

티스토리 뷰
Paper/TTS
[Paper 리뷰] FluentTTS: Text-dependent Fine-grained Style Control for Multi-style TTS
feVeRin 2025. 1. 13. 11:12반응형
FluentTTS: Text-dependent Fine-grained Style Control for Multi-style TTS
- Neural text-to-speech model은 local prosodic variation을 flexibly control 할 수 있어야 함
- FluentTTS
- Utterance-wise global style embedding을 condition으로 하여 각 text의 fundamental frequency $F0$를 예측함
- 추가적으로 global utterance-wise embedding과 local $F0$ embedding을 input으로 사용하는 multi-style encoder를 통해 multi-style embedding을 추정함
- 논문 (INTERSPEECH 2022) : Paper Link
1. Introduction
- 대부분의 neural Text-to-Speech (TTS) model은 input phonetic feature에서 mel-spectrogram이나 latent space embedding과 같은 acoustic feature를 예측한 다음, vocoder를 통해 speech waveform을 생성함
- 이때 human-like speech signal을 얻기 위해서는 speaking speed, emotion, intonation과 같은 prosody-related information을 control 할 수 있어야 함
- BUT, input text에 대해 다양한 style option이 존재하는 one-to-many mapping 문제로 인해 기존 TTS model은 한계가 있음 - 이를 해결하기 위해 speaker identity와 prosody-related information을 포함하는 additional conditional embedding을 활용할 수 있음
- 대표적으로 global style embedding은 text embedding에 추가되어 decoding stage에서 input text-related information으로 사용됨
- BUT, 이 경우 동일한 global style embedding이 각 text symbol에 적용되므로 decoder는 local prosodic variation을 represent 하기 위해서는 text embedding에 의존해야 함
- 즉, overall prosodic feature의 characteristic을 average 하는 global style embedding은 decoder에 local prosody information을 제공할 수 없음 - 따라서 multi-speaker, multi-emotion을 포함하는 multi-style TTS에서는 활용하기 어려움
- Fine-grained local style control을 위해 FastPitch와 같이 input text symbol에 대한 pitch를 예측할 수 있지만 여전히 한계가 있음
- 이때 human-like speech signal을 얻기 위해서는 speaking speed, emotion, intonation과 같은 prosody-related information을 control 할 수 있어야 함
-> 그래서 local prosodic variation을 개선하고 fine-grained style embedding을 생성할 수 있는 FluentTTS를 제안
- FluentTTS
- Local style을 represent 하기 위해 fundamental frequency $F0$를 활용
- 다양한 style에 대한 prediction complexity를 minimize 하기 위해 각 speaker의 $F0$ value를 mean/standard deviation으로 normalize 하여 standard normal distribution을 가지도록 함
- 이때 input utterance의 $F0$ 수는 spectral acoustic feature frame 수와 같으므로 internal aligner를 사용하여 timing information을 text symbol과 synchronize 함
- Training 중에 internal aligner를 사용하여 phoneme-level reference $F0$ value로부터 $F0$ embedding을 생성한 다음, global style embedding과 concatenate 하여 사용
- 여기서 global style embedding은 conditional layer normalization으로 얻어지고 input text symbol에 대한 $F0$를 예측하는 방법을 학습함
- 추론 시에는 predicted $F0$ value에서 $F0$ embedding을 생성하여 local prosodic variation을 control 함
- Local style을 represent 하기 위해 fundamental frequency $F0$를 활용
< Overall of FluentTTS >
- Fundamental frequency를 활용하여 controllability를 개선한 multi-style TTS model
- 결과적으로 기존보다 뛰어난 합성 품질과 controllability를 달성
2. Method
- FluentTTS는 MultiSpeech를 기반으로 emotion-related information을 추출하기 위한 reference encoder를 도입함
- 구조적으로 FluentTTS는:
- Softsign function을 사용하여 speaker encoder와 reference encoder로부터 각각 speaker/emotion embedding을 생성함
- 이후 각 embedding은 fully-connected layer에 전달되어 dimension을 reduce 함
- Fully-connected layer output은 global style embedding으로 사용됨 - 추가적으로 internal aligner를 사용하여 text embedding과 mel-spectrogram 간의 binary valued hard alignment $\mathcal{A}_{hard}$를 생성함
- 이후 hard alignment information을 사용하여 각 text symbol의 duration에 대한 normalized reference $F0$를 averaging 하여 phoneme-level $F0$를 얻음
- FluentTTS의 training objective는 input text에서 phoneme-level $F0$를 예측하는 것을 목표로 함
- 따라서 text embedding과 global style embedding을 input으로 하여 appropriate normalized $F0$ value를 생성하는 $F0$ predictor를 도입함 - 여기서 $F0$ value는 training step에서 aligned reference나 inference step의 predicted value에 해당하고, Conv1D layer를 통해 encode 되어 $F0$ embedding을 생성함
- 이후 global style embedding과 $F0$ embedding을 concatenate 한 다음, multi-style encoder를 통해 multi-style embedding을 생성함
- 최종적으로 decoder는 text와 multi-style embedding의 concatenation을 기반으로 mel-spectrogram을 생성함
- 구조적으로 FluentTTS는:

- $F0$ Generation
- Raw $F0$ value는 speaker identity와 emotion type에 따라 다르므로 raw $F0$를 directly predict 하는 것은 어려움
- 따라서 논문은 $F0$ value를 각 speaker와 emotion의 mean/standard deviation으로 normalize 한 다음, normalized $F0$ value를 $F0$ predictor의 target으로 사용함
- 이때 speech signal에서 reference $F0$ value를 추출하기 위해 WORLD vocoder를 활용함
- Text-dependent Average $F0$
- Input text에서 $F0$를 학습하고 예측하기 위해서는 reference $F0$ length가 input text length와 동일해야 함
- 이때 target $F0$ value를 정의하면 off-line external aligner를 사용하여 각 text interval 내에서 average $F0$ value를 계산할 수 있음
- BUT, $F0$ estimation process에 error가 있는 경우 time-alignment 문제가 발생할 수 있음 - 따라서 incorrect time-alignment로 발생하는 mismatching 문제를 해결하기 위해 TTS training 과정에서 frame-level $F0$와 해당 text symbol 간의 timing information을 synchronize 하는 internal aligner를 도입함
- Internal aligner는 hard alignment output을 생성하므로 text symbol과 mel-spectrogram frame 간의 one-to-one mapping을 represent 함 - 결과적으로 해당 information을 사용하여 각 phonetic symbol에 해당하는 reference average $F0$ value를 얻을 수 있음
- 논문에서는 phoneme-level $F0$ ($\widetilde{F0}$)를 content-dependent fine-grained style feature로 사용함
- $F0$ Prediction in the Inference Stage
- 추론 시에는 reference $F0$를 사용할 수 없으므로 이를 예측할 수 있어야 함
- 따라서 논문은 FastSpeech2의 pitch predictor와 AdaSpeech의 conditional layer normalization을 활용하여 $F0$ predictor를 구성함
- 구조적으로는 input text-related embedding으로부터 $F0$를 accurately predict 하기 위해 3 layer를 stack 함
- 추가적으로 conditional layer normalization으로부터 $F0$ predictor가 $F0$ value를 생성할 수 있도록 utterance-wise global style embedding을 제공함
- 이후 fully-connected layer를 통과한 다음, $F0$ predictor는 appropriate normalized $F0$ ($\widehat{F0}$)를 추정함
- Multi-Style Encoder
- Multi-style encoder는 $F0$ predictor와 동일하지만 stack 되지 않고 last layer에 softsign function을 통해 output embedding의 dynamic range를 restrict 함
- 먼저 multi-style encoder는 global style embedding과 local $F0$ embedding을 concatenating 하여 input으로 사용함
- 특히 global style embedding과 local $F0$ embedding의 characteristic은 speaker identity나 emotion에 따라 rapidly change 하므로 multi-style encoder는 input embedding의 dynamic nature를 handle 할 수 있어야 함 - Multi-style encoder output은 $F0$ embedding type에 따라 다를 수 있음
- 이때 $F0$ embedding은 text-dependent average $F0$로부터 생성되므로 multi-style embedding에는 text-dependent local prosodic information이 포함되어 있음 - Global style embedding은 input utterance에 대한 entire prosodic variation을 represent 할 수 있지만, model이 utterance-level global style embedding에서 local prosodic variation을 reconstruct 하는 것은 어려움
- 반면 FluentTTS는 global style과 $F0$ embedding에서 생성된 global, local prosodic variation을 결합하여 fine-grained reconstruction이 가능함
- 먼저 multi-style encoder는 global style embedding과 local $F0$ embedding을 concatenating 하여 input으로 사용함
- Dynamic Level $F0$ Control
- FluentTTS는 utterance, word, phoneme-level에서 prosodic variation을 explicitly control 하는 것을 목표로 함
- 이때 model은 input text symbol의 $F0$ value를 예측하므로 speech signal을 flexibly synthesize 하여 desired prosodic variation이나 $F0$ modification을 얻을 수 있음
- Word의 $F0$를 변경하는 경우, input utterance에서 word의 위치를 찾은 다음 해당 $F0$를 수정하는 방식으로 동작함
- Training Objective
- FluentTTS는 stability를 유지하기 위해 여러 loss function을 결합하여 사용함
- 여기서 FluentTTS의 training objective는:
(Eq. 1) $\mathcal{L}_{Final}=\mathcal{L}_{TTS}+\mathcal{L}_{IA}+\mathcal{L}_{F0}$
- $\mathcal{L}_{TTS}$ : TTS training에 대한 loss term
- $\mathcal{L}_{IA}$ : internal aligner module에 대한 loss term
- $\mathcal{L}_{F0}$ : $F0$ predictor module에 대한 loss term - 논문은 $20k$가 될 때까지 multi-style generation을 사용하지 않고 global style embedding을 사용함
- 전체 training process가 stable 되어야 하기 때문 - 한편으로 $\mathcal{L}_{TTS}$는 다음과 같이 정의됨:
(Eq. 2) $\mathcal{L}_{TTS} =\mathcal{L}_{rec}+\mathcal{L}_{bce}^{stop}+\mathcal{L}_{guide}+\mathcal{L}_{cls}^{emo}$
- $\mathcal{L}_{rec}$ : mel-spectrogram reconstruction을 위한 $L1$ loss
- $\mathcal{L}_{bce}^{stop}$ : stop token에 대한 binary cross-entropy loss
- $\mathcal{L}_{guide}$ : encoder-decoder attention의 stable alignment를 위한 guided attention loss
- $\mathcal{L}_{cls}^{emo}$ : reference encoder의 emotion classification loss - Internal aligner module을 training 하기 위해 CTC loss와 $10k$ step 이후에 KL-divergence loss를 적용함:
(Eq. 3) $\mathcal{L}_{IA} =\mathcal{L}_{CTC}+\lambda_{KL}\mathcal{L}_{KL}$
- $\lambda_{KL} = 0.1$
- 여기서 FluentTTS의 training objective는:
3. Experiments
- Settings
- Dataset : Korean Multi-Speaker Dataset
- Comparisons : MultiSpeech
- Results
- 전체적으로 FluentTTS가 가장 우수한 합성 품질을 보임

- $F0$ Controllability
- FluentTTS는 $F0$ predictor module을 통해 word-level, phoneme-level에서도 $F0$ value를 flexibly control 할 수 있음
- Unseen text에 대한 word-level $F0$ modification 측면에서 FluentTTS는 50Hz만큼 $F0$를 감소/증가시킬 수 있음
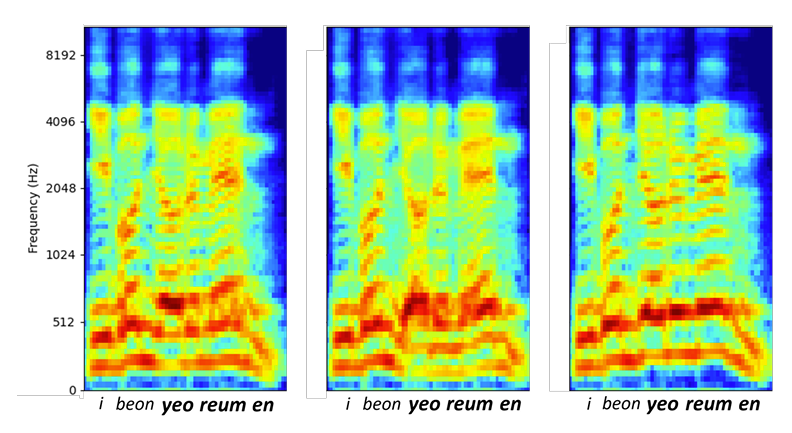
- Phoneme-level $F0$ modification 측면에서도 50Hz만큼 phoneme의 $F0$를 control 할 수 있음
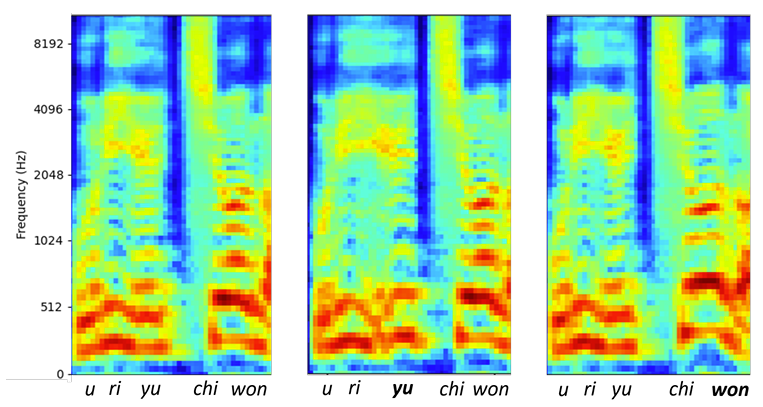
반응형
'Paper > TTS' 카테고리의 다른 글
댓글