

티스토리 뷰
Paper/Verification
[Paper 리뷰] CAM: Context-Aware Masking for Robust Speaker Verification
feVeRin 2025. 9. 10. 08:52반응형
CAM: Context-Aware Masking for Robust Speaker Verification
- Speaker Verification은 noise로 인한 성능 저하의 문제가 있음
- CAM
- Interest speaker에 focus 하고 unrelated noise는 blur 하는 Speaker embedding network를 구성
- Speaker, noise characteristic을 capture하는 auxiliary context embedding을 통해 masking threshold를 dynamically control
- 논문 (ICASSP 2021) : Paper Link
1. Introduction
- Speaker Verification은 test utterance를 enrollment와 compare 하여 speaker identity를 verify 하는 것을 목표로 함
- 일반적으로 speaker verification은 2-step으로 진행됨
- First step에서는 speaker embedding을 추출하고, second step에서는 embedding의 speaker consistency를 scoring 함 - 한편으로 speaker embedding은 noise에 큰 영향을 받음:
- 이를 위해 speaker embedding에 denoising transformation을 적용하는 방법을 고려할 수 있음
- BUT, post-processing 과정에서 speaker embedding에 대한 information loss가 발생할 수 있음 - 한편으로 speech enhancement model을 통해 noise를 filtering하고 enhanced feature를 기반으로 robust speaker embedding을 추출하는 방법도 있음
- BUT, speech enhancement model은 computationally-expensive하고 inefficient 하므로 speaker verification task에 적합하지 않음
- 이를 위해 speaker embedding에 denoising transformation을 적용하는 방법을 고려할 수 있음
- 일반적으로 speaker verification은 2-step으로 진행됨
-> 그래서 효과적으로 noise-robust speaker verification을 추출할 수 있는 CAM을 제안
- CAM
- Context-Aware Masking을 통해 interest speaker에 focus하고 unrelated noise는 blur 하는 speaker embedding network를 구성
- Speaker, noise characteristic을 capture하는 auxiliary context embedding을 도입
< Overall of CAM >
- Context-Aware Masking을 활용한 noise-robust Speaker Verifciaiton model
- 결과적으로 기존보다 우수한 성능을 달성
2. Related Work
- Attentive Statistics Pooling
- Attentive Statistics Pooling (ASP)는 서로 다른 frame에 서로 다른 weight를 assign 함
- 특히 noisy frame에는 small weight를 assign 함
- 이때 ASP는 attention weight를 calculate 하기 위해 다음의 module을 채택함:
(Eq. 1) $s_{t}=\mathbf{v}^{\top}\delta\left(\mathbf{U}^{\top}\mathbf{h}_{t}+\mathbf{p}\right)+q$
(Eq. 2) $\alpha_{t}=\frac{\exp(s_{t})}{\sum_{\tau=1}^{T}\exp(s_{\tau})}$
- $\delta(\cdot)$ : activation function, $\mathbf{h}_{t},s_{t},\alpha_{t}$ : 각각 $t$-th frame의 hidden feature vector, score, attention weight
3. Method
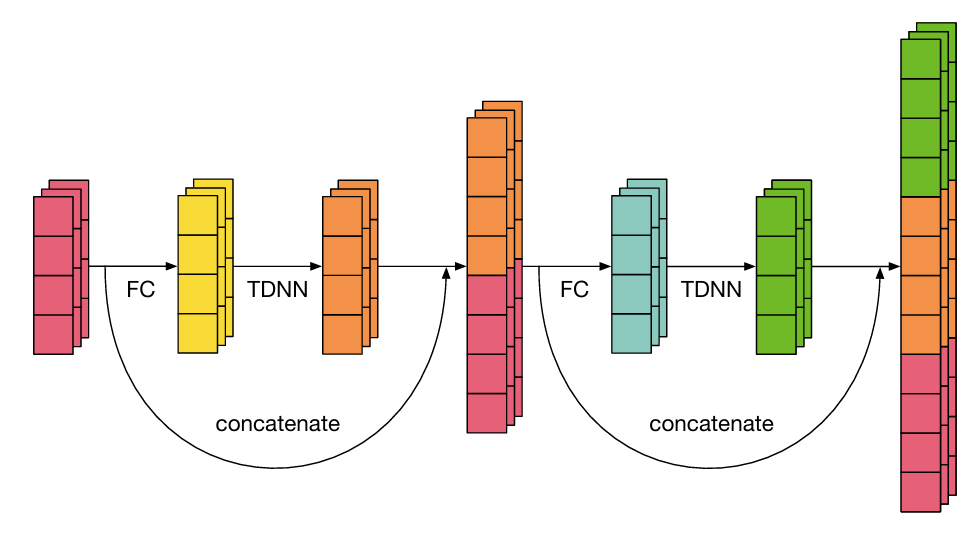
- CAM은 Time-Delay Neural Network (TDNN)-based speaker embedding backbone을 활용함
- Speaker Embedding
- SV task에서 TDNN은 speaker embedding을 추출하기 위해 주로 사용됨
- 여기서 vanilla TDNN은 2개의 consecutive position-wise fully-connected (FC) layer, statistics pooling layer, FC-based embedding layer로 구성됨
- 추가적으로 논문은 더 적은 parameter를 가지는 Densely-connected TDNN (D-TDNN)를 고려함
- D-TDNN layer는 position-wise FC-based bottleneck layer와 TDNN-layer로 구성됨
- 이때 논문은 D-TDNN layer의 input과 inner output을 concatenate 하여 final output을 구성하고, TDNN-ReLU-BatchNorm (BN)을 memory-friendly 한 BN-ReLU-TDNN으로 replace 함

- Context-Aware Masking
- Input acoustic feature를 $\mathbf{x}$라 하자
- 그러면 selected hidden layer의 output feature map은:
(Eq. 3) $g(\mathcal{F}(\mathbf{x}))$
- $g(\cdot)$ : hidden layer의 transformation, $\mathcal{F}(\cdot)$ : hidden layer 이전의 transformation - 기존 speech enhancement-based method에서는 enhanced acoustic feature $\tilde{\mathbf{x}}$를 predict 하고, 이때 hidden layer의 output feature map은:
(Eq. 4) $g(\mathcal{F}(\tilde{\mathbf{x}))$ - Feature map masking은 feature map에 ratio mask를 적용하는 것을 의미하고, speech enhancement에서 similar effect를 얻을 수 있다면 다음을 만족하는 mask $\tilde{\mathbf{M}}$을 find 할 수 있음:
(Eq. 5) $g(\mathcal{F}(\mathbf{x}))\odot \tilde{\mathbf{M}}\propto g(\mathcal{F}(\tilde{\mathbf{x}}))$
- $\odot$ : element-wise multiplication
- $\tilde{\mathbf{M}}$의 element는 $(0,1)$ range로 normalize 됨 - 여기서 proper ratio mask를 estimate 하기 위해, 논문은 auxiliary context embedding $\mathbf{e}$에서 derive 되는 speaker interest와 noise의 characteristic을 활용함
- 먼저 frame-by-frame으로 context-aware mask를 predict 하면:
(Eq. 6) $\mathbf{F}=\mathcal{F}(\mathbf{x})$
(Eq. 7) $\mathbf{M}_{*t}=\sigma\left(\mathbf{W}_{2}^{\top}\omega\left( \mathbf{W}_{1}^{\top}\mathbf{F}_{*t}+\mathbf{e}\right)+\mathbf{b}_{2}\right)$
(Eq. 8) $\tilde{\mathbf{F}}=g(\mathcal{F}(\mathbf{x}))\odot \mathbf{M}$
- $\sigma(\cdot)$ : Sigmoid function, $\omega(\cdot)$ : ReLU, BN의 combination
- $\mathbf{M}$ : predicted ratio mask, $\mathbf{M}_{*t}, \mathbf{F}_{*t}$ : $t$-th frame의 mask, feature, $\tilde{\mathbf{F}$ : masking 이후의 feature map - Auxiliary context embedding $\mathbf{e}$는 activation threshold를 control 하는 dynamic bias vector로 사용할 수 있음
- 먼저 frame-by-frame으로 context-aware mask를 predict 하면:
- 한편으로 CAM은 context-aware speech enhancement와 달리 context embedding을 dynamically extract 하므로 forwarding propagation을 통해 main speaker를 automatically find 할 수 있음
- 특히 CAM은 speech의 대부분이 특정 speaker에서 나오는 경우, speaker volume이 interfering speaker 보다 significantly higher 한 경우, 해당 speaker를 main speaker로 recognize 함 - 이때 main speaker와 global non-speech noise를 find 하기 위해서는 utterance-level embedding을 추출해야 함
- 이를 위해 논문은 hidden layer의 input feature map을 기반으로 context embedding을 추출함
- 먼저 Statistics Pooling Layer를 통해 모든 frame을 combine 하면:
(Eq. 9) $\mu=\frac{1}{T}\sum_{t=1}^{T}\mathbf{F}_{*t}$
(Eq. 10) $\sigma=\sqrt{\frac{1}{T}\sum_{t=1}^{T}\mathbf{F}_{*t}\odot \mathbf{F}_{*t}-\mu\odot \mu}$
- $\mu$ : mean vector, $\sigma$ : standard deviation vector - 이후 FC layer는 mean/standard deviation vector를 context embedding으로 mapping 함:
(Eq. 11) $\mathbf{e}=\mathbf{W}^{\top}_{3}[\mu,\sigma]+\mathbf{b}_{3}$
- $[\cdot]$ : concatenation
- 그러면 selected hidden layer의 output feature map은:
4. Experiments
- Settings
- Dataset : VoxCeleb
- Comparisons : TDNN, D-TDNN

- Results
- CAM을 적용하면 SV 성능을 더 향상할 수 있음

- VoxCeleb-H task에 대해서도 CAM은 우수한 성능을 보임
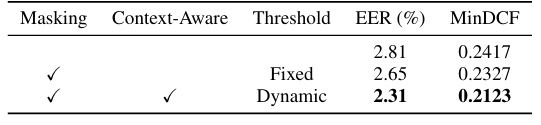
- FLOPS 측면에서도 CAM은 computational cost를 크게 증가시키지 않음

- Visualization
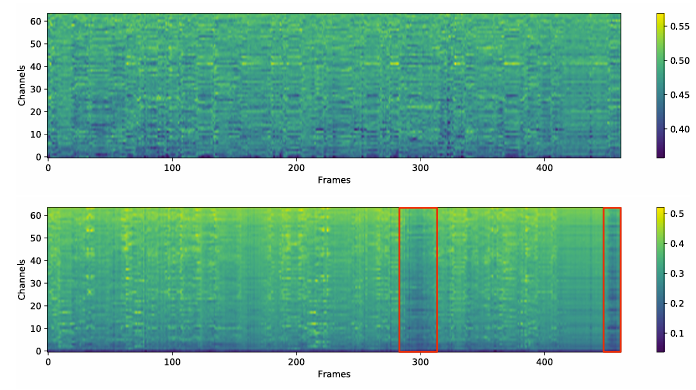
- CAM은 서로 다른 channel, 서로 다른 frame에 서로 다른 mask를 assign 함
- 특히 deep layer에서 mask는 speaker interest에 대한 clear pattern을 보임
반응형
'Paper > Verification' 카테고리의 다른 글
댓글