

티스토리 뷰
Paper/TTS
[Paper 리뷰] DPI-TTS: Directional Patch Interaction for Fast-Converging and Style Temporal Modeling in Text-to-Speech
feVeRin 2025. 5. 15. 18:01반응형
DPI-TTS: Directional Patch Interaction for Fast-Converging and Style Temporal Modeling in Text-to-Speech
- Diffusion Transformer 기반의 speech model은 mel-spectrogram을 general image로 취급함
- DPI-TTS
- Diffusion Transformer를 기반으로 low-to-high frequency, frame-by-frame progressive inference approach를 적용하여 naturalness를 향상
- Fine-grained style temporal modeling을 도입하여 speaker style similarity를 개선
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 주어진 text로부터 natural speech를 생성하는 것을 목표로 함
- 특히 Diff-TTS, Grad-TTS, NaturalSpeech2 등은 TTS diffusion process를 활용하여 우수한 성능을 달성함
- 이때 일반적으로 사용되는 U-Net architecture는 Transformer architecture로 replace 될 수 있음
- Diffusion Transformer (DiT)는 Transformer architecture에 기반한 diffusion model을 활용하여 modeling capability를 향상할 수 있음
- 대표적으로 DiTTo-TTS의 경우 cross-attention mechanism을 통해 TTS alignment를 개선함 - BUT, DiT-based TTS model은 mel-spectrogram을 general image로 취급하므로 speech의 intrinsic acoustic property를 neglecting 함
- Diffusion Transformer (DiT)는 Transformer architecture에 기반한 diffusion model을 활용하여 modeling capability를 향상할 수 있음
-> 그래서 DiT-based TTS에서 style temporal modeling을 개선한 DPI-TTS를 제안
- DPI-TTS
- Mel-spectrogram을 patch로 segment 하고 각 patch와 preceding frame, low-frequency component 간의 attention을 compute 하는 Directional Patch Interaction을 도입
- Cross-attention을 통해 mel-patch에 style information을 incrementally incorporate 하여 Directional Patch Interaction 하에서 speaker similarity를 향상
< Overall of DPI-TTS >
- Directional Patch Interaction을 활용한 DiT-based TTS model
- 결과적으로 기존보다 빠른 convergence와 합성 성능을 달성
2. Method
- DPI-TTS는 Multi-Head Self-Attention (MHSA)와 Relative Position Embedding (RoPE)를 포함한 8개의 Transformer layer를 가지는 text encoder를 활용함
- 추가적으로 text를 initial mel-spectrogram frame $h_{mel}$에 mapping 하는 convolution-based Duration Predictor (DP)를 활용함
- Diffusion decoder는 Down Conv Block, mel-spectrogram을 patch로 segmenting 하는 Patchify module, $k$ Global DiT block, $N-k$ Directional DiT block, feature restoration을 위한 Up Conv Block으로 구성됨
- Global DiT block은 pitch와 같은 global speech information을 capture 하고 Directional DiT block은 style temporal modeling과 mel-patch의 directional interaction을 처리함
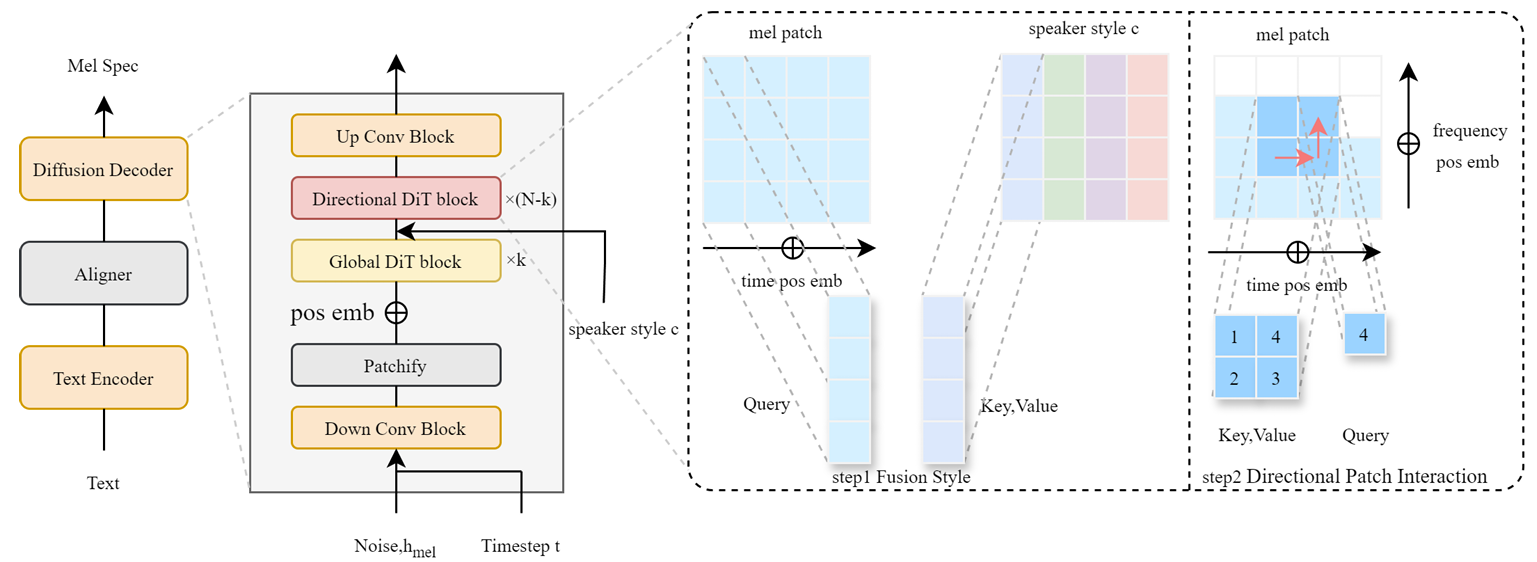
- Directional Patch Interaction
- Speech signal은 time에 따라 dynamically change 함
- 특히 pause, emphasis, rhythm, prosody와 같은 factor는 distinct temporal property를 가짐
- Low, high-frequency component 간의 energy distribution 역시 서로 다름 - 따라서 각 mel-patch를 preceding frame, low-frequency component와 associate 함으로써 dynamic temporal change를 preserve 하고 local detail modeling을 향상할 수 있음
- 먼저 논문은 각 mel-spectrogram image patch에 대한 query, key, value를 compute 함
- Batch size $b$, frequency axis에 대한 patch 수 $h$, time axis에 대한 patch 수 $w$, feature dimension $d$에 대해 initial shape는 $(b,h,w,d)$와 같음 - 다음으로 additional dimension이 query, key, value에 insert 되어 $(b,h,w,1,d)$ shape를 얻음
- Key, value의 last row와 first column이 key, value와 concatenate 되어 $(b,h+1,w+1,1,d)$를 생성함
- Concatenated key, value는 size $(h,w)$의 window를 통해 split 되고 3-rd dimension을 따라 concatenate 되어 $(b,h,w,4,d)$ shape를 생성함
- 최종적으로 모든 patch가 flatten 되고 attention computation을 적용하여 $(b,hw,1,d)$ shape를 생성함
- 먼저 논문은 각 mel-spectrogram image patch에 대한 query, key, value를 compute 함
- 특히 pause, emphasis, rhythm, prosody와 같은 factor는 distinct temporal property를 가짐

- Fine-Grained Speaker Style Temporal Modeling
- DPI-TTS는 mel-spectrogram을 multiple patch로 dividing 하므로 style의 fine-grained temporal control이 가능함
- 기존 TTS model은 style control을 위해 speaker ID나 global style information을 사용하므로 overly smooth style expression이 나타나고 precise control이 어려움
- 이를 해결하기 위해 DPI-TTS는 style information을 time에 따라 sequentially integrate 하고, 각 time point에서 모든 patch를 cohesive unit으로 취급함
- 이를 통해 high, low frequency에 걸쳐 consistent style representation을 보장할 수 있음 - 결과적으로 DPI-TTS는 mel-patch를 query로 사용하고 speaker style을 key, value로 사용함
- 이때 style에 대한 temporal awareness를 향상하기 위해 mel-patch에 time positional information을 add 함
- 이후 각 patch group에 대해 time-dimension을 따라 cross-attention을 compute 하여 style feature를 speech에 integrate 함
3. Experiments
- Settings
- Results
- Directional Pitch Interaction Enables Fast Training
- 동일한 time frame에 대해 DPI-TTS는 2배의 epoch을 training 할 수 있음
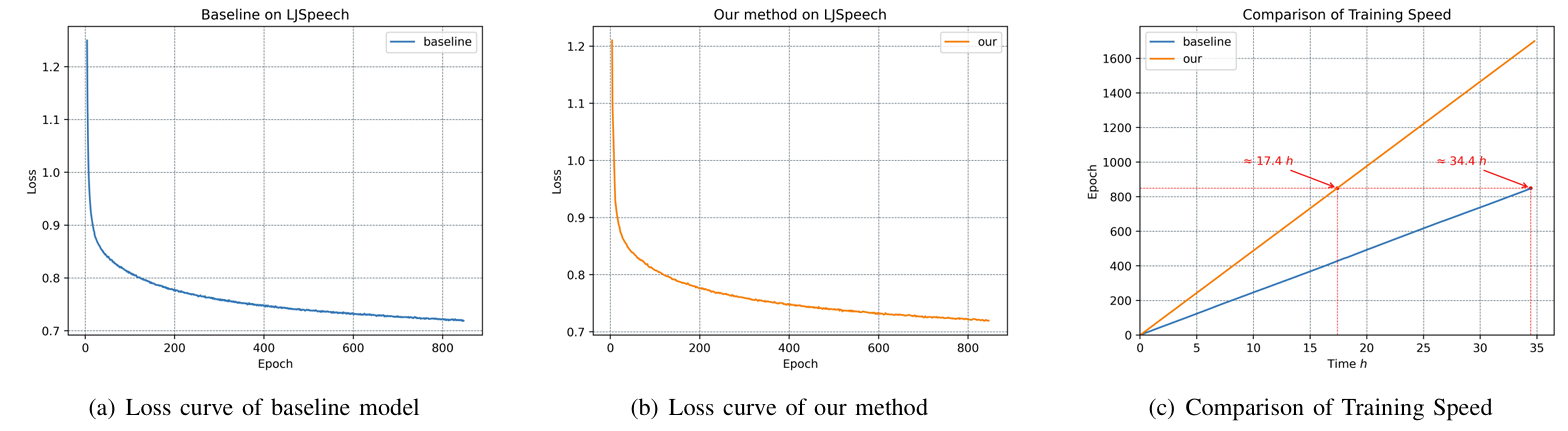
- Fast Training does not Degrade Performance
- 합성 품질 측면에서도 DPI-TTS는 가장 우수한 성능을 보임

- Ablation Study
- Next frame $n$, previous frame $p$, low frequency $l$, high frequency $h$, previous frame의 high-frequency $ph$의 acoustic property combination을 비교해 보면, DPI-TTS가 가장 우수한 성능을 보임

- 각 component를 제거하는 경우 성능 저하가 발생함
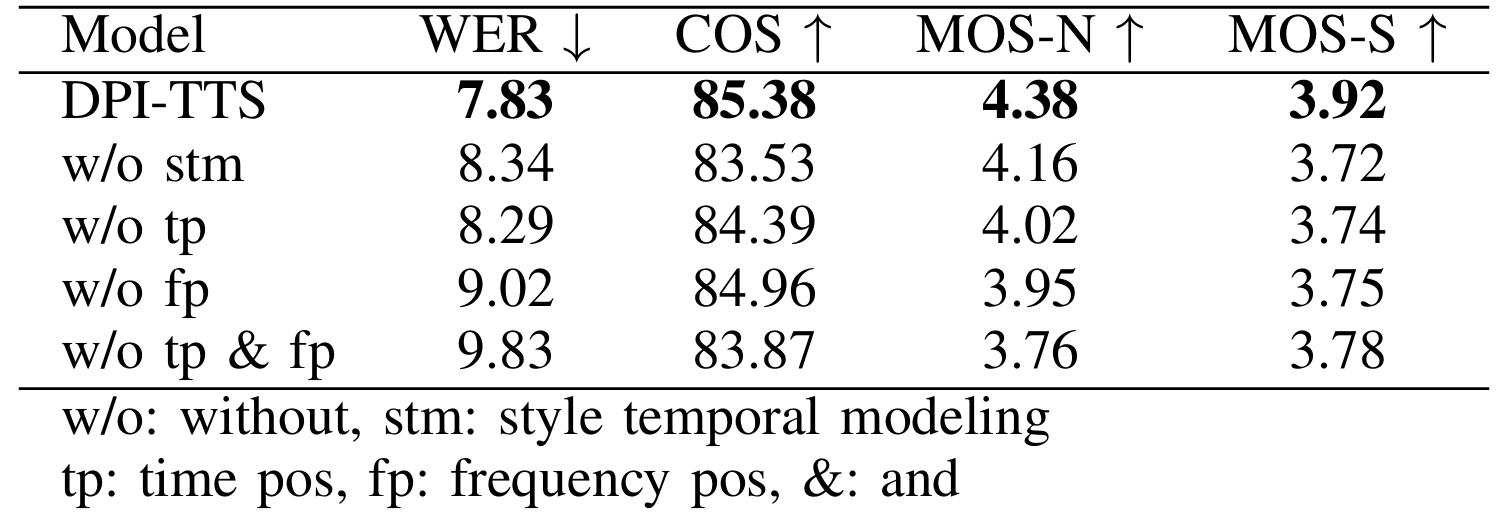
반응형
'Paper > TTS' 카테고리의 다른 글
댓글