
 [Paper 리뷰] PL-TTS: A Generalizable Prompt-based Diffusion TTS Augmented by Large Language Model
[Paper 리뷰] PL-TTS: A Generalizable Prompt-based Diffusion TTS Augmented by Large Language Model
PL-TTS: A Generalizable Prompt-based Diffusion TTS Augmented by Large Language ModelStyle-controlled Text-to-Speech를 위해 text style description을 사용할 수 있음PL-TTSLarge Language Model로 embed 된 prompt와 diffusion-based Text-to-Speech model을 결합추가적으로 합성 품질과 style controllability를 향상하기 위해 Large Language Model과 diffusion framework를 fine-tuning논문 (INTERSPEECH 2024) : Paper Link1. IntroductionControllable ex..
 [Paper 리뷰] ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech Synthesis
[Paper 리뷰] ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech Synthesis
ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech SynthesisText-to-Speech model에서 code-mixed text는 speaker-related feature에 source language에 대한 linguistic feature가 포함될 수 있으므로 unnatural accent를 생성할 수 있음ClariTTSFlow-based text-to-speech model에 Feature-ratio Normalized Affine Coupling Layer를 적용- Speaker와 linguistic feature를 disentangle 하여 target sp..
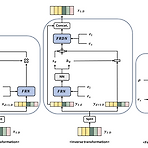
 [Paper 리뷰] VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-Speech
[Paper 리뷰] VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-Speech
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-SpeechPre-trained diffusion-based model에 personalized adapter를 결합하여 parameter-efficient speaker adaptive Text-to-Speech를 수행할 수 있음VoiceTailorParameter-Efficient Adaptation을 위해 Low-Rank Adaptation을 활용하고 adapter를 pre-trained diffusion decoder의 pivotal module에 통합Few parameter 만으로 강력한 adaptation을 달성하기 위해 guidance techni..
 [Paper 리뷰] UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed Data
[Paper 리뷰] UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed Data
UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed DataMinimal untranscribed data를 사용하여 diffusion-based text-to-speech model을 fine-tuning 할 수 있음UnitSpeechSelf-supervised unit representation을 pseudo transcript로 사용하고 unit encoder를 pre-trained text-to-speech model에 integrate 함Unit encoder를 training 하여 diffusion-based decoder에 speech content를 제공한 다음, single $\langle \text{unit},\text{s..
 [Paper 리뷰] Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
[Paper 리뷰] Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
Fast DCTTS: Efficient Deep Convolutional Text-to-SpeechSingle CPU에서 real-time으로 동작하는 end-to-end text-to-speech model이 필요함Fast DCTTS다양한 network reduction과 fidelity improvement technique을 적용한 lightweight networkGating mechanism의 efficiency와 regularization effect를 고려한 group highway activation을 도입추가적으로 output mel-spectrogram의 fidelity를 측정하는 Elastic Mel-Cepstral Distortion metric을 설계논문 (ICASSP 2021) ..
 [Paper 리뷰] EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-Speech
[Paper 리뷰] EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-Speech
EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-SpeechEmotional text-to-speech를 위해 대부분은 emotion label이나 reference audio에 의존함- BUT, utterance-level emotion condition으로 인해 expression이 monotonous 하다는 한계가 있음EmoQ-TTSFine-grained emotion intensity와 phoneme-wise emotion information을 conditioning하여 expressive speech를 합성Emotion intensity는 human labeling 없이 distanc..