(E_{t}^{tgt}|Ⓢ,\mathbf{C}^{prompt}, \mathbf{C}^{tgt},\mathbf{E}^{text}, Ⓑ,\mathbf{E}_{<t}^{speech}, \mathbf{S}^{prompt},\mathbf{S}_{<t}^{tgt};\theta^{tts},\theta^{ea}\right)$
- Speech token prediction을 위한 negative log-likelihood:
- Teacher model은 emotion label을 가진 GPT-4o-generated text를 사용한 multi-round inference를 통해 supervision을 생성함
3. Experiments
- Settings
- Dataset : LibriSpeech, AISHELL, ESD
- Comparisons : F5-TTS, CosyVoice2, Spark-TTS, Index-TTS
- Results
- 전체적으로 WeSCon의 성능이 가장 우수함

- MOS 측면에서도 뛰어난 성능을 보임
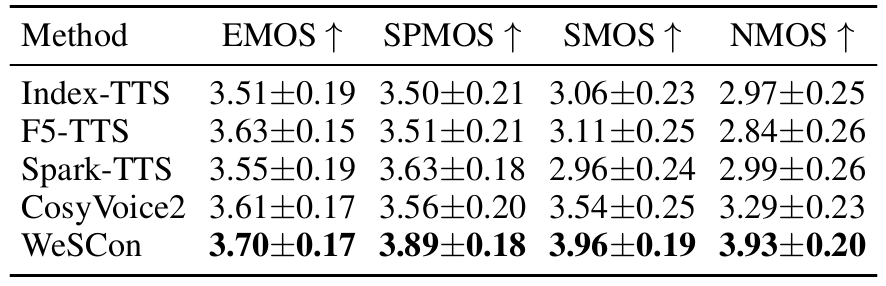
- Zero-Shot TTS에서도 큰 성능 저하를 보이지 않음
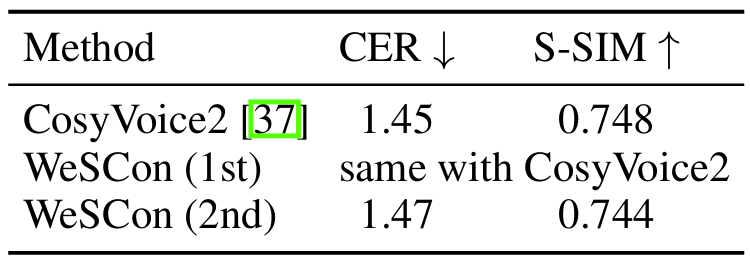
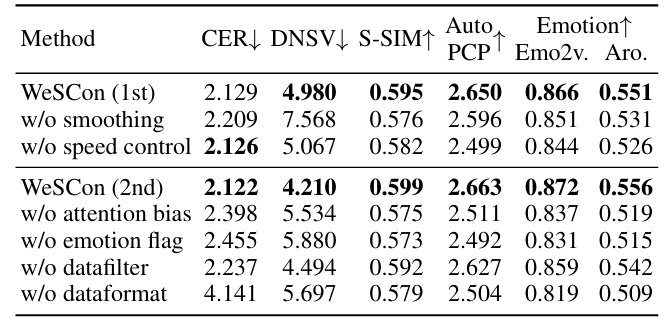
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
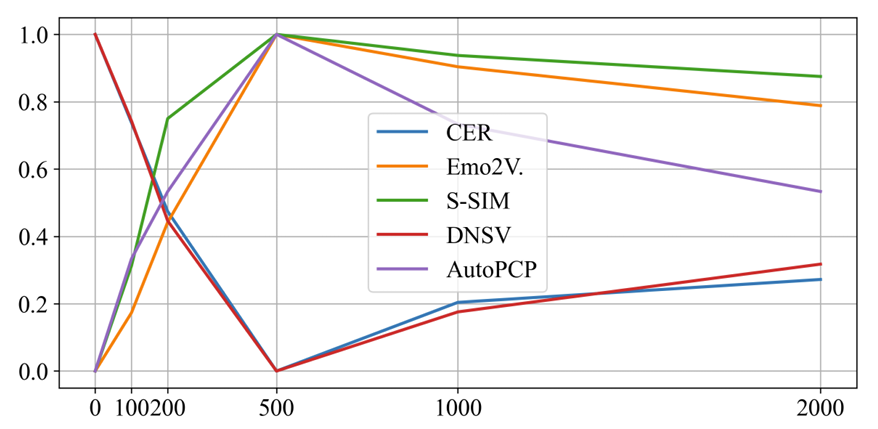
- 500 hours의 self-training dataset을 사용하는 경우 최적의 성능을 달성함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글