

티스토리 뷰
Paper/ETC
[Paper 리뷰] CompOFA: Compound Once-For-All Networks for Faster Multi-Platform Deployment
feVeRin 2023. 8. 1. 11:43반응형
CompOFA: Compound Once-For-All Networks for Faster Multi-Platform Deployment
- Once-For-All (OFA)는 Neural Architecture Search (NAS)에서 한 번에 여러 모델을 학습시킬 수 있는 방식을 제안함
- OFA를 적용하더라도 NAS 비용은 여전히 높음
- CompOFA
- Accuracy-latency Pareto frontier에 가까운 모델로 search 범위를 제한
- 더 작은 search space를 구성하기 위한 모델 magnitude 간의 compound relationship 파악
- 논문 (ICRL 2021) : Paper Link
- 해당 논문의 Baseline : Once-For-All (OFA) 리뷰
1. Introduction
- CNN은 다양한 hardware, workload에 배포될 수 있지만, 사용 가능한 메모리, latency 등은 platform마다 서로 다름
- Accuracy는 컴퓨팅 예산에 따라 증가하므로, 추론 latency 제약 하에서 모델의 정확도를 최대화하는 것이 중요
- 이를 만족하는 모델은 accuracy-latency trade-off의 Pareto-frontier에 가까움
- 하지만 이러한 모델을 수동으로 구축하거나 search하는 것은 여전히 소모적인 작업임
- 컴퓨팅 자원, 시간, $CO_{2}$ 배출량 등 다양한 요소들을 고려해야 함
- OFA는 Progressive Shrinking algorithm을 통해 search와 training을 분리하여 NAS의 비용 문제를 해결했음
- 한번 학습되면 특정한 deployment target에 맞는 특화된 sub-network를 추출할 수 있음
- Depth, width, kernel size, resolution에 대한 다양한 모델 구축
- Weight sharing을 통한 single-shot 학습
- 한번 학습되면 특정한 deployment target에 맞는 특화된 sub-network를 추출할 수 있음
- OFA의 큰 search space는 training 비용을 증가시킬 수 있음
- Search space는 가능한 모든 조합을 학습하는데서 많은 비용이 발생함
- 대부분의 조합은 accuracy-latency Paretor-frontier 아래에 위치함
- 큰 search space에서 accuracy, latency 기반 탐색을 비효율적으로 만드는 요인 - Sub-optimal 모델은 사용되지도 않을 뿐만 아니라, training interference를 발생시킴
- Simultaneous optimization을 안정화하기 위해 더 긴 training 시간을 필요로 하게 만듦 - 큰 search space의 모든 조합을 비교할 수 없기 때문에, accuracy, latency 측정은 간접적인 estimator를 사용할 수밖에 없음
- Search space는 가능한 모든 조합을 학습하는데서 많은 비용이 발생함
-> 그래서 OFA의 큰 search space design 문제를 해결하기 위해 compound coupling을 활용하는 CompOFA를 제안
- CompOFA
- Depth, width, resolution은 서로 orthogonal 하지 않다는 것을 활용
- 이를 따르는 차원 간의 compound coupling은 더 나은 accuracy-latency trade-off를 생성할 수 있음 - 실제 시스템 배포에는 1ms 정도의 coarser latency면 충분함
- Depth, width, resolution은 서로 orthogonal 하지 않다는 것을 활용
< Overall of CompOFA >
- Compound coupling을 활용하여 Pareto-frontier에 가까운 모델을 추출할 수 있음
- OFA의 $10^{19}$개 모델을 CompOFA에서는 243개로 줄일 수 있음 - 간소화된 search space를 통해 training interference를 줄여 학습 시간과 비용을 2배 이상 줄임
- CompOFA의 단순함을 통해 216배 더 빠른 추출 속도를 보임
- 작은 규모로도 OFA와 동일한 hardware target과 다양성을 보장할 수 있음
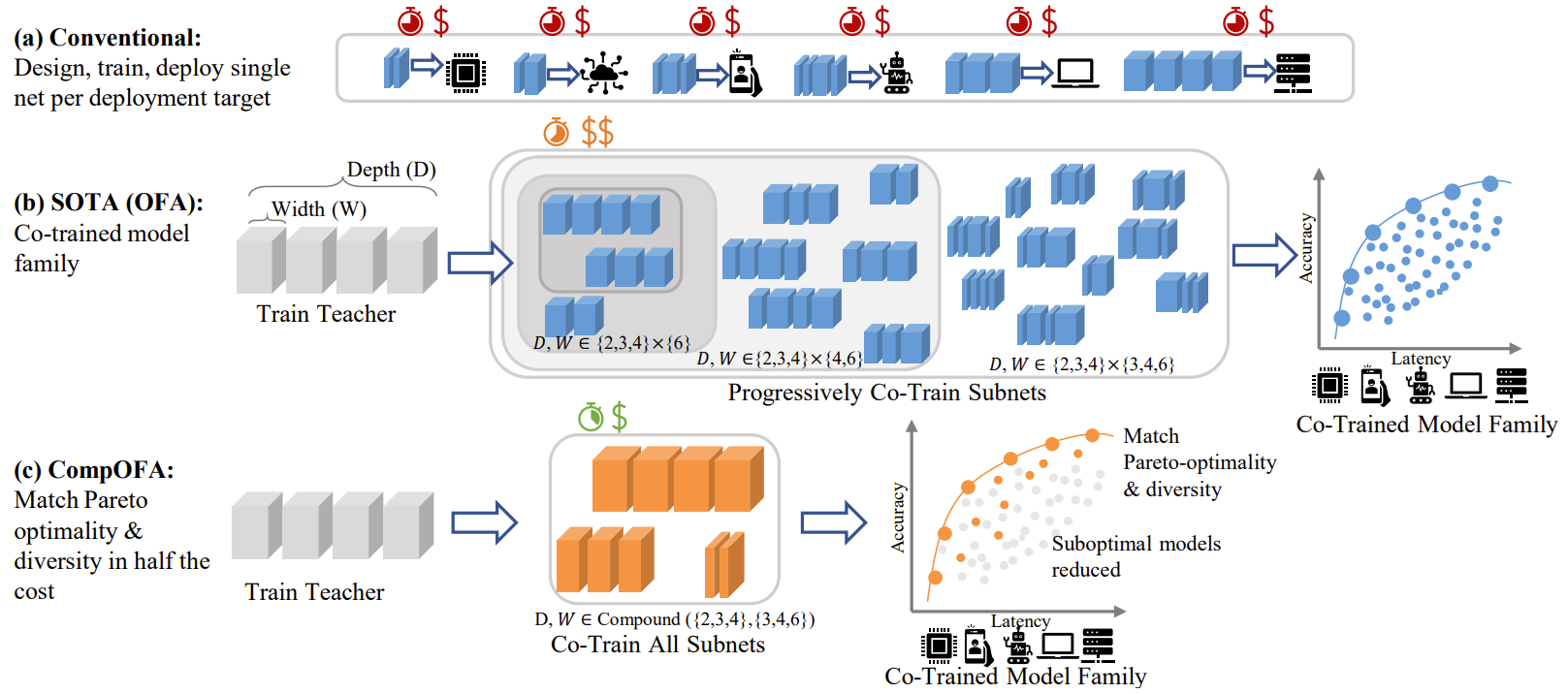
2. Motivation
- Design Space Parameterization
- $m$개의 micro-architectural block $B_{1}, B_{2}, ..., B_{m}$으로 구성된 network architecture $N$
- $B_{i}(d_{i}, W_{i}, K_{i})$ : 각 block은 depth, layer 당 width, layer 당 kernel size를 통해 parameterized
- $d_{i}$ : block의 layer 수 (depth)
- $W_{i}, K_{i}$ : 각각 $d_{i}$ layer의 Width, Kernel size
- $B_{i}(d_{i}, W_{i}, K_{i})$ : 각 block은 depth, layer 당 width, layer 당 kernel size를 통해 parameterized
- OFA는 다양한 latency, accuracy의 $N_{1}, N_{2}, ...$ network들을 가짐
- Block $B_{i}$의 channel과 공통 layer의 weight는 모든 network에서 공유됨
- OFA의 block은 MobileNetV3의 Inverted Residual이므로, width는 channel expansion ratio를 의미함 - $d_{i}, w_{ij}, k_{ij}$는 $D = [2,3,4], W = [3,4,6], K = [3,5,7]$에서 각각 sampling 됨
- Block $B_{i}$의 channel과 공통 layer의 weight는 모든 network에서 공유됨
- OFA에서 각 차원은 orthogonal 한 것으로 처리됨
- 가능한 network의 수는 $m=5$ block에 대해 $O(10^{19})$
- Compound Relation of Model Dimensions
- $D, W, K$ 3개의 독립적인 차원에서의 모델 조합은 엄청난 수의 후보 모델을 생성함
- 거대한 search space에서 가능한 모든 모델을 학습하는 것은 어려움
- 모델의 차원은 orthogonal 하지 않음
- 더 높은 FLOP에 대해 depth, width, resolution에 대한 scaling 차원은 일반적으로 사용되는 방식임
- 차원 간의 compound relation을 활용하면 최적의 accuracy-latency trade-off를 달성할 수 있음
- Compound scaling rule에 따라 모델의 차원을 늘렸을 때 더 나은 결과를 얻을 수 있음 - Depth와 width 사이의 quantized linear relation은 좋은 모델들이 많이 집중된 desing space를 생성할 수 있음
- However, 모든 차원들이 독립적으로 sampling 되면 각 sub-optimal 모델들이 search space에 포함될 수 있음
- 더 높은 FLOP에 대해 depth, width, resolution에 대한 scaling 차원은 일반적으로 사용되는 방식임
- 대규모의 search space는 training과 searching을 복잡하게 함
- OFA의 sub-network 간 interference는 simultaneous optimization을 어렵게 함
- Progressive shrinking을 추가적으로 요구하므로 학습 시간이 늘어남 - 원하는 target에 대한 accuracy, latency는 predictor를 통한 예측에 의존함
- Latency look-up table 수집, 추가적인 predictor 학습 등을 필요로 하므로 전체 시간이 늘어남
- OFA의 sub-network 간 interference는 simultaneous optimization을 어렵게 함
- 특정 granularity 아래의 hardware latency 차이는 noisy 함
- Unique architecutre들 간의 accuracy, latency 차이는 search 과정 중에 구별가능해야 함
- OFA의 search space는 120 ~ 560 MFLOP 범위에서 $O(10^{19})$개의 architecture 선택이 가능함
- 1 FLOP으로 균일하게 분산시켜도 여전히 $O(10^{11})$개의 선택이 가능하므로 구별이 어려움
-> 모든 hardware에서 특정 threshold 미만의 추론 시간은 사실상 noise와 동일함 - 더 sparse 한 design space도 동일한 density와 배포 범위를 지원할 수 있다고 볼 수 있음
- Unique architecutre들 간의 accuracy, latency 차이는 search 과정 중에 구별가능해야 함
- 모델의 차원은 orthogonal 하지 않음
- Fixed kernel size에 대해 균일한 depth와 width로 OFA sub-network의 accuracy, latency를 비교
- 2차원 heatmap의 대각선을 따라 monotonic 하게 그라데이션이 그려짐
- Depth, width 차원 모두에서 증가할 때 더 나은 accuracy-latency trade-off를 만족하는 sub-network를 search 할 수 있다는 것을 의미 - 모델의 depth와 width 사이의 관계를 나타내는 coefficient가 존재함
- 차원 간의 coupling을 따르면서 accuracy를 희생하지 않고 architecture의 design space를 줄일 수 있다는 것을 의미 - OFA는 불필요하게 더 많은 모델을 학습하고 있음
- 중복되고 비효율적인 sub-network를 정리하는 것이 필요
- 2차원 heatmap의 대각선을 따라 monotonic 하게 그라데이션이 그려짐

3. Compound OFA
- Coupling Heuristic
- Depth와 witdth 차원은 함께 증가하거나 감소해야 함 (독립적으로 동작하지 않음)
- 각 block에서 $i$번째로 큰 depth $d_{i} \in D$를 sampling 할 때마다 해당 block의 모든 $d_{i}$ layer에 대해 $i$번째로 큰 width $w_{i} \in W$를 같이 sampling
- For example, $D = [2,3,4], W = [3,4,6]$인 경우
- 각 block은 channel expansion ratio $3$인 2개의 layer / channel ratio $4$인 3개의 layer / channel ratio $6$인 4개의 layer를 가질 수 있음 - Coupling heuristic에 의해 search space가 정의되면 기존 OFA 방식에 따라 search를 수행
- 가장 큰 network에서 모든 weight를 공유하면서 최적의 sub-network를 잘라내는 방식
- Coupling heuristic을 통해 design space의 자유도를 줄일 수 있음
- 기본적으로 kernel size를 고정하지만 elastic-kernel을 사용할 수도 있음
- Fixed kernel을 사용하면 각 block에서 kernel size가 3, 5로 고정된 단순한 search space를 구성함
- 해당 design space에서는 depth (width) 만으로도 block의 구성을 완전히 지정할 수 있음
- 5개 block의 경우 $3^{5} = 243$개의 후보를 만들 수 있음 - Elastic-kernel design space에서는 layer 당 $K=[3,5,7]$에서 sampling 된 kernel size를 활용
- $(3^{2} + 3^{3} + 3^{4})^{5} \approx 10^{10}$개의 후보가 생성됨
- CompOFA에서 학습 속도 향상의 원인은 search space cardhinality의 감소 때문임
- 모델에 대한 input resolution은 추론 시간에 영향을 주지만 학습 가능한 unique architecture의 수에는 영향을 주지 않음
- Resolution elastic을 유지하면서 search space cardinality (학습 예산)를 늘리지 않고 여러 latency를 지원함
- Training Speedup
- OFA는 progressive shrinking을 사용하여 sub-network를 단계적으로 training 함
- 가장 큰 모델에서 시작하여 점진적으로 더 작은 sub-network를 포함시켜 나가는 방식
- $T_{family} \propto \sum_{p \in Phases} e_{p} \times E(t_{p})$ : $e_{p}$ 만큼의 epoch 동안 진행될 때, 모델을 학습하는데 걸리는 총 시간
- $E(t_{p})$ : $p$ 단계에서 한 epoch을 완료하는데 걸리는 예상 시간
- (목표) $T_{family}$를 줄이는 동시에 OFA와 동일한 수준의 accuracy-latency trade-off를 달성하는 것
- $E(t_{p})$를 변경하지 않고 $T_{family}$를 줄이기 위해 phaese의 수를 줄이는 것을 목표로 함
- 모델의 수는 $T_{family}$를 결정하는데 명시적으로 고려되는 요소는 아니지만, training phases의 수와 duration에 암묵적인 영향을 미침
- 모델의 개수가 많은 경우 모델 간의 interference로 인해 progressive shrinking을 필요로 함
- CompOFA는 search space에서 동시에 학습 가능한 모델의 최대 개수는 OFA보다 17배 더 작음
- 더 작은 search space 크기로 인해 CompOFA에서 progressive shrinking을 제거해도 충분한 accuracy를 달성할 수 있음
4. Experiments
- Settings
- Search Space : MobileNetV3
- Dataset : ImageNet
- Comparison : OFA
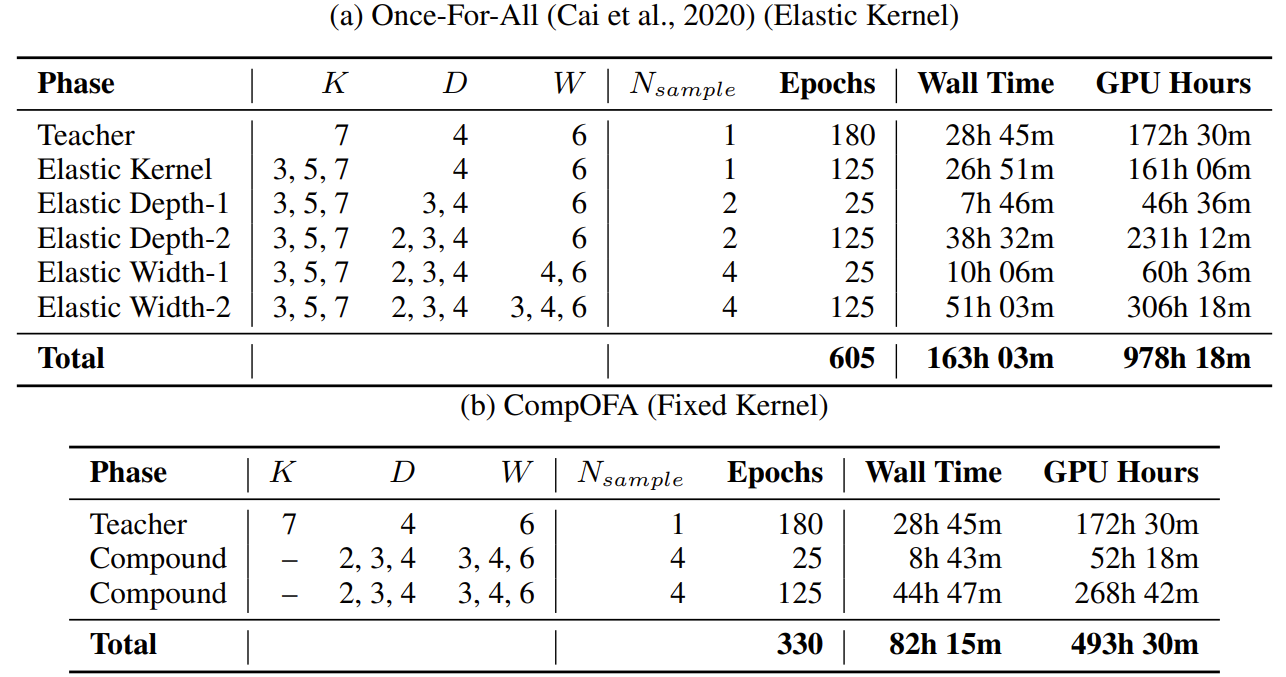
- Training Time and Cost
- CompOFA를 사용하는 경우 50%의 학습 비용을 줄일 수 있음
- OFA는 978 GPU day가 걸리는 반면, CompOFA는 493 GPU day가 걸림 - $CO_{2}$ 배출량 측면에서 CompOFA는 더 효율적인 성능을 보임

- Accuracy-Latency Trade-off
- Evolutionary search를 통해 얻어진 모델의 accuracy 비교
- Samsung Note 10, NVIDIA GeForce RTX 2080 Ti GPU, Intel Xeon Gold 6226 CPU 별 latency 하에서 accuracy를 최대화
- CompOFA가 모든 hardware 제약환경에서 가장 좋은 accuracy를 보임

- Design Space Comparison
- 각 latency bucket에 대한 분류 오류의 누적 분포 함수(CDF) 비교
- CDF는 x축에서 주어진 accuracy를 초과하는 모델의 비율로 나타냄
- CompOFA의 CDF는 OFA의 CDF보다 위에 있으므로, CompOFA가 정확한 모델의 비율이 더 높다는 것을 의미

- 각 search space에 대해 bucket에서 20개의 모델을 sampling 하여 accuracy를 비교
- CompOFA의 search space에 더 정확한 모델 구성이 집중되어 있음을 의미

- Effect of Number of Phases
- OFA는 progressive shrinking이 제거되면 3.7%의 accuracy 하락이 나타남
- $O(10^{19})$ 모델이 weight를 동시에 최적화하기 위해 서로 interfering 하기 때문에 안정적인 학습을 위해 progressive shrinking이 필요 - CompOFA는 training phase를 줄임으로써 전체 학습 시간을 줄임
- CompOFA는 progressive shrinking을 사용하지 않고도 OFA와 동일한 accuracy를 달성함
- 17배 더 작은 search space 크기로 인해 sub-network 간의 interference가 줄어들기 때문 - CDF를 비교해 보면, CompOFA가 약간 더 높은 accuracy를 보임
- Search space를 축소하는 과정에서 discard 된 모델은 accuracy에 영향을 주지 않음

- Generalizing to Other Architectures
- Coupling heuristic은 architecture에 관계없이 적용되어야 함
- MobileNetV3에서 Proxyless NAS로 architecture를 변경하여 OFA와 CompOFA로 얻어진 결과를 비교
- Proxyless NAS에서도 CompOFA가 OFA에 비해 더 효율적인 것으로 나타남
- Search Time
- OFA는 latency predictor를 필요로 하지만, CompOFA는 더 작은 search space로 인해 latency look-up table을 구축하는데 드는 비용을 줄일 수 있음
- Search space가 작은 경우 memoization을 활용하여 학습 시간을 단축할 수 있음
- CompOFA의 경우 75초의 NAS 실행 시간을 기록함
반응형
'Paper > ETC' 카테고리의 다른 글
댓글