

 [Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
[Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
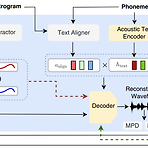
StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language ModelsHuman-level text-to-speech를 위해 large speech language model (SLM)을 활용할 수 있음StyleTTS2Diffusion model을 통해 style을 latent random variable로 모델링하여 reference speech 없이 text에 적합한 style을 생성End-to-End training을 위해 differentiable duration modeling이 가능한 discriminator를 도입하고 large pre..
 [Paper 리뷰] P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting
[Paper 리뷰] P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting
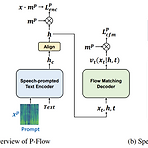
P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech PromptingNeural codec language model은 대규모의 data를 학습하여 zero-shot text-to-speech 성능을 크게 향상함- BUT, robustness가 부족하고, sampling 속도가 매우 느리고, pre-trained neural codec representation에 의존적임P-FlowSpeaker adaptation을 위해 speech prompt를 사용하는 빠르고 data-efficient 한 zero-shot text-to-speech 모델Speech-prompted text encoder와 flow matching generative dec..
 [Paper 리뷰] TriniTTS: Pitch-Controllable End-to-End TTS without External Aligner
[Paper 리뷰] TriniTTS: Pitch-Controllable End-to-End TTS without External Aligner
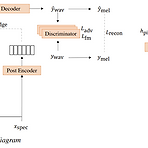
TriniTTS: Pitch-Controllable End-to-End TTS without External AlignerEnd-to-End architecture, prosody control, on-the-fly duration alignment를 모두 만족하는 text-to-speech 모델이 필요함- 대부분 two-stage pipeline에 의존적이고 controllability가 부족하기 때문TriniTTSExternal aligner 없이 pitch control이 가능한 end-to-end text-to-speech 모델Alignment search, pitch estimation, waveform generation을 동시에 수행하여 음성의 data 분포를 나타내는 latent vecto..
 [Paper 리뷰] AdaSpeech: Adaptive Text to Speech for Custom Voice
[Paper 리뷰] AdaSpeech: Adaptive Text to Speech for Custom Voice
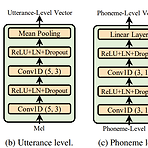
AdaSpeech: Adaptive Text to Speech for Custom Voice TTS adaptation에서 custom voice를 활용하기 위해서는 2가지 과제가 있음 - Adaptation 모델은 source speech data와 상당히 다른 다양한 acoustic condition을 처리할 수 있어야 함 - 음성 품질을 유지하면서 적은 memory 사용량을 가지도록 각 target speaker에 대한 adaptation parameter가 작아야 함 AdaSpeech 고품질 합성과 효율적인 voice customization을 지원하는 adaptive TTS 모델 다양한 acoustic condition을 처리하기 위해 utterance, phoneme level 모두에서 aco..
 [Paper 리뷰] nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-Speaker Text-to-Speech
[Paper 리뷰] nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-Speaker Text-to-Speech
nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-Speaker Text-to-Speech Multi-speaker text-to-speech를 활용하기 위해서는 어려움이 많음 nnSpeech Fine-tuning 없이 하나의 adpatation utterance만을 사용하여 새로운 speaker voice를 합성할 수 있는 zero-shot multi-speaker 모델 Speaker-guided conditional vairational autoencoder를 활용하여 speaker, content information을 모두 포함하는 variable $Z$를 생성 Latent variable $Z$의 분포..
 [Paper 리뷰] SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-to-Speech Model
[Paper 리뷰] SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-to-Speech Model
SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-to-Speech Model Unseen speaker에 대한 similarity를 향상하는 zero-shot text-to-speech 모델이 필요함 SC-GlowTTS Flow-based decoder를 기반으로 speaker-conditional architecture를 도입 Text encoder로써 dilated residual convolutional-based encoder, gated convolutional-based encoder, transformer-based enocoder를 비교 추가적으로 text-to-speech 모델을 통해 예측된 spectrogram에 대해 GAN-based v..