

티스토리 뷰
Paper/Verification
[Paper 리뷰] CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
feVeRin 2025. 9. 11. 17:01반응형
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
- ECAPA-TDNN은 high complexity와 slow inference speed의 문제가 있음
- CAM++
- Context-Aware Masking을 densely-connected Time Delay Neural Network backbone에 적용
- Multi-granularity pooling을 적용하여 서로 다른 level의 textual information을 capture
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Speaker Verification (SV)는 voice characteristic을 기반으로 hypothesized speaker가 pronounce 한 utterance인지를 automatically verify 함
- 이때 SV system은 utterance를 fixed-dimensional speaker embedding으로 transform 하는 embedding extractor와 embedding 간의 similarity score를 calculate 하는 back-end model로 구성됨
- 특히 ECAPA-TDNN은 Time Delay Neural Network (TDNN)에서 1D-Res2Block과 Squeeze-Excitation을 unify 하고 2D-ResNet element를 incorporate 하여 SV 성능을 크게 개선함
- BUT, ECAPA-TDNN은 상당한 parameter 수와 computation을 요구함
- 한편 speaker에 focus 하고 unrelated noise는 blurring 하는 Context-Aware Masking (CAM)을 활용하면 적은 computation cost로도 SV 성능을 향상할 수 있음
-> 그래서 efficient speaker embedding learning을 위해 CAM을 확장한 CAM++를 제안
- CAM++
- Lighter CAM module을 Densely-connected TDNN (D-TDNN)에 insert 하여 speaker focusing을 향상
- Multi-granularity pooling을 활용하여 global/segment level에서 contextual information을 capture
- Narrow-deep network를 구성하고 input feature의 frequency shift에 대한 invariant를 향상하기 위해 2D-convolution module을 incorporate
< Overall of CAM++ >
- CAM을 확장하여 D-TDNN에 결합한 efficient, fast SV model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overview
- CAM++는 Front-end Convolution Module (CFM)과 D-TDNN backbone으로 구성됨
- FCM은 multiple block의 residual connection을 포함한 2D-convolution으로 구성됨
- 이를 통해 time-frequency domain에서 acoustic feature를 encoding 하고 high-resolution time-frequency detail을 반영함
- Resulting feature map은 channel, frequency dimension에 따라 flatten 되어 D-TDNN input으로 사용됨
- D-TDNN backbone은 D-TDNN layer의 sequence를 포함하는 3개의 block으로 구성됨
- 각 D-TDNN layer에는 inner TDNN layer의 output feature에 서로 다른 attention weight를 assign 하는 improved CAM module을 적용함
- Multi-granularity pooling은 global average pooling과 segment average pooling을 incorporate 하여 서로 다른 level의 contextual information을 aggregate 함
- Masked output은 dense connection을 통해 preceding layer와 concatenate 되고 next layer의 input으로 사용됨
- FCM은 multiple block의 residual connection을 포함한 2D-convolution으로 구성됨

- D-TDNN Backbone
- TDNN은 time-axis를 따라 dilated 1D-convolution structure를 backbone으로 사용함
- 한편으로 D-TDNN은 DenseNet과 같이 모든 layer 간의 direct connection을 포함하는 dense connectivity를 활용하여 TDNN을 개선함
- 결과적으로 D-TDNN은 기존 TDNN 보다 더 적은 parameter와 더 나은 SV 성능을 가지므로, 논문은 D-TDNN을 backbone으로 채택함 - D-TDNN의 basic unit은 Feed-Forward Network (FFN)과 TDNN layer로 구성됨
- 먼저 2개의 consecutive D-TDNN layer의 input 사이에 direct connection이 적용됨
- 이때 $l$-th D-TDNN layer의 formulation은:
(Eq. 1) $\mathbf{S}^{l}=\mathcal{H}_{l}\left(\left[\mathbf{S}^{0},\mathbf{S}^{1},...,\mathbf{S}^{l-1}\right]\right)$
- $\mathbf{S}^{0}$ : D-TDNN block input, $\mathbf{S}^{l}$ : $l$-th D-TDNN layer output
- $\mathcal{H}_{l}$ : $l$-th D-TDNN layer의 non-linear transformation
- D-TDNN은 기존 TDNN 보다는 우수한 성능을 보이지만 ECAPA-TDNN과는 상당한 차이가 있음
- 이때 deeper network는 wider network보다 SV task에서 더 나은 성능을 보임 - 따라서 논문은 D-TDNN network의 depth를 증가시키면서 각 layer의 filter channel size를 줄여 network complexity를 control 함
- 구조적으로 기존 D-TDNN은 각각 6, 12개의 D-TDNN layer를 포함하는 2개의 block으로 구성됨
- 반면 논문은 end에 additional block을 추가하고 block 당 layer 수를 12, 24, 16으로 expand 함 - 이때 network complexity를 줄이기 위해 각 block에서 narrower D-TDNN layer를 채택하고 growth rate $k$를 64에서 32로 줄임
- 추가적으로 D-TDNN backbone 이전에 $1/2$ sampling rate를 가진 input TDNN layer를 도입함
- 구조적으로 기존 D-TDNN은 각각 6, 12개의 D-TDNN layer를 포함하는 2개의 block으로 구성됨
- 한편으로 D-TDNN은 DenseNet과 같이 모든 layer 간의 direct connection을 포함하는 dense connectivity를 활용하여 TDNN을 개선함
- Context-Aware Masking
- Attention-based Context-Aware Masking (CAM) module은 D-TDNN의 성능을 크게 개선할 수 있음
- 특히 CAM은 global statistics pooling을 통해 얻은 auxiliary utterance-level embedding을 사용하여 feature map masking을 수행함
- BUT, CAM은 각 D-TDNN block 이후의 transition layer에서만 적용되므로 critical information을 추출하는데 insufficient 함 - 따라서 논문은 lighter CAM을 각 D-TDNN layer에 insert 하여 interset speaker를 capture 함
- D-TDNN block의 head FFN에 대한 output hidden feature를 $\mathbf{X}$라고 하자
- 먼저 $\mathbf{X}$는 TDNN layer에 input 되어 local temporal feature $\mathbf{F}$를 추출함:
(Eq. 2) $\mathbf{F}=\mathcal{F}(\mathbf{X})$
- $\mathcal{F}(\cdot)$ : TDNN layer의 transformation
- 이때 $\mathcal{F}(\cdot)$은 local receptive field에만 focus 하므로 suboptimal 할 수 있음 - 이후 추출된 contextual embedding $\mathbf{e}$를 기반으로 ratio mask $\mathbf{M}$이 predict 되어 interest speaker와 noise characteristic을 contain 함:
(Eq. 3) $\mathbf{M}_{*t}=\sigma \left(\mathbf{W}_{2}\delta\left(\mathbf{W}_{1}\mathbf{e}+\mathbf{b}_{1}\right)+\mathbf{b}_{2}\right)$
- $\sigma(\cdot)$ : Sigmoid function, $\delta(\cdot)$ : ReLU function, $\mathbf{M}_{*t}$ : $\mathbf{M}$의 $t$-th frame
- CAM에서는 global statistics pooling을 사용하여 contextual embedding $\mathbf{e}$를 생성함
- Speech signal의 certain segment에는 target speaker의 unique speaking manner가 존재할 수 있음
- 즉, global pooling에서 single embedding을 사용하면 precise local contextual information을 loss 할 수 있으므로 suboptimal masking으로 이어짐
- 따라서 single global pooling을 multi-granularity pooling으로 extend 하는 것이 필요함 - 이를 위해 논문은 global average pooling을 사용하여 global-level에서 contextual information을 추출함:
(Eq. 4) $\mathbf{e}_{g}=\frac{1}{T}\sum_{t=1}^{T}\mathbf{X}_{*t}$ - Segment average pooling은 segment-level에서 contextual information을 추출하기 위해 사용됨:
(Eq. 5) $\mathbf{e}_{s}^{k}=\frac{1}{\mathbf{s}_{k+1}-s_{k}} \sum_{t=s_{k}}^{s_{k+1}-1}\mathbf{X}_{*t}$
- $\mathbf{s}_{k}$ : feature $\mathbf{X}$에서 $k$-th segment의 starting frame - 다음으로 서로 다른 level의 contextual embedding, $\mathbf{e}_{g},\mathbf{e}_{s}$가 aggregate 되어 context-aware mask $\mathbf{M}$을 predict 함:
(Eq. 6) $ \mathbf{M}_{*t}^{k}=\sigma\left(\mathbf{W}_{2}\delta\left(\mathbf{W}_{1}\left(\mathbf{e}_{g} +\mathbf{e}_{s}^{k}\right)+\mathbf{b}_{1}\right)+\mathbf{b}_{2}\right),\,\,\, s_{k}\leq t< s_{k+1}$ - 최종적으로 predicted $\mathbf{M}$은 representation을 calibrate 하고 refined representation $\tilde{\mathbf{F}}$를 생성하는 데 사용됨:
(Eq. 7) $\tilde{\mathbf{F}}=\mathcal{F}(\mathbf{X})\odot \mathbf{M}$
- $\odot$ : element-wise multiplication
- Speech signal의 certain segment에는 target speaker의 unique speaking manner가 존재할 수 있음
- (Eq. 6)은 기존 CAM과 비교하여 simpler form과 fewer trainable parameter를 가짐
- 결과적으로 CAM++는 해당 context-aware masking을 D-TDNN layer에 insert 하여 representation power를 향상함
- 특히 CAM은 global statistics pooling을 통해 얻은 auxiliary utterance-level embedding을 사용하여 feature map masking을 수행함
- Front-End Convolution Module
- TDNN-based network는 input feature의 complete frequency range를 cover 하는 kernel을 사용하여 time-axis를 따라 1D-convolution을 수행함
- 이때 full frequency range의 complex detail을 modeling 하기 위해서는 많은 filter가 필요함
- 대표적으로 ECAPA-TDNN은 convolution layer에서 1024개의 channel을 가짐
- 이때 D-TDNN block 마다 narrower layer를 사용하면 parameter size를 줄일 수 있지만, specific frequency pattern을 capture 하는 ability가 저하될 수 있음 - 따라서 time-frequency domain에서 reasonable shift에 대한 D-TDNN의 robustness를 향상하고 intra-speaker pronunciation variability를 compensate 하는 것이 필요함
- 대표적으로 ECAPA-TDNN은 convolution layer에서 1024개의 channel을 가짐
- 이를 위해 논문은 D-TDNN network에 2D-Front-end Convolution Module (FCM)을 도입함
- 특히 FCM stem에 4개의 residual block을 incorporate 하고 channel 수를 32로 설정함
- 마지막 3-block에서는 frequency dimension의 stride를 2로 설정하여 $8\times $ downsampling을 수행함
- 결과적으로 FCM output feature map은 channel/frequency dimension에 따라 flatten 되고 D-TDNN backbone input으로 사용됨
- 이때 full frequency range의 complex detail을 modeling 하기 위해서는 많은 filter가 필요함
3. Experiments
- Settings
- Dataset : VoxCeleb, CN-Celeb
- Comparisons : TDNN, ECAPA-TDNN
- Results
- 전체적으로 CAM++의 성능이 가장 우수함
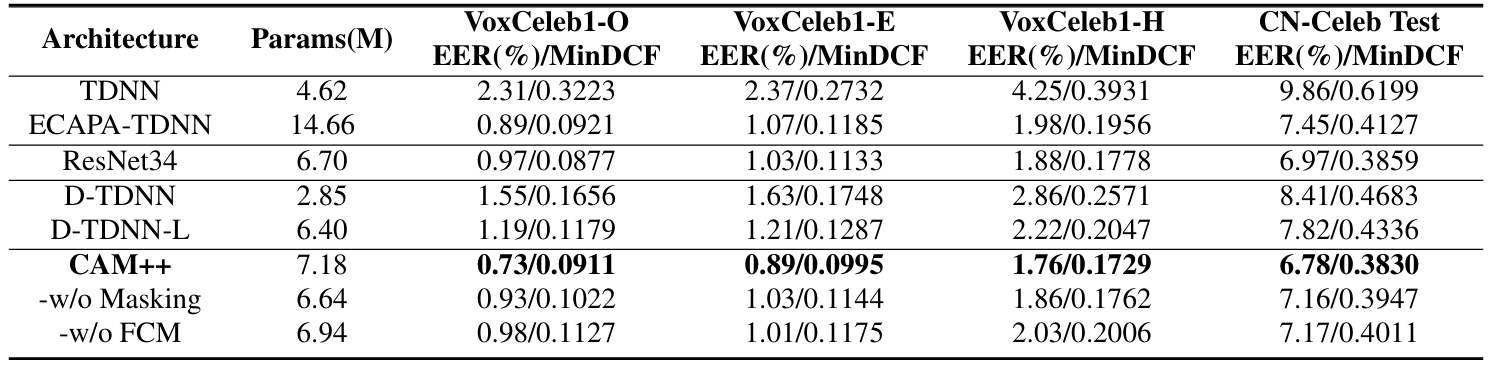
- CAM과 비교하여 CAM++는 더 적은 parameter와 더 나은 성능을 가짐

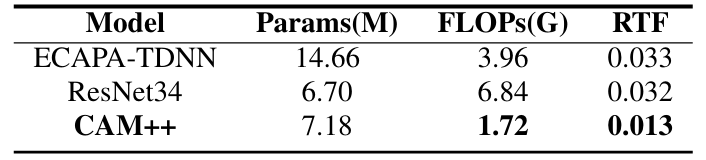
- Complexity Analysis
- CAM++는 더 적은 FLOPs와 더 빠른 RTF를 보임
반응형
'Paper > Verification' 카테고리의 다른 글
댓글