

티스토리 뷰
Paper/ETC
[Paper 리뷰] Pareto-aware Neural Architecture Generation for Diverse Computational Budgets
feVeRin 2024. 1. 6. 12:46반응형
Pareto-aware Neural Architecture Generation for Diverse Computational Budgets
- 다양한 computational budget 하에서 효과적인 architecture를 설계하는 것은 배포에 필수적임
- 기존에는 주로 각 target budget에 대해 독립적인 architecture search를 수행
- 비효율적이고, 학습된 knowledge를 서로 공유할 수 없음 - Pareto-aware Neural Architecture Generator (PNAG)
- 단일 학습만으로 주어진 budget에 대해 Pareto-optimal architecture를 동적으로 생성
- 다양한 budget에서 multiple Pareto-optimal architecture를 jointly finding 하여 전체 Pareto-frontier를 학습
- Joint search algorithm을 통해 전체 검색 비용을 줄이고 검색 결과를 향상
- 논문 (CVPR 2023) : Paper Link
1. Introduction
- 효과적인 architecutre 설계는 전문가에게 크게 의존함
- 이를 극복하기 위해 architecture를 자동으로 설계하는 Neural Architecture Search (NAS)가 제안됨
- NAS를 통한 자동 탐색은 수동 설계 architecture 보다 뛰어난 성능을 발휘할 수 있음 - Neural network는 많은 양의 parameter로 인해 계산 비용이 높음
- 제한된 computing resource에 대해 모델을 배포하기 어려움
- 이를 극복하기 위해 architecture를 자동으로 설계하는 Neural Architecture Search (NAS)가 제안됨
- 결과적으로 특정한 computational budget을 만족할 수 있는 architecture 설계가 요구됨
- 실행 가능한 architecture 설계를 위해 주로 single computational budget 만을 고려하는 경우가 많음
- 다양한 budget을 고려하기 위해서는 각 budget에 대해 독립적인 search process를 수행해야하는 단점 - Population-based method를 활용하여 여러 architecture를 동시에 찾은 다음, 적절한 architecture를 선택할 수도 있음
- 제한된 population size로 인해 탐색된 architecture가 budget을 충족하지 않을 수 있음
- 탐색 이후에 architecture가 수정되면, budget이 조금이라도 변경되었을 때 쉽게 적응할 수 없음
- 실행 가능한 architecture 설계를 위해 주로 single computational budget 만을 고려하는 경우가 많음
-> 그래서 다양한 budget 하에서 효율적이고 유연하게 architecture를 설계할 수 있는 Pareto-aware Architecture Generation을 제안
- Pareto-aware Neural Architecture Generator (PNAG)
- 한 번의 학습만으로 추론을 통해 다양한 budget에 맞는 Pareto-optimal architecture를 생성하는 generator
- Pareto-optimal architecture는 모델 성능과 계산 비용에 대한 Pareto-frontier 위에 존재함
- Predefine된 분포에서 무작위로 budget을 sampling 하고 탐색된 architecture의 expected reward를 최대화하여 Pareto-frontier에 근사 시킴 - Pareto-frontier 학습을 통해 학습된 knowledge를 다양한 budget에 대해 공유하고, 탐색 결과를 향상 가능
< Overall of PNAG >
- 효율적이고 유연한 architecture 생성을 지원하는 Pareto-aware Neural Architecture Generator
- 다양한 budget에 대해 탐색된 architecture의 expected reward를 최대화하여 Pareto-frontier를 명시적으로 학습
- 주어진 budget에 따라 architecture를 적응적으로 평가할 수 있는 architecture evaluator를 도입
- 결과적으로 다른 NAS 방법론들에 비해 다양한 budget과 platform에 대해 뛰어난 성능을 달성

2. Pareto-aware Architecture Generation
- PNAG는 search/training 대신 추론을 통해 다양한 budget에 맞는 효과적인 architecture를 생성하는 것이 목표
- 다양한 budget 하에서, 최적의 architecture는 모델 성능과 계산 비용에 대한 Pareto-frontier에 위치함
- 따라서, PNAG는 전체 Pareto-frontier를 명시적으로 학습하는 것을 목표로 함 - Budget을 input으로 사용하고 그에 맞는 architecture를 생성하는 conditional model로 PNAG를 구축
- 다양한 budget 하에서, 최적의 architecture는 모델 성능과 계산 비용에 대한 Pareto-frontier에 위치함
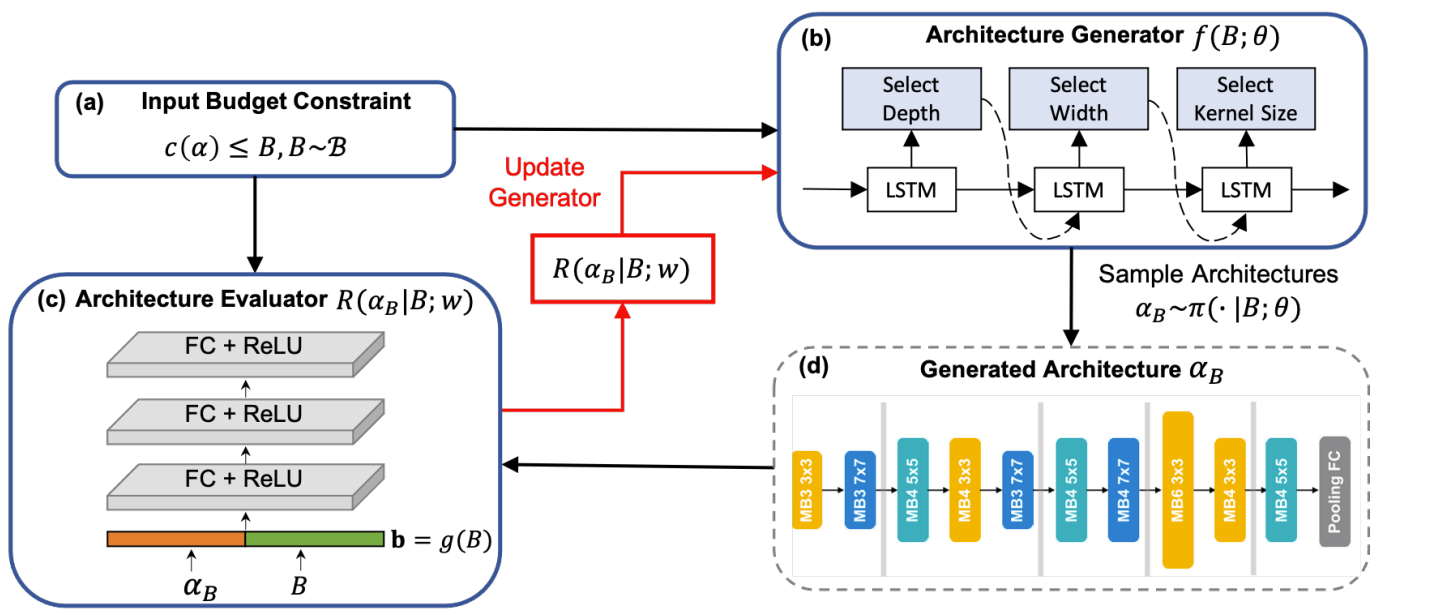
- Learning the Architecture Generator $f(B; \theta)$
- 주어진 computational budget에 맞는 효과적인 architecture를 생성할 수 있는 architecture generator 모델을 구축하는 것을 목표로 함
- Random variable을 고려할 수 있는 분포 $\mathcal{B}$에서 추출한 budget $B$ (latency / MAdds)가 있을 때,
- 모든 architecture $\alpha \in \Omega$에 대해 $c(\alpha)$와 $Acc(\alpha)$를 사용하여 $\alpha$의 cost와 vaildation accuracy를 측정할 수 있음
- $B \sim \mathcal{B}$이고, $\Omega$ : architecture search space
- Architecture는 token sequence로 표현될 수 있으므로, (각 token은 depth, width, kernel size 같은 layer setting을 나타냄)
- Architecture 생성을 sequential decision problem으로 두고 LSTM network를 사용하는 architecture generator $f(B;\theta)$ 모델을 구축
- Generator는 budget $B$를 input으로 사용하고 token sequence를 순차적으로 예측하여, 제약조건 $c(\alpha_{B} \leq B)$를 만족하는 architecture $\alpha_{B} = f(B; \theta)$를 생성
- $\theta$ : learnable parameter - 이때, 특정 budget하에서 최적 architecture는 모델 성능 및 계산 비용에 대한 Pareto-frontier에 위치해야 함
- Generator가 임의의 budget에 대해 일반화될 수 있도록 Pareto-frontier를 학습하는 것이 필요
- Training Method of $f(B ; \theta)$
- NAS under a single budget
- 최적의 architecture를 직접 찾는 것은 non-trivial 하기 때문에, policy $\pi(\cdot; \theta)$를 학습한 다음, sampling을 수행하여 유망한 architecture를 탐색함 ($\alpha \sim \pi(\cdot; \theta)$)
- Budget $B$가 주어졌을 때, optimization problem은:
$max_{\theta} \, \mathbb{E}_{\alpha \sim \pi(\cdot ; \theta)} [ R(\alpha | B; w)], \,\, s.t. \,\, c(\alpha) \leq B$
- $\pi(\cdot;\theta)$ : $\theta$에 의해 parameterize 되는 learend policy
- $R(\alpha | B; w)$ : architecture $\alpha$의 accuracy와 latency에 대한 joint performance를 측정한 $w$로 parameterize되는 reward function
- $\mathbb{E}_{\alpha \sim \pi (\cdot;\theta)}$ : 탐색된 architecture의 기댓값
- NAS under diverse budgets
- 전체 budget 범위에 대한 Pareto-frontier를 학습하는 것은, 서로 다른 computational cost에 대해 무한한 Pareto-optimal architecture가 존재할 수 있기 때문에 어려움
-> 이를 해결하기 위해, uniform 하게 분포된 Pareto-optimal point들을 찾아 근사 Pareto-frontier를 학습할 수 있음 - Latency 범위에서 $K$개의 budget을 균등 sampling 하고 그에 대한 expected reward를 최대화했을 때, 최종적인 optimization problem은:
$max_{\theta} \, \mathbb{E}_{B \sim \mathcal{B}} \left [ \mathbb{E}_{\alpha_{B} \sim \pi (\cdot | B;\theta)} [ R (\alpha_{B} | B; w) ] \right ]$
$s.t. \,\, c(\alpha_{B}) \leq B, \, B\sim \mathcal{B}$
- $\mathbb{E}_{B \sim \mathcal{B}} [\cdot] $ : budget 분포에 대한 기댓값
- $\pi(\cdot | B;\theta) $ : budget $B$를 condition으로 한 learned policy - Architecture generator를 학습하기 위해 policy gradient를 사용하고, entropy regularization을 도입
- 전체 budget 범위에 대한 Pareto-frontier를 학습하는 것은, 서로 다른 computational cost에 대해 무한한 Pareto-optimal architecture가 존재할 수 있기 때문에 어려움
- Advantages over existing NAS methods
- PNAG는 기존 NAS 방법론들에 비해 2가지 장점을 가짐
1. PNAG는 다양한 budget으로 search process 전체에 걸쳐 learned knowledge를 공유할 수 있음
- 일단 budget을 만족하는 architecture를 찾으면, width, kernel size 등을 약간 수정하여 더 크거나 작은 budget에 맞는 architecture를 쉽게 얻을 수 있기 때문
2. 잘 학습된 PNAG가 있으면 추론을 통해 필요한 budget에 대한 architecutre를 생성할 수 있음
- PNAG는 기존 NAS 방법론들에 비해 2가지 장점을 가짐

- Vector Representation of Budget Bounds
- Architecture generator를 학습하기 위해서는, budget bound $B$를 PNAG를 input으로 표현할 수 있어야 함
- PNAG는 학습 과정에서 $K$개의 discrete budget을 고려함
- 서로 다른 budget을 나타내기 위해, embedding vector를 활용 - 각 sampling budget $B$에 대해 learnable embedding vector $b=g(B)$를 사용
- 해당 learnable embedding vector를 architecture generator의 parameter에 통합하고 같이 학습시킴
-> 결과적으로 여러 budget에 대한 vector를 학습시켜 PNAG가 적절한 architecture를 생성할 수 있음
- PNAG는 학습 과정에서 $K$개의 discrete budget을 고려함
- PNAG를 학습할 때, discrete budget을 sampling 함
- Continuous space에 대한 budget을 활용하기 위해, embedding interoplation method를 활용
- 2개의 adjacent discrete budget의 embedding 사이의 linear interpolation을 수행 - 2개의 sampling 된 budget $B_{1} < B < B_{2}$ 사이의 traget budget vector $b$에 대한 linear interpolation은:
$b = g(B) = \xi g(B_{1}) + (1-\xi)g(B_{2})$
- $\xi = \frac{B_{2} - B}{B_{1}-B}$, $\xi \in [0,1]$
- Continuous space에 대한 budget을 활용하기 위해, embedding interoplation method를 활용
- Learning the Architecture Evaluator $R(\cdot | B; w)$
- 다양한 budget이 주어지면, architecture는 해당 budget 제약을 만족하는지 여부에 대한 reward/score를 가져야 함
- 각 budget에 대한 reward를 설계하는 것을 어렵기 때문에, score를 예측하는 architecture evaluator를 도입
- 이때, evaluator는 fully-connected layer 3개로 구성됨 - Architecture $\beta$와 budget $B$가 주어졌을 때, 성능 $R(\beta | B;w)$를 예측
- Ground-truth label이 없기 때문에, pairwise architecture comparison을 통해 evaluator를 학습함
- 각 budget에 대한 reward를 설계하는 것을 어렵기 때문에, score를 예측하는 architecture evaluator를 도입
- Training Method of $R(\cdot | B; w)$
- Evaluator 학습을 위해 pairwise ranking loss를 활용
- Accuracy와 latency를 가지는 $M$개의 architecture를 수집하여 tirplet set $\{ (\beta_{i}, c(\beta_{i}), Acc(\beta_{i})) \}^{M}_{i=1}$로 두면,
- $M$개 architecture가 주어졌을 때, 자기 자신을 생략하고 총 $M(M-1)$개의 architecture pair $\{ (\beta_{i}, \beta_{j}) \}$를 가짐 - 이때, $K$개의 budget 있다면 pairwise ranking loss는:
$L(w) = \frac{1}{KM(M-1)} \sum^{K}_{k=1} \sum^{M}_{i=1} \sum^{M}_{j=1, j \neq i} \phi \left ( d(\beta_{i}, \beta_{j}, B_{k}) \cdot [ R(\beta_{i} | B_{k} ; w) - R(\beta_{j} | B_{k} ; w)] \right )$
- $d(\beta_{i}, \beta_{j}, B_{k})$ : budget $B_{k}$ 하에서 $\beta_{i}$가 $\beta_{j}$보다 나은지를 판별하는 함수
- $\phi(z) = max(0, 1, -z)$ : 예측 ranking $R(\beta_{i} | B_{k};w) - R(\beta_{j} | B_{k};w)$ 이 Pareto-dominance rule에 의해 얻어진 $d(\beta_{i}, \beta_{j}, B_{k})$와 일치되도록 강제하는 hinge loss
- Accuracy와 latency를 가지는 $M$개의 architecture를 수집하여 tirplet set $\{ (\beta_{i}, c(\beta_{i}), Acc(\beta_{i})) \}^{M}_{i=1}$로 두면,
- Pareto Dominance Rule
- Architecture 간의 성능을 비교할 수 있는 $d(\beta_{1}, \beta_{2}, B)$를 정의해야 함
- 이를 위해, Pareto-dominance를 활용
- Pareto-dominance는 architecutre의 품질이 budget과 accuracy 모두를 만족해야 할 것을 요구함
-> 즉, 특정 budget $B$ 하에서 좋은 architecture는, cost가 $B$ 보다 낮거나 같으면서 accuracy가 높아야 함 - 임의의 두 architecture $\beta_{1}, \beta_{2}$가 주어지고, 둘 다 budget 제약 조건 ($c(\beta_{1}) \leq B, c(\beta_{2}) \leq B$)을 만족하는 경우,
- $Acc(\beta_{1}) \geq Acc(\beta_{2})$ 이면 $\beta_{1}$이 $\beta_{2}$를 dominate 함
- 특히 $\beta_{1}, \beta_{2}$ 중 적어도 하나가 budget 제약을 위반할 때, $c(\beta_{1}) \leq c(\beta_{2})$이면 $\beta_{1}$이 $\beta_{2}$를 dominate 함 - 이에 따라, Pareto-dominance function $d(\beta_{1}, \beta_{2}, B)$는:
- $\beta_{1} \neq \beta_{2}$이면, $d(\beta_{1}, \beta_{2}, B) = - d(\beta_{2}, \beta_{1}, B)$이 되어 symmetric
- 이를 위해, Pareto-dominance를 활용
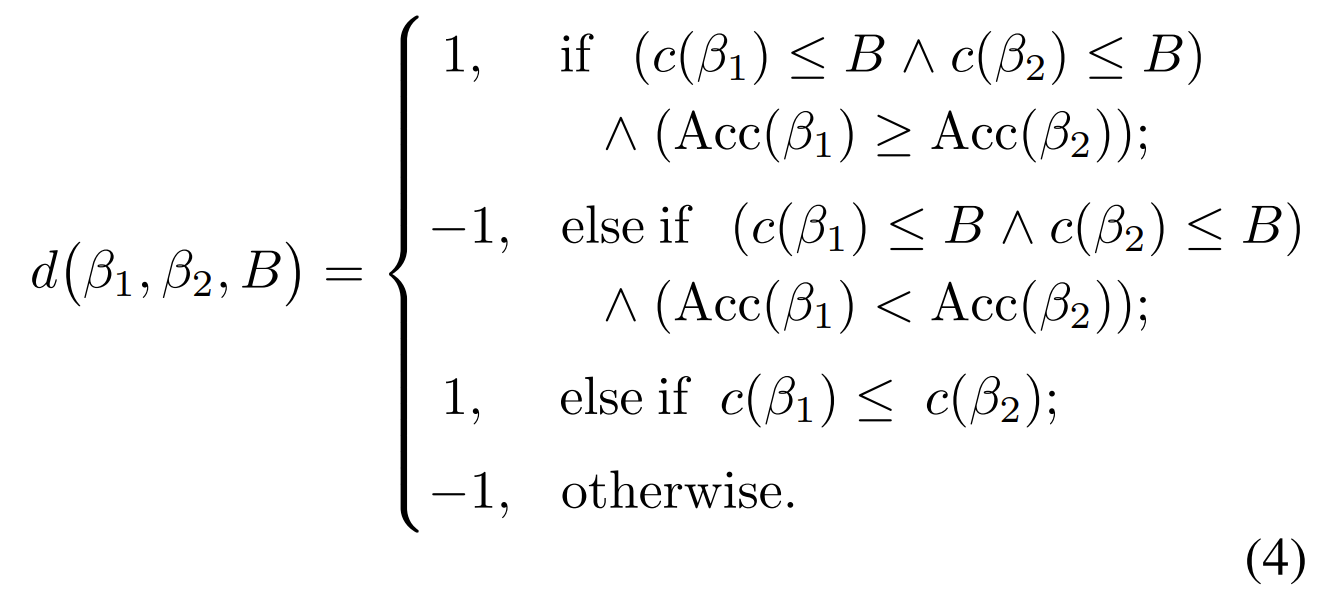
3. Experiments
- Settings
- Search Space : MobileNetV3
- PNAG variants : EVO (evolutionary search), NAS-MO (multi-objective NAS)
- Comparisons : OFA, FBNet, ProxylessNAS, DARTS
- Architecture Search for Mobile Devices
- Mobile device (Qualcomn Snapdragon 821)에 대한 architecture를 생성을 실험
- PNAG는 budget interpolation method를 활용해 임의의 budget에 대해 실행 가능한 architecture를 생성
- 5개의 latency budget $\{80ms, 110ms, 140ms, 170ms, 200ms \}$에 대한 결과를 비교 - Accuracy와 latency 측면에서 PNAG는 다양한 budget 하에서 EVO, NAS-MO 보다 더 나은 architecture를 생성 가능
- 특히 PNAG를 통해 얻어진 최고 성능의 architecture는 OFA로 얻어진 architecture 보다 accuracy, latency에 대해 더 우수한 trade-off를 제공
- PNAG는 budget interpolation method를 활용해 임의의 budget에 대해 실행 가능한 architecture를 생성

- 다양한 latency budget들을 고려했을 때, PNAG는 generate/search 된 architecture의 accuracy 측면에서 다른 NAS 방법론들보다 우수한 성능을 보임
- PNAG-200은 80.5%의 accuracy를 보여 OFA 보다 우수한 성능을 보임
- 이때 PNAG의 총 학습비용은 0.7 GPU day로 기존 방법들보다 훨씬 효율적임

- Pareto-frontier를 비교해 보면, PNAG는 다양한 budget하에서 NAS-MO보다 더 나은 frontier를 찾을 수 있음
- PNAG는 search process 전반에 걸쳐 shared knowledge를 활용하기 때문

- Mobile device에서의 architecutre의 latency histogram을 확인해 보면,
- NAS-MO의 경우 110ms, 140ms의 latency를 만족하는 architecture를 생성하지 못함
- PNAG는 Pareto-dominance reward를 활용하여 architecture가 원하는 latency budget을 충족하도록 할 수 있음
- 결과적으로 PNAG를 통해 얻어진 architecture들은 target budget을 만족함

- Further Experiments
- Effect of the Pareto Dominance Reward
- Pareto-frontier learning은 shared knowledge로 인해 더 나은 architecture를 찾을 수 있음
- Multi-objective reward와 비교했을 때, Pareto-dominance reward는 generator가 budget 제약을 만족하는 architecture를 생성하도록 함
- Accuracy 제약을 고려하지 않은 경우, architecture의 latency는 짧아지지만 accuracy가 낮아짐


- Comparisons of Architecture Generation Cost
- PNAG는 전체 Pareto-frontier를 직접 학습하기 때문에, 학습된 generator를 기반으로 추론을 통해 최적의 architecture를 생성할 수 있음
- 결과적으로 PNAG의 architecture 생성 비용은 다른 NAS 방법론들보다 훨씬 낮음

- Effect of $K$ on the Generation Performance
- $K \in \{ 2,5,10,30 \}$에서 $K$가 PNAG에 주는 영향을 비교
- 적은 budget은 충분한 shared knowledge를 활용할 수 없기 때문에 ground-truth Pareto-frontier를 정확하게 근사할 수 없음
- $K$가 5보다 큰 경우 생성되는 architecture의 성능이 크게 향상됨

반응형
'Paper > ETC' 카테고리의 다른 글
댓글