

티스토리 뷰
Paper/TTS
[Paper 리뷰] SyncSpeech: Efficient and Low-Latency Text-to-Speech based on Temporal Masked Transformer
feVeRin 2026. 5. 19. 15:18반응형
SyncSpeech: Efficient and Low-Latency Text-to-Speech based on Temporal Masked Transformer
- Text-to-Speech model은 여전히 latency의 한계가 있음
- SyncSpeech
- Temporal Mask Transformer를 기반으로 autoregressive model의 temporally ordered generation과 non-autoregressive model의 parallel decoding을 unify
- 추가적으로 High-Probability Masking을 통해 training efficiency를 향상
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 autoregressive (AR), non-autoregressive (NAR) paradigm으로 구분됨
- AR TTS model은 conditional language modeling task로 formulate 되어 temporally ordered fashion에 따라 speech token을 left-to-right generation 함
- 한편 NAR TTS model은 parallel prediction을 통해 higher generation efficiency를 달성할 수 있음
- BUT, NAR model은 incremental generation이 어려우므로 high first-packet latency의 한계가 있음
-> 그래서 AR, NAR paradigm의 장점을 combine한 SyncSpeech를 제안
- SyncSpeech
- Temporal Masked Transformer (TMT)를 통해 AR, NAR paradigm을 integrate
- 추가적으로 High-Probability Masking을 도입해 training efficiency를 향상
< Overall of SyncSpeech >
- TMT와 High-Probability Masking을 활용한 low-latency TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- SyncSpeech는 text-to-token model과 token-to-speech model로 구성됨
- Temporal Masked Transformer (TMT)는 text-to-token model의 backbone으로 사용되고, CosyVoice2의 off-the-shelf chunk-aware speech decoder는 token-to-speech module로 사용됨
- Temporal Masked Generative Transformer
- Audio sample $\tilde{\mathbf{x}}$, transcript $\tilde{\mathbf{y}}$에 대해 transcribed speech dataaset $(\tilde{\mathbf{x}},\tilde{\mathbf{y}})$이 주어진다고 하자
- Transcript $\tilde{y}$는 text tokenizer를 통해 BPE token sequence $\mathbf{y}=[y_{1},y_{2},y_{3},...,y_{L}]$로 tokenize 됨
- $L$ : BPE token 수 - 이후 논문은 off-the-shelf semantic speech tokenizer를 사용해 speech sample $\tilde{\mathbf{x}}$를 $T$ frame discrete speech token $\mathbf{s}=[s_{1},s_{2},s_{3},...,s_{T}]$로 encode 함
- Speech token sequence에서 각 BPE token의 end-time을 indicate 하는 duration token $\mathbf{a}=[a_{1},a_{2},a_{3},...,a_{L}]$과 같고, 여기서 $\mathbf{a}$는 $(\tilde{\mathbf{x}},\tilde{\mathbf{y}})$ pair에 대해 alignment tool을 적용하여 얻어짐
- $a_{L}=T$
- Transcript $\tilde{y}$는 text tokenizer를 통해 BPE token sequence $\mathbf{y}=[y_{1},y_{2},y_{3},...,y_{L}]$로 tokenize 됨

- Sequence Design
- Sequence construction 시 inference process와의 consistency를 위해 random truncation strategy를 활용함
- 이를 위해 random $n\in[1,L]$을 select 함
- 이는 streaming text input을 receive 할 때 TMT가 $n$-th BPE token에 해당하는 speech token을 생성해야 하는 것을 indicate 함 - Unnatural pause를 방지하기 위해, TMT는 $q$ text token을 look ahead 하고 truncated text token sequence $\mathbf{y}'=[y_{1},y_{2},y_{3},...,y_{L'}]$을 얻음
- $L'=\min(L,n+q)$ - Duration token $\mathbf{a}$를 기반으로 truncated speech token sequence $\mathbf{s}_{1:a_{n}}=[s_{1},s_{2},...,s_{a_{n}}]$을 얻고, binary mask $\mathbf{m}$과 masked speech token sequence $\mathbf{s}'$를 정의함:
(Eq. 1) $\mathbf{s}'=\mathbf{s}_{1:a_{n}}\odot\mathbf{m}$
(Eq. 2) $\mathbf{m}=[m_{i}]_{i=1}^{a_{n}},\,\,\mathbf{m}_{1:a_{n-1}}=0,\,\, \mathbf{m}_{a_{n-1}:a_{n}}=1$
- $s_{i}$는 $m_{i}=1$인 경우 special $\text{<MASK>}$ token을 replace 하고 $m_{i}=0$인 경우 $s_{i}$를 그대로 사용함 - 이후 truncated text token sequence $\mathbf{y}'$, masked speech token sequence $\mathbf{s}'$, duration token $\mathbf{a}$를 사용하여 input speech sequence를 구성함:
(Eq. 3) $\mathbf{f}=[\mathbf{y}',E,D,\mathbf{s}'_{1:a_{1}},...,D,\mathbf{s}'_{a_{n-1}:a_{n}},D]$
- $E$ : end-to-text token, $D$ : duration prediction placeholder
- 이때 $D$는 duration token $\mathbf{a}$를 기반으로 서로 다른 BPE token에 대한 masked speech token sequence $\hat{\mathbf{s}}$를 separate 하는 데 사용됨
- 이를 위해 random $n\in[1,L]$을 select 함
- Loss Function
- Sequence $\mathbf{f}$는 mask, duration prediction을 training objective로 하는 TMT의 input으로 사용됨
- Sequence $\mathbf{f}$는 TMT에 전달되어 hidden state를 얻은 다음, 2개의 linear layer를 통해 text token $y_{n}$에 해당하는 speech token과 next text token $y_{n+1}$의 duration을 predict 하는 데 사용됨
- 이를 통해 first text token의 duration prediction을 제외하고 추론 시 duration, mask prediction을 single decoding step으로 integrate 할 수 있음
- 결과적으로 논문은 masked generative training과 duration training을 위해, 다음의 negative log-likelihood function을 minimize 함:
(Eq. 4) $ \mathcal{L}_{mask}=-\log p(\mathbf{s}_{a_{n-1:a_{n}}}|\mathbf{f};\theta)$
(Eq. 5) $\mathcal{L}_{duration}=-\log p(l_{n+1}|\mathbf{f};\theta)$
- $\theta$ : TMT의 neural network parameter, $l_{n+1}=a_{n+1}-a_{n}$, $a_{0}=0$
- Hybrid Attention Mask
- TMT는 causal, bidrectional pattern을 combine 한 hybrid attention mask를 사용함
- Causal attention은 input text token과 special token에 적용되고, bidirectional attention은 masked, speech token에 적용되어 모든 preceding token과 same text token에 해당하는 모든 masked, speech token에 attend 함
- 이를 통해 speech token은 해당 text token의 total duration을 perceive 할 수 있음
- Inference
- SyncSpeech는 streaming fashion으로 text를 process 함
- Input text BPE token $\mathbf{y}$의 수가 look-ahead threshold $q$를 exceed 하면 input sequence $\mathbf{f}=[\mathbf{y},D]$가 구성된 다음 TMT에 전달되어 $y_{1}$의 duration을 predict 함
- Predicted duration을 기반으로 mask token과 duration prediction placeholder를 insert 하여 sequence padding을 수행함
- Updated sequence는 TMT에 다시 전달되어 $y_{1}$에 해당하는 speech token과 $y_{2}$의 duration을 predict 한 다음, input sequence $\mathbf{s}$를 update 하고 additional padding을 수행함
- 이후 각 text token을 receive 할 때마다 prediction, update, padding step을 repeat 하여 각 text token과 speech token에 대한 synchronous generation을 지원함
- 이때 생성된 speech token 수가 speech decoder의 chunk size를 exceed 하면 해당 token과 speaker prompt를 사용하여 speech waveform을 생성할 수 있음
- 추가적으로 text, speech token에 대해 separate positional embedding이 사용됨
- Input text BPE token $\mathbf{y}$의 수가 look-ahead threshold $q$를 exceed 하면 input sequence $\mathbf{f}=[\mathbf{y},D]$가 구성된 다음 TMT에 전달되어 $y_{1}$의 duration을 predict 함
- High-Probability Masked Pre-Training
- SyncSpeech에 대한 from-scratch training strategy는 각 step에서 gradient가 하나의 text token에만 backpropagate 되므로 inefficient 함
- 이를 해결하기 위해 논문은 High-Probability Masked Pre-Training을 도입함
- 먼저 masked speech token을 $\hat{\mathbf{s}}=\mathbf{s}\odot \hat{\mathbf{m}}$이라고 하자
- $\hat{\mathbf{m}}=[\hat{m}_{i}]_{i=1}^{a_{L}}$ : speech token의 binary mask - 이때 masking rule은 high masking probability와 inference process의 consistency를 보장하는 것을 목표로 함
- Text token의 binary mask $\hat{\mathbf{m}}_{bpe}$에 대해 first value는 Bernolli distribution $p=0.5$에 따라 sampling 되고, 이때 subsequent adjacent value는 동일하지 않음
- Duration token $\mathbf{a}$를 기반으로 text token mask $\hat{\mathbf{m}}_{bpe}$는 speech token mask $\hat{\mathbf{m}}$으로 convert 됨
- 그러면 input sequence는 다음과 같이 구성되고, TMT는 masked generative training과 duration training에 대한 negative log-likelihood를 minimize 하도록 optimize 됨:
(Eq. 6) $\hat{\mathbf{f}}=[\mathbf{y},E,D,\hat{\mathbf{s}}_{1:a_{1}},...,D,\hat{\mathbf{s}}_{a_{L-1}:a_{L}}]$
- 결과적으로 논문은 text, speech token alignment를 위해 high-probability masked pre-training을 수행하고, prediction process와 consistent 한 training strategy를 통해 model을 fine-tuning 함
- Other Modules
- SyncSpeech의 나머지 module은 CosyVoice2를 기반으로 구축됨
- Supervised Speech Semantic (S3) tokenizer는 speech tokenzier로 사용되고, conditional flow matching decoder와 HiFi-GAN vocoder는 chunk-sized semantic token으로부터 waveform을 생성하는 데 사용됨
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : CosyVoice, CosyVoice2
- Results
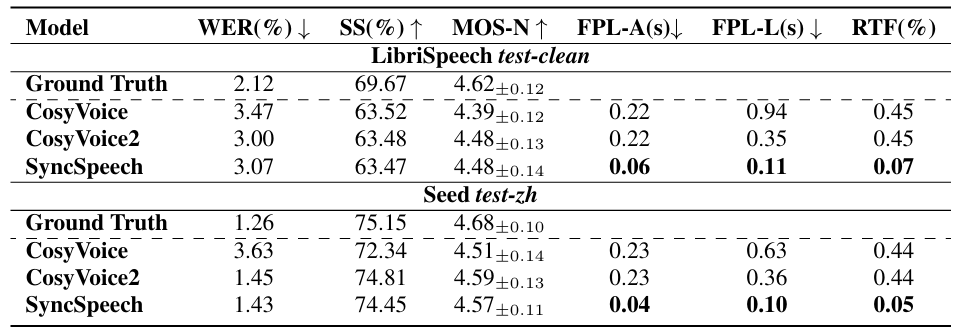
- 전체적으로 SyncSpeech의 성능이 가장 뛰어남
- Ablation Study
- 각 component는 성능 향상에 유효함

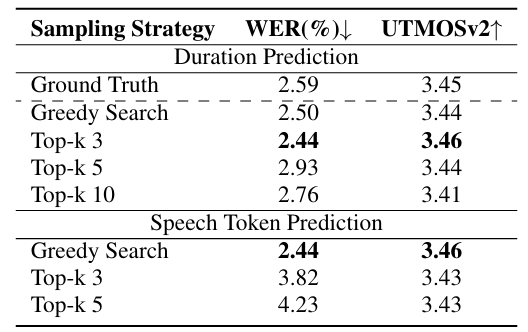
- Analysis
- Duration prediction 시 $\text{Top-k}=3$ sampling을 사용했을 때 최적의 결과를 달성함
- Token prediction 시에는 greedy search가 효과적임
- Look ahead $q=1$일 때 가장 낮은 WER을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글