

티스토리 뷰
Paper/Verification
[Paper 리뷰] NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
feVeRin 2024. 9. 29. 11:03반응형
NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
- ConvNet structure를 활용하여 speaker verification을 위한 ECAPA-TDNN을 개선할 수 있음
- NeXt-TDNN
- ECAPA-TDNN의 SE-Res2Net block을 TS-ConvNeXt block으로 대체
- TS-ConvNeXt block은 temporal multi-scale convolution과 frame-wise feed-forward network로 구성됨 - Frame-wise feed-forward network에 global response normalization을 도입하여 selective feautre propagation을 지원
- ECAPA-TDNN의 SE-Res2Net block을 TS-ConvNeXt block으로 대체
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Speaker verification을 위한 human-crafted embedding feature vector (x-vector)는 DNN-based vector (d-vector)로 대체되고 있음
- 특히 Time Delay Neural Network (TDNN)을 사용하면 x-vector의 성능을 크게 향상할 수 있음
- 대표적으로 ECAPA-TDNN은 multi-scale에서 spectral structure를 capture 하기 위해, backbone layer로 1D convolution을 사용하는 Res2Net을 채택
- 추가적으로 global temporal context에서 feature gating을 지원하는 Squeeze-and-Excitation (SE) block을 도입하고, Multi-layer Feature Aggregation (MFA)를 통해 temporal pooling 이전에 shallow-layer feature를 반영
- 한편으로 speech는 일반적으로 spectral 2D visual feature로 취급되므로, speaker embedding vector 추출을 위해 simple 2D ResNet-based architecture를 활용할 수 있음
- 특히 최근에는 ConvNeXt와 같은 ConvNet 기반의 modernized structure가 제시되고 있음
- 특히 Time Delay Neural Network (TDNN)을 사용하면 x-vector의 성능을 크게 향상할 수 있음
-> 그래서 ConvNeXt를 활용하여 기존 Speaker Verification model을 modernize 한 NeXt-TDNN을 제안
- NeXt-TDNN
- ECAPA-TDNN의 SE-Res2Net block을 대체하는 Two-Step ConvNeXt (TS-ConvNeXt) block을 도입
- 서로 다른 scale을 가지는 parallel 1D depth-wise convolution (DConv1D) 기반의 Multi-Scale Convolution (MSC) module을 배치하고, 이후 Feed-Forward Network (FFN)을 Transformer structure와 같이 배치 - 추가적으로 FFN에 Global Response Normalization (GRN)을 적용하여 channel contrast를 향상
- SE-Res2Net block의 SE module을 대체하는 역할
- ECAPA-TDNN의 SE-Res2Net block을 대체하는 Two-Step ConvNeXt (TS-ConvNeXt) block을 도입
< Overall of NeXt-TDNN >
- TS-ConvNeXt block을 활용하여 기존 ECAPA-TDNN architecture를 개선
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- MFA Layer and ASP as Temporal Pooling
- 먼저 input feature는 frame 수 $T$에 대한 $C_{mel}\times T$ shape의 mel-spectrogram으로 제공됨
- 그러면 kernel size 4의 standard convolution을 통해 $C_{mel}$의 spectral dimension을 $C$의 latent channel dimension으로 변환되고, output feature $\mathbf{F}^{(0)}\in\mathbb{R}^{C\times T}$는 TS-ConvNeXt block을 통해 3-stage로 처리됨
- 이때 3-stage 모두에서 output $\mathbf{F}^{(1)},\mathbf{F}^{(2)},\mathbf{F}^{(3)}\in\mathbb{R}^{C\times T}$를 aggregate 하기 위해 ECAPA-TDNN의 MFA layer를 채택
- 구체적으로 $\mathbf{F}\in\mathbb{R}^{3C\times T}$와 같이 concatenate 된 다음, $C_{MFA}$의 output dimension을 가지는 1D point-wise convolution (PConv1D)와 Layer Normalization (LN)을 적용함 - 논문은 frame-level feature에서 utterance-level embedding을 추출하기 위해, channel-dependent attention value $\alpha_{t}\in\mathbb{R}^{C_{MFA}\times 1}$을 가지는 ASP pooling layer를 도입
- MFA layer output이 $\mathbf{H}=[\mathbf{h}_{1},...,\mathbf{h}_{T}]\in\mathbb{R}^{C_{MFA}\times T}$와 같이 주어지면, ASP layer는 해당 frame-level feature에서 $[0,1]$ 사이의 attention value를 계산하고
- 해당 값을 weighted mean $\mu=\sum_{t=1}^{T}\alpha_{t}\odot\mathbf{h}_{t}$과 standard deviation vector $\sigma=\sqrt{\sum_{t=1}^{T}\alpha_{t}\odot \mathbf{h}_{t}\odot\mathbf{h}_{t}-\mu\odot\mu}$ 계산에 사용함
- $\odot$ : Hadamard output - 이후 linear layer를 사용하여 두 statistics에서 speaker embedding $\mathbf{x}\in\mathbb{R}^{192\times 1}$을 추출함
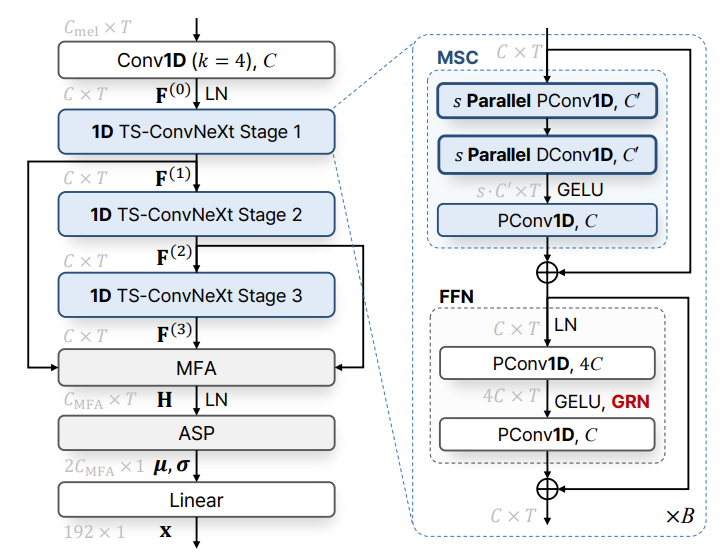
- Proposed TS-ConvNeXt Block
- NeXt-TDNN backbone은 3-stage TS-ConvNeXt block으로 구성되고, 각 block은 stage마다 $B$번 repeat 됨
- 즉, $n$-th stage ($n\in\{1,2,3\}$)에서 $b$-th block ($1\leq b\leq B$)에 대한 input representation $\mathbf{F}^{(n-1)}_{b-1}\in\mathbb{R}^{C\times T}$는 다음과 같이 처리됨:
(Eq. 1) $\tilde{\mathbf{F}}_{b-1}^{(n-1)}=\mathbf{F}_{b-1}^{(n-1)}+\text{MSC}(\mathbf{F}_{b-1}^{(n-1)})$
(Eq. 2) $\mathbf{F}_{b}^{(n-1)}=\tilde{\mathbf{F}}_{b-1}^{(n-1)}+\text{FFN}(\tilde{\mathbf{F}}_{b-1}^{(n-1)})$
- 여기서 $\mathbf{F}_{0}^{(0)}=\mathbf{F}^{(0)}$이고, $B$-th block output $\mathbf{F}_{B}^{(n-1)}$은 MFA layer의 input과 next stage의 first block으로 $\mathbf{F}_{B}^{(n-1)}=\mathbf{F}^{(n)}=\mathbf{F}^{(n)}_{0}$과 같이 전달됨
- MSC module은 inter-frame temporal context를 capture 하는 데 사용되고 FFN module은 frame-wise feature를 independent 하게 처리함 - Multi-scale feature를 효과적으로 capture 하기 위해, 논문은 Res2Net을 MSC module의 $s$개의 parallel DConv1D layer로 대체함
- 이때 각 layer는 아래 그림의 (b)와 같이 scale factor $s$를 가지는 서로 다른 kernel size $K_{1},...,K_{s}$를 가짐
- 각 scale에서 optimized training을 위해 MSC module의 input feature는 각 DConv1D layer 이전에 $C'$의 reduced dimension으로 project 되고,
- 이후 해당 multi-scale feature는 $s\cdot C'$의 dimension을 가지도록 concatentate 된 다음 GELU activation과 PConv1D를 거쳐 $C$로 다시 project 됨
- 결과적으로 MSC mechanism은 Transformer의 Multi-Head Self-Attention (MHSA)와 비슷하지만, MHSA의 attention operation이 DConv1D로 대체된다는 차이점이 있음
- 한편으로 FFN은 expansion factor가 4인 2개의 PConv1D layer와 GELU activation으로 구성되고, channel contrast를 향상하기 위해 GRN을 채택함
- 특히 GRN은 additional parameter layer 없이 간단하게 구현될 수 있음
- 먼저 GELU activation 이후 hidden feature가 $\mathbf{G}=[\mathbf{g}_{1},...,\mathbf{g}_{T}]\in\mathbb{R}^{4C\times T}$와 같이 주어지면,
- GRN은 temporal dimension에 대한 $L2$-norm을 vector $\bar{\mathbf{g}}\in\mathbb{R}^{4C\times 1}$과 같이 계산하고, aggregated value $\bar{\mathbf{g}}$에 response normalization function $\mathcal{N}(\cdot)$을 $\mathcal{N}(\bar{\mathbf{g}})=\bar{\mathbf{g}}/ || \bar{\mathbf{g}}||_{1}$과 같이 적용함
- $||\cdot ||_{1}$ : $L1$-norm - Original feature $\mathbf{g}_{t}$는 skip connection을 사용한 response normalization function value를 통해 calibrate 됨:
(Eq. 3) $\text{GRN}(\mathbf{g}_{t})=\mathbf{g}_{t}+\gamma\odot \mathcal{N}(\bar{\mathbf{g}})\odot \mathbf{g}_{t}+\beta$
- $\gamma,\beta\in\mathbb{R}^{4C\times 1}$ : affine transformation을 위한 trainable parameter (0으로 initialize 됨)
- 즉, $n$-th stage ($n\in\{1,2,3\}$)에서 $b$-th block ($1\leq b\leq B$)에 대한 input representation $\mathbf{F}^{(n-1)}_{b-1}\in\mathbb{R}^{C\times T}$는 다음과 같이 처리됨:
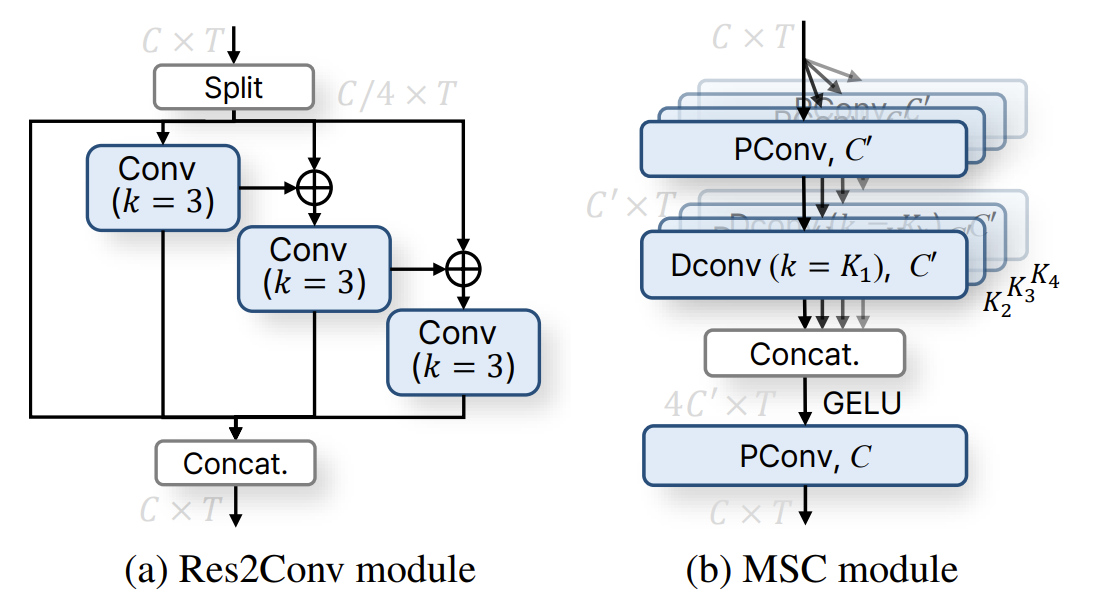
- Rationale of the Backbone Block Design
- 아래 그림과 같이 기존 block과 TS-ConvNeXt를 비교해 보면
- (a)의 SE-Res2Net block은 ResNet structure를 기반으로 channel dimension을 control 하는 2개의 PConv2D layer로 구성되고, Batch Normalization (BN)과 ReLU activation이 적용됨
- 이때 ResNet의 standard convolution을 Res2 Dilated Conv1D layer로 대체하여 multi-scale context를 capture 하고 specific channel에 attend 하는 SE block이 추가됨 - 한편으로 기존 Transformer는 (b)와 같이 MHSA와 FFN에 대한 2개의 sub-module을 가짐
- (c)의 ConvNeXt block은 Transformer와 ResNet block을 결합하여 구성됨
- 특히 ResNet의 standard convolution을 DConv로 변경하면 Transformer의 MHSA와 유사한 역할을 수행할 수 있음
- 추가적으로 ConvNeXt block은 norm과 activation이 적은 inverted bottleneck structure를 가짐 - ConvNext-V2의 경우, ConvNeXt의 inverted bottleneck에 GELU activation과 GRN을 적용하여 성능을 개선
- 특히 ResNet의 standard convolution을 DConv로 변경하면 Transformer의 MHSA와 유사한 역할을 수행할 수 있음
- NeXt-TDNN은 ECAPA-TDNN의 backbone block을 modernize 하기 위해, (d)와 같이 ConvNeXt를 확장한 TS-ConvNeXt를 채택함
- 구체적으로 MSC의 temporal block과 FFN의 position-wise processing block을 separate 하여 two-step way로 구성하고, MSC module에 temporal multi-scale feature를 도입함
- 해당 design을 통해 Transformer와 비슷하게 inter-/intra-frame context에 대해 flexible training을 지원 가능 - SE-Res2Net 측면에서 MSC는 multi-scale temporal modeling을 위한 Res2Net을 대체할 수 있고, GRN이 포함된 FFN은 point-wise feature processing을 위한 SE block을 대체할 수 있음
- 구체적으로 MSC의 temporal block과 FFN의 position-wise processing block을 separate 하여 two-step way로 구성하고, MSC module에 temporal multi-scale feature를 도입함
- 추가적으로 (e)의 TS-ConvNext-l block은 TS-ConvNeXt block의 lightweight version으로써 MSC module 대신 single DConv1D layer를 사용함
- (a)의 SE-Res2Net block은 ResNet structure를 기반으로 channel dimension을 control 하는 2개의 PConv2D layer로 구성되고, Batch Normalization (BN)과 ReLU activation이 적용됨

3. Experiments
- Settings
- Dataset : VoxCeleb1, VoxCeleb2
- Comparisons : Fast ResNet, ECAPA-TDNN, EfficientTDNN
- Results
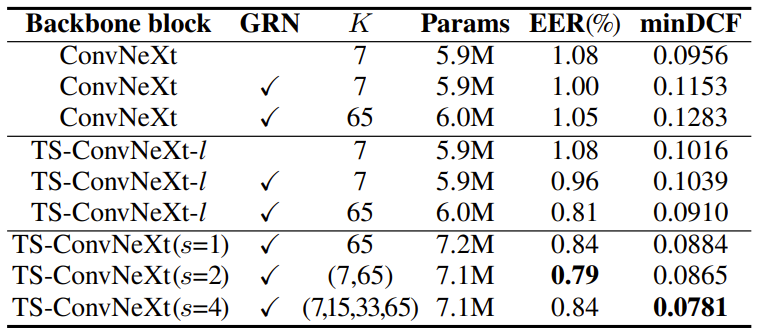
- 전체적으로 NeXt-TDNN이 가장 우수한 성능을 보임

- TS-ConvNeXt block의 효과를 확인해 보면,
- GRN을 사용하면 EER 성능이 향상되는 것으로 나타남
- 기존 ConvNeXt와 달리 TS-ConvNeXt-l은 $K=65$의 큰 kernel size에서 우수한 성능을 보임
반응형
'Paper > Verification' 카테고리의 다른 글
댓글