

티스토리 뷰
Paper/Language Model
[Paper 리뷰] TacoLM: Gated Attention Equipped Codec Language Model are Efficient Zero-shot Text-to-Speech Synthesizers
feVeRin 2024. 7. 16. 10:40반응형
TacoLM: Gated Attention Equipped Codec Language Model are Efficient Zero-shot Text to Speech Synthesizers
- Neual codec language model은 zero-shot text-to-speech에서 우수한 성능을 보이고 있음
- BUT, autoregressive nature와 text-audio 간의 implicit alignment로 인해 속도의 한계가 있음
- TacoLM
- Training/inference 속도를 향상하고 model size를 줄이기 위해 gated attention mechanism을 도입
- 추가적으로 각 decoder layer마다 gated cross-attention layer를 적용하여 합성 품질과 efficiency를 향상
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Zero-shot text-to-speech (TTS)는 짧은 audio sample을 prompt로 하여 unseen speaker에 대한 고품질 음성을 합성하는 것을 목표로 함
- 기존에는 YourTTS, SC-GlowTTS와 같이 explicit speaker encoder를 사용하여 speaker의 timbre, prosody 등을 반영했음
- BUT, 해당 speaker embedding은 zero-shot scenario로의 generalizability를 크게 저하함 - 한편으로 FastDiff와 같이 diffusion modeling을 사용하거나 AudioLM과 같이 language model을 사용하여 zero-shot TTS를 수행할 수도 있음
- 특히 VALL-E와 같은 neural codec language model (LM)은 phoneme, acoustic token을 prompt을 기반으로 unenrolled speaker에 대한 음성을 합성함
- 이때 autoregressive (AR), non-autoregressive (NAR) language model을 통해 coarse/fine-grained acoustic token을 생성 - 해당 approach를 통해 speaker embedding encoding 없이 audio sample에서 environment/acoustic information을 직접 추출할 수 있음
- 특히 VALL-E와 같은 neural codec language model (LM)은 phoneme, acoustic token을 prompt을 기반으로 unenrolled speaker에 대한 음성을 합성함
- BUT, VALL-E는 뛰어난 zero-shot TTS 성능에도 불구하고 AR model을 사용하기 때문에 coarse-grained acoustic token 생성 속도가 느림
- 특히 transformer의 multi-head attention은 token pair 간의 relationship을 모델링하는데 효과적이지만, 상당한 computational/memory cost를 가짐
- 이때 AR model은 token-by-token으로 output을 생성하므로 추론 과정에서 속도 문제가 더욱 두드러짐 - 추가적으로 VALL-E는 합성된 음성과 text prompt 간의 mismatch로 인해 repetition, transposition, omission 등이 종종 발생함
- 이는 model이 text와 speech를 well-align 하지 못하기 때문
- 특히 transformer의 multi-head attention은 token pair 간의 relationship을 모델링하는데 효과적이지만, 상당한 computational/memory cost를 가짐
- 기존에는 YourTTS, SC-GlowTTS와 같이 explicit speaker encoder를 사용하여 speaker의 timbre, prosody 등을 반영했음
-> 그래서 빠르고 효율적으로 동작하면서 뛰어난 zero-shot 성능을 달성할 수 있는 LM인 TacoLM을 제안
- TacoLM
- VALL-E와 유사한 two-stage (AR-NAR) framework에 대해, exponential moving average를 사용하는 single-head gated attention mechanism을 채택한 MEGA module을 도입
- 이를 통해 computational cost와 memory 사용량을 줄임 - 추가적으로 합성된 음성의 accuracy를 향상하기 위해 gated cross-attention mechanism을 적용하여 text-audio 간의 information을 exchange 함
- VALL-E와 유사한 two-stage (AR-NAR) framework에 대해, exponential moving average를 사용하는 single-head gated attention mechanism을 채택한 MEGA module을 도입
< Overall of TacoLM >
- Audio와 text를 discretize 한 다음, language model을 사용해 합성을 수행하는 two-stage zero-shot TTS framework
- Lightweight Moving Average Equipped Gated Attention (MEGA) module과 gated cross-attention layer를 채택해 효율성을 향상
- 결과적으로 기존보다 빠른 training/inference 속도와 뛰어난 zero-shot 합성 품질을 달성
2. Method
- TacoLM은 뛰어난 zero-shot TTS capability를 확보하는 것을 목표로 함
- 구조적으로는 VALL-E와 비슷하게 text encoder, neual audio codec, autoregressive language model, non-autoregressive language model로 구성됨
- 이때 training/inference efficiency를 향상하고 model size를 줄이기 위해 vanilla transformer-based autoregressive model을 다음과 같이 수정함
- Multi-head attention의 효율적인 대체로써 gated attention mechanism을 도입
- Autoregressive model의 computation, storage efficiency를 향상하는 gated cross-attention layer를 적용

- Model Framework
- TacoLM은 two-stage로 동작함
- 먼저 input side에서는 input text transcript와 audio waveform을 semantic token sequence에 mapping 함
- 이때 pre-trained neural audio codec인 EnCodec을 audio tokenizer로 활용 - First stage에서 해당 token은 AR language model에 input 되어 EnCodec의 first quantizer에 대한 codec code를 생성함
- Second stage에서는 NAR language model을 통해 나머지 quantizer의 code를 parallel predict 함
- 추론 시에는 target text sequence와 unseen speaker에 대한 recording을 prompt로 하여 zero-shot TTS를 수행
- 먼저 input side에서는 input text transcript와 audio waveform을 semantic token sequence에 mapping 함
- Text Encoder
- Text encoder는 text transcription에서 content representation을 추출하는 데 사용됨
- 이를 위해 논문은 Byte-Pair Encoding (BPE)를 사용하여 discrete text representation을 추출
- BPE text encoder model은 LibriSpeech training set의 transcribed data를 사용하여 training 됨
- 여기서 word vocabulary set은 2000, Character Coverage Rate (CCR)은 1.0으로 설정
- Neural Audio Codec
- TacoLM은 pre-trained neural audio codec인 EnCodec을 audio encoder로 채택함
- 여기서 EnCodec의 Residual Vector Quantization (RVQ) module로 인해 speech token은 hierarchical structure를 가짐
- Low-level residual quantizer는 speaker identity, coarse-grained content information과 같은 acoustic attribute를 recover 하고, 나머지 successive quantizer는 finer acoustic detail을 학습함
- 이후 각 quantizer는 lower-layer quantizer의 residual을 계산함
- EnCodec encoder는 24kHz input waveform을 75Hz discrete token으로 변환해 sampling rate를 $1/320$으로 줄임
- 각 frame은 1024 entry를 포함하는 8개의 hierarchical quantizer가 있는 RVQ module을 사용하여 represent 됨
- 이때 EnCodec encoder는 24kHz waveform의 각 초마다 $75\times 8$ entry의 matrix를 audio discrete representation으로 합성
- Autoregressive Language Model
- EnCodec RVQ의 first quantizer에서 얻어진 discrete token은 autoregressive language model을 training 하는 데 사용됨
- 이때 target text sequence와 acoustic token을 condition으로 first residual quantizer에서 subsequent codeword를 예측하는 것을 목표로 함 - Transcribed text sequence를 $\mathcal{X}$, $\mathcal{A}_{:,1}$을 speech $\mathcal{S}$에서 추출된 first quantizer의 acoustic token이라고 하자
- 그러면 TacoLM의 autoregressive prediction은:
(Eq. 1) $P(\mathcal{A}_{:,1}|\mathcal{X};\theta_{AR})=\prod_{t=1}^{T}p(\mathcal{A}_{t,1}| \mathcal{X},\mathcal{A}_{<t,1};\theta_{AR})$
- EnCodec RVQ의 first quantizer에서 얻어진 discrete token은 autoregressive language model을 training 하는 데 사용됨
- Non-autoregressive Language Model
- Autoregressive lanugage model을 통해 first quantizer의 codeword를 얻은 다음, 나머지 second quantizer부터 마지막 quantizer까지의 discrete token을 예측하기 위해 non-autoregressive model을 training 함
- 여기서 non-autoregressive language model의 prediction goal은:
(Eq. 2) $P(\mathcal{A}_{:,2:8}|\mathcal{X};\theta_{NAR})=\prod_{l=2}^{8}p(\mathcal{A}_{:,l} | \mathcal{X},\mathcal{A}_{:,<l};\theta_{NAR})$ - 해당 non-autoregressive language model은 8개의 independent acoustic embedding layer를 가짐
- First $l-1$ layer의 discrete speech token은 sum 되어 $l$-th quantizer의 token을 예측하기 위한 input으로 사용됨
- Gated Attention
- TacoLM은 Gated Prefix Self-Attention (GPSA) layer와 Gated Cross-Attention (GCA) layer를 포함하는 gated attention mechanism을 기반으로 핵심 구조인 autoregressive decoder-only network를 설계함
- Gated Prefix Self-Attention (GPSA) layer
- TacoLM의 autoregressive language model의 decoder-only network는 MEGA module을 통해 기존의 multi-head attention을 대체하여 사용함
- 이때 MEGA는 exponential moving average (EMA)를 전체 sequence의 attention mechanism에 결합하는 것을 목표로 함
- 결과적으로 single-head gated attention으로 인해 MEGA는 multi-head attention에 비해 높은 efficiency를 가짐 - 따라서 논문에서는 text prefix에 대해 bidirectional self-attention을 적용한 다음, audio 생성의 causality를 보장하기 위해 discrete speech token에 대해 unidirectional self-attention을 사용함
- Gated Cross-Attention (GCA) layer
- Decoder-only causal language model에서는 source/target sequence 모두에서 unidirectional attention이 사용되므로 traget sequence length가 길어질수록 source sequence에 대한 attention focus는 작아짐
- 특히 discrete speech LM에서 해당 attention degradation은 long sequence에 대한 text mismatch로 이어짐 - 따라서 논문은 GPSA layer 다음에 GCA layer를 추가하여 위 문제를 해결
- 여기서 GCA는 text sequence에 대한 key, value matrix와 acoustic sequence에 대한 query matrix를 계산함 - 이를 통해 key matrix는 target audio sequence의 growth에 영향을 받지 않게 되므로, text에 focus 하여 attention degradation 문제를 해결할 수 있음
- Decoder-only causal language model에서는 source/target sequence 모두에서 unidirectional attention이 사용되므로 traget sequence length가 길어질수록 source sequence에 대한 attention focus는 작아짐
- Gated Prefix Self-Attention (GPSA) layer

- Inference
- 추론 시에는 BPE를 사용하여 text transcription을 discrete codeword sequence로 encoding 하고, recorded audio prompt를 EnCodec encoder를 통해 acoustic matrix로 변환함
- AR model의 경우, beam search를 사용하면 language model이 infinite loop에 빠질 수 있고, greedy decoding은 unstable 하므로 sample-based decoding을 채택함
- 해당 sample-based decoding은 speech output의 diversity를 크게 향상할 수 있음 - NAR model의 경우, greedy decoding을 통해 highest probability를 가지는 token을 select 함
- 최종적으로 TacoLM은 neural codec decoder를 사용하여 8개의 residual quantizer codeword의 sequence에 따라 condition 된 waveform을 합성
- AR model의 경우, beam search를 사용하면 language model이 infinite loop에 빠질 수 있고, greedy decoding은 unstable 하므로 sample-based decoding을 채택함
3. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : VALL-E
- Results
- Zero-shot TTS 성능 측면에서 TacoLM이 VALL-E 보다 뛰어난 성능을 달성함

- Model size와 속도 측면에서도 TacoLM이 더 효율적임
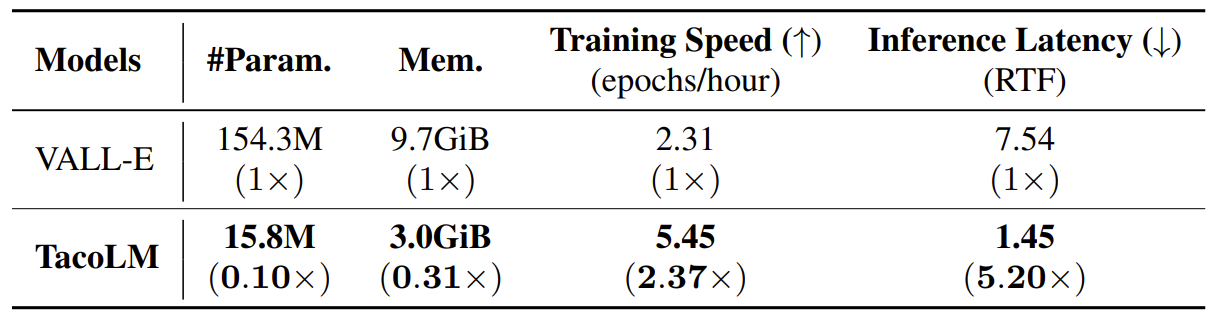
- Ablation study 측면에서 GCA와 GPSA를 제거하는 경우 성능 저하가 발생했음

반응형
'Paper > Language Model' 카테고리의 다른 글
댓글