

 [Guide] 일본 슈게이즈/드림팝 가이드
[Guide] 일본 슈게이즈/드림팝 가이드
일본 슈게이즈/드림팝 가이드 듣는 사람만 듣는(?) 마이너한 장르지만, 찰랑거리는 소녀감성에서부터 파괴적인 블랙게이즈까지, 영미권과는 완전히 다른 일본 슈게이즈 만의 고유한 매력이 있습니다. 하지만 생각보다 탄탄한 일본 슈게이즈씬을 무작정 파고들기에는 쉽지 않습니다. 그래서 를 통해 그런 입문자들의 부담을 줄이고 장르의 매력에 쉽게 빠져들 수 있도록 하려고 합니다. + 일본 슈게이즈/드림팝 가이드는 지속적으로 업데이트 됩니다. 일본 슈게이즈 / 드림팝 플로우차트 일본 슈게이즈 입문은 Supercar부터 시작 색깔별 스타일 구분 빨강 : 슈게이즈 파생 (My Bloody Valentine 류) 파랑 : 얼터너티브락 파생 (Ride 류) 초록 : 드립팝 파생 (Slowdive 류) 주황 : For Tracy..
 [Paper 리뷰] Hierarchical Diffusion Models for Singing Voice Neural Vocoder
[Paper 리뷰] Hierarchical Diffusion Models for Singing Voice Neural Vocoder
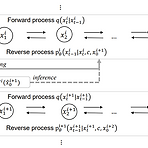
Hierarchical Diffusion Models for Singing Voice Neural Vocoder Pitch, loudness, pronunciation 같은 다양한 음악적 표현으로 인해 neural vocoder로 고품질의 가창 음성을 합성하는 것은 어려움 서로 다른 sampling rate에 대한 multiple diffusion model을 도입 HPG (Hierarchical Diffusion Model + PriorGrad) Lower sampling rate 모델은 pitch와 같은 저주파 요소를 합성 다른 모델은 lower sampling rate와 acoustic feature를 기반으로 higher sampling rate waveform을 점진적으로 합성 논문 (ICASS..
 [Paper 리뷰] Attention-based Neural Network for End-to-End Music Separation
[Paper 리뷰] Attention-based Neural Network for End-to-End Music Separation
Attention-based Neural Network for End-to-End Music Separation End-to-End separation은 speech separation 분야에서 우수한 성능을 보였지만 music separation에서는 아직 접목되지 않음 Sampling rate가 높은 dual channel data인 음악 신호를 모델링하기 위한 적절한 방법이 필요 Attention-based End-to-End Music Separation 멜로디, 톤과 같은 음악의 장기적인 특성을 캡처하기 위한 densely connected U-Net Separation module에 multi-head attention과 dual-path transformer를 적용 논문 (CAAI 2023)..
 [Paper 리뷰] On Loss Functions and Evaluation Metrics For Music Source Separation
[Paper 리뷰] On Loss Functions and Evaluation Metrics For Music Source Separation
On Loss Functions and Evaluation Metrics For Music Source Separation Music source separation을 위해 어떤 loss function이 효과적인 분리를 제공하는지 조사 대표적인 Audio source separation loss들을 포함한 벤치마킹 평가 Signal-to-Distortion ratio를 대체할 수 있는 평가 지표를 조사 논문 (ICASSP 2022) : Paper Link 1. Introduction Music source separation은 혼합된 오디오 신호에서 원래 신호를 복구하는 것을 목표로 함 대부분의 Music source separation은 time-frequency domain에서 동작하는 회귀모델을 ..
 [Paper 리뷰] FC-U$^{2}$-Net: A Novel Deep Neural Network for Singing Voice Separation
[Paper 리뷰] FC-U$^{2}$-Net: A Novel Deep Neural Network for Singing Voice Separation
FC-U$^{2}$-Net: A Novel Deep Neural Network for Singing Voice Separation 혼합된 음악 신호에서 보컬과 반주(accompainment)를 분리하는 가창 음성 분리를 위한 신경망 FC-U$^{2}$-Net 주파수 축을 따라 Time-invariant fully connected layer가 추가된 2단계 중첩 U-Net 구조 Local/Global contextual information 및 주파수 축에 대한 음성 신호의 장거리 상관관계를 캡처 깨끗한 보컬 분리를 위한 ratio mask, binary mask를 결합한 loss function의 사용 논문 (TASLP 2022) : Paper Link 1. Introduction 가창 음성 분리(Si..
 [Paper 리뷰] StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
[Paper 리뷰] StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks Style transfer의 개념을 빌린 Generative Adversarial Network (GAN)을 위한 generator architecture High level attributes와 stochastic variation에 대한 unsupervised separation을 학습하여 이미지 합성에 대한 scale-specific control을 제공 StyleGAN 기존의 distribution quality metric에 대해 SOTA 성능을 달성 더 나은 interpolation property 및 latent factor variation에 ..