
티스토리 뷰
Paper/TTS
[Paper 리뷰] VoXtream: Full-Stream Text-to-Speech with Extremely Low Latency
feVeRin 2026. 3. 23. 10:23반응형
VoXtream: Full-Stream Text-to-Speech with Extremely Low Latency
- Real-time zero-shot streaming text-to-speech model이 필요함
- VoXtream
- Limited look-ahead를 사용하여 incoming phoneme을 audio token으로 directly mapping
- 구조적으로는 incremental phoneme transformer, temporal transformer, depth transformer를 활용
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Low-latency streaming Text-to-Speech (TTS)를 위해서는 first-packet latency를 minimize 해야 함
-> 그래서 minimal delay를 가지는 fully-autoregressive zero-shot streaming TTS model인 VoXtream을 제안
- VoXtream
- Limited phoneme look ahead를 가지는 incremental Phoneme Transformer (PT)를 도입
- 추가적으로 semantic, duration token을 jointly predict 하는 Temporal Transformer (TT), TT output과 speaker embedding을 condition으로 acoustic token을 생성하는 Depth Transformer (DT)를 적용
< Overall of VoXtream >
- Small look ahead와 PT, TT, DT architecture를 활용한 low-latency streaming TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Phoneme Transformer
- Phoneme Transformer (PT)는 phoneme sequence를 receive 하여 embedding으로 encoding 하는 decoder-only Transformer에 해당함
- 해당 model은 incrementally operate 하므로 text stream의 new word마다 input이 grow 함
- Natural prosody를 위해 PT는 $N$ phoneme token에 대한 Look Ahead (LA)가 가능함
- 이때 limited LA를 활용해 speech token 생성 시 $N$ phoneme을 wait 하지 않고 first word 이후에 바로 start 함
- Minimal LA value는 text-buffer size에 의해 결정되고, maximal value는 10 phoneme으로 limit 됨
- 논문은 word-level에서 g2pE를 사용하여 input text stream을 phoneme으로 convert 함

- Temporal Transformer
- Temporal Transformer (TT)는 audio token과 phoneme sequence에 condition 된 autoregressive Transformer에 해당함
- 먼저 audio token은 Mimi codec을 통해 12.5Hz로 추출되고, low frame rate로 인해 각 audio frame에 두 phonme을 assign 함
- Acoustic prompt, phoneme sequence 간의 alignment는 Montreal Forced Aligner (MFA)를 사용해 얻고, stability를 위해 one-step의 acoustic delay를 적용함
- 이후 TT는 Mimi의 first codebook (semantic token)과 duration token을 output 함
- 논문은 monotonic phoneme alignment를 적용하여 specific phoneme을 predict 하는 대신 shift flag ($\texttt{stay}/\texttt{go}$)를 encode 하는 duration token을 predict 함
- 여기서 $\texttt{stay}$는 next frame에서 current phoneme generation을 continue 하는 것을 의미하고, 그렇지 않은 경우 next phoneme으로 switch 함
- Duration token의 두 번째 숫자에 해당하는 phoneme 수는 slower/faster pronunciation을 나타냄
- Semantic, duration token은 single classification head에서 predict 되고 joint distribution에서 sampling 됨
- Audio token index는 temporal, codebook position에 대응함
- 먼저 audio token은 Mimi codec을 통해 12.5Hz로 추출되고, low frame rate로 인해 각 audio frame에 두 phonme을 assign 함
- Depth Transformer
- Depth Transformer (DT)는 TT output embedding과 semantic token에 condition 된 autoregressive Transformer로써, Mimi codec의 2nd codebook (acoustic token)으로부터 audio token을 생성함
- 이때 논문은 ReDimNet의 speaker embedding을 DT에 conditioning 하고 latency-quality trade-off로 12 Mimi codebook을 사용함
- Mimi decoder는 각 frame의 semantic, acoustic token을 streaming fashion으로 80ms speech로 convert 함
- VoXtream은 TT, DT output의 negative log-likelihood를 minimize 하여 training 되고 external aligner를 통해 acoustic, text prompt 간의 initial alignment를 얻음
3. Experiments
- Settings
- Dataset : Emilia, HiFi-TTS2
- Comparisons : CosyVoice, CosyVoice2, XTTS, VoiceCraft, VoiceStar, Spark-TTS, Llasa, FireRedTTS
- Results
- 전체적으로 VoXtream의 성능이 가장 우수함

- Full-stream capability 측면에서도 우수한 성능을 보임

- VoXtream은 우수한 RTF, FPL을 달성함

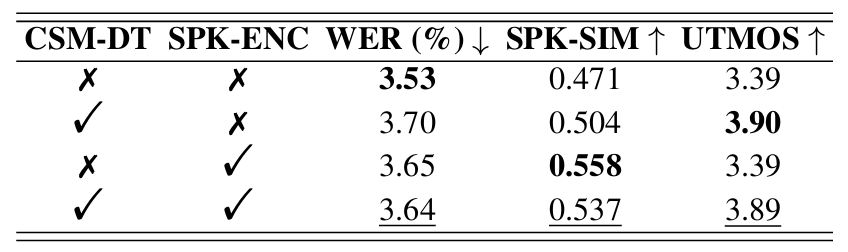
- Ablation Study
- 각 component는 성능 향상에 유효함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글