

티스토리 뷰
Paper/TTS
[Paper 리뷰] DAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
feVeRin 2026. 3. 18. 12:54반응형
DAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
- Environment-aware Text-to-Speech를 위한 model이 필요함
- DAIEN-TTS
- Pre-trained Speech-Environment Separation module을 활용하여 clean speech, environment audio의 mel-spectrogram을 추출하고, random span mask를 각 mel-spectrogram에 적용하여 infilling process를 지원
- Speech, environment component에 Dual Classifier-Free Guidance를 적용하여 controllability를 향상
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Zero-shot Text-to-Speech (TTS)는 speaker의 short speech prompt를 condition으로 사용함
- 특히 CosyVoice, DiTTo-TTS 등은 in-context learning을 활용하여 naturalness를 향상함
- 이때 in-context learning은 speech prompt의 acoustic environment characteristic을 preserve 하므로 다양한 background environment를 반영하기 어려움 - 해당 environment-aware TTS를 위해서는 timbre와 acoustic background를 independently control 하는 separate speaker, environment prompt가 필요함
- BUT, time-varying background noise에 적용하기 어렵고 audio prompt length가 동일해야 함
- 특히 CosyVoice, DiTTo-TTS 등은 in-context learning을 활용하여 naturalness를 향상함
-> 그래서 기존 environment-aware TTS의 한계점을 개선한 DAIEN-TTS를 제안
- DAIEN-TTS
- Pre-trained Speech-Environment Separation (SES) module을 incorporate 해 speech, environment mel-spectrogram을 추출하고 varying length의 random span mask를 적용
- 추가적으로 Dual Classifier-Free Guidance (DCFG)와 SNR adaptation을 도입해 controllability를 향상
< Overall of DAIEN-TTS >
- Disentangled Audio Infilling을 활용한 environment-aware zero-shot TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- DAIEN-TTS는 F5-TTS를 기반으로 구축됨
- 이때 time-varying environment-aware speech synthesis를 위해 disentangled audio infilling을 도입함
- Waveform sequence length $T$에 대해, environmental speech signal $\mathbf{y}\in \mathbb{R}^{T}$가 주어지면
- Pre-trained Transformer-based SES module은 $\mathbf{y}$를 clean speech mel-spectrogram $\mathbf{c}_{spk}\in\mathbb{R}^{M\times L}$과 environmental audio mel-spectrogram $\mathbf{c}_{env}\in\mathbb{R}^{M\times L}$로 decompose 함
- $M$ : mel-dimension, $L$ : spectrogram sequence length - Varying prompt condition을 simulate 하기 위해, 서로 다른 length의 random span mask $\mathbf{m}_{spk}, \mathbf{m}_{env}$를 $\mathbf{c}_{spk},\mathbf{c}_{env}$에 적용함
- 이후 unmasked portion인 $(1-\mathbf{m}_{spk})\odot \mathbf{c}_{spk}, (1-\mathbf{m}_{env})\odot \mathbf{c}_{env}$와 length $L$의 extended text sequence $\mathbf{z}$를 conditional input으로 사용하여 masked environmental speech $\mathbf{m}_{spk}\odot \mathbf{x}_{1}$을 reconstruct 함
- $\mathbf{x}_{1}$ : environmental speech $\mathbf{y}$의 mel-spectrogram
- Pre-trained Transformer-based SES module은 $\mathbf{y}$를 clean speech mel-spectrogram $\mathbf{c}_{spk}\in\mathbb{R}^{M\times L}$과 environmental audio mel-spectrogram $\mathbf{c}_{env}\in\mathbb{R}^{M\times L}$로 decompose 함

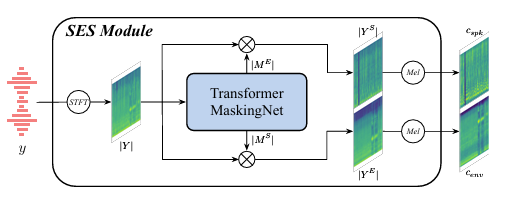
- SES Module
- SES module은 magnitude spectrogram level에서 speech, background environment separation을 수행함
- 먼저 frequency bin 수 $F$에 대해 environmental speech $\mathbf{y}$는 STFT를 통해 magnitude spectrogram $|\mathbf{Y}|\in\mathbb{R}^{F\times L}$로 transform 됨
- 이후 environmental magnitude spectrogram $|\mathbf{Y}|$는 input convolutional layer, $K$ Transformer block, 2 output convolutional layer로 구성된 Transformer-based masking net에 전달됨 - Masking net은 speech, background environment component에 대한 2개의 mask $|\mathbf{M}^{S}|, |\mathbf{M}^{E}|\in\mathbb{R}^{F\times L}$을 predict 하고, 해당 mask는 $|\mathbf{Y}|$에 대한 element-wise multiplication을 통해 unwanted component를 suppress 함
- 결과적으로 Masking net은 separated speech, environment magnitude spectrogram $|\mathbf{Y}^{S}|=|\mathbf{Y}|\odot |\mathbf{M}^{E}|\in\mathbb{R}^{F\times L}$과 $|\mathbf{Y}^{E}|=|\mathbf{Y}|\odot |\mathbf{M}^{S}|\in\mathbb{R}^{F\times L}$을 생성함
- 해당 spectrogram은 mel-filter bank를 pass 하여 mel-spectrogram으로 변환되고, audio infilling process의 speaker, environment condition으로 사용됨
- 먼저 frequency bin 수 $F$에 대해 environmental speech $\mathbf{y}$는 STFT를 통해 magnitude spectrogram $|\mathbf{Y}|\in\mathbb{R}^{F\times L}$로 transform 됨
- Training
- 논문은 text-guided audio infilling task를 활용하여 model을 training 함
- 즉, DAIEN-TTS는 full text와 SES module을 통해 disentangle 된 surrounding clean speech, background environment audio를 condition으로 하여 environmental speech의 masked segment를 predict 함
- 이때 varying length의 speaker, environment prompt를 handle 하기 위해 disentangled speech mel-spectrogram $\mathbf{c}_{spk}$, environment mel-spectrogram $\mathbf{c}_{env}$에 random span mask를 적용함
- 이후 Conditional Flow Matching (CFM)을 기반으로 noisy environmental speech $\psi_{t}(\mathbf{x}_{0})=(1-t)\mathbf{x}_{0}+t\mathbf{x}_{1}$을 feed 함
- $\mathbf{x}_{0}$ : sampled Gaussian noise, $t$ : randomly sampled flow step - 각 Diffusion Transformer (DiT) block에 multi-head cross-attention layer를 insert 하여 $(1-\mathbf{m}_{env})\odot \mathbf{c}_{env}$를 반영하고 environment information을 inject 함
- 결과적으로 model은 다음 objective를 사용하여 $(1-\mathbf{m}_{spk})\odot \mathbf{c}_{spk}, (1-\mathbf{m}_{env})\odot \mathbf{c}_{env}$, extended text $\mathbf{z}$ condition에 대해 $\mathbf{m}_{spk}\odot \mathbf{x}_{1}$을 reconstruct 하도록 train 됨:
(Eq. 1) $ \mathcal{L}_{CFM}=\left|\left| \left( v_{t}(\psi_{t}(\mathbf{x}_{0})|\mathbf{z}, (1-\mathbf{m}_{spk})\odot \mathbf{c}_{spk}, (1-\mathbf{m}_{env})\odot \mathbf{c}_{env})-(\mathbf{x}_{1}-\mathbf{x}_{0})\right) \odot \mathbf{m}_{spk}\right|\right|_{2}^{2}$
- $v_{t}(\cdot)$ : learned velocity field
- 이후 Conditional Flow Matching (CFM)을 기반으로 noisy environmental speech $\psi_{t}(\mathbf{x}_{0})=(1-t)\mathbf{x}_{0}+t\mathbf{x}_{1}$을 feed 함
- Inference
- Speaker prompt speech $\mathbf{y}_{spk}$와 environment prompt speech $\mathbf{y}_{env}$가 주어지면,
- SES module을 사용하여 $\mathbf{y}_{spk}$에서 speech component, $\mathbf{y}_{env}$에서 background environment component를 separate 함
- 각각 speaker condition $\mathbf{c}_{spk}$, environment condition $\mathbf{c}_{env}$로 사용됨 - Speaker prompt transcription $\mathbf{z}_{ref}$, text prompt $\mathbf{z}_{gen}$을 concatenate 하여 $\mathbf{z}_{ref\cdot gen}$을 얻고, Ordinary Differential Equation (ODE)를 사용하여 target mel-spectrogram을 생성함
- ODE solver는 sampled noise $\psi_{0}(\mathbf{x}_{0})=\mathbf{x}_{0}$에서 start 하여 differential equation에 따라 $\psi_{1}(\mathbf{x}_{0})=\mathbf{x}_{1}$으로 integrate 함:
(Eq. 2) $d\psi_{t}(\mathbf{x}_{0})/dt=v_{t}\left(\psi_{t}(\mathbf{x}_{0}), \mathbf{z}_{ref\cdot gen}, \mathbf{c}_{spk}, \mathbf{c}_{env}\right)$ - Target mel-spectrogram을 얻은 이후에는 $\mathbf{c}_{spk}$를 discard 하고 vocoder를 적용하여 environmental personalized speech를 reconstruct 함
- ODE solver는 sampled noise $\psi_{0}(\mathbf{x}_{0})=\mathbf{x}_{0}$에서 start 하여 differential equation에 따라 $\psi_{1}(\mathbf{x}_{0})=\mathbf{x}_{1}$으로 integrate 함:
- Dual Classifier-Free Guidance
- CFG를 사용하면 generation fidelity와 diversity를 향상할 수 있음
- 특히 논문에서 text, speaker information은 speech signal과 함께 jointly embed 되지만 background environment에는 independent 하므로 unified guidance term으로 취급할 수 있음 - 이를 기반으로 논문은 DCFG mechanism을 도입함:
(Eq. 3) $v_{t,DCFG}=v_{t}\left(\psi_{t}(\mathbf{x}_{0}),\mathbf{z},\mathbf{c}_{spk},\mathbf{c}_{env}\right)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+\alpha_{speech}\left(v_{t}(\psi_{t}(\mathbf{x}_{0}),\mathbf{z},\mathbf{c}_{spk},\emptyset) - v_{t}(\psi_{t}(\mathbf{x}_{0}),\emptyset,\emptyset,\emptyset)\right)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, +\alpha_{env}\left(v_{t}(\psi_{t}(\mathbf{x}_{0}),\emptyset,\emptyset,\mathbf{c}_{spk}) - v_{t}(\psi_{t}(\mathbf{x}_{0}),\emptyset,\emptyset,\emptyset)\right)$
- $\emptyset$ : null condition, $\alpha_{speech}, \alpha_{env}$ : DCFG strength
- CFG를 사용하면 generation fidelity와 diversity를 향상할 수 있음
- SNR Adaptation
- Environment prompt는 background acoustic environment를 imitate 하는 것 외에도 synthesized speech에서 SNR을 preserve 할 수 있어야 함
- 따라서 논문은 SNR adaptation을 도입함 - Environment speech $\mathbf{y}$가 speech component $\mathbf{y}^{S}$, background environment component $\mathbf{y}^{E}$로 구성된다고 하자
- 즉, $\mathbf{y}=\mathbf{y}^{S}+\mathbf{y}^{E}$ - 그러면 SNR, discrete Parseval theorem에 따라, 다음을 얻을 수 있음:
(Eq. 4) $\text{SNR}=10\log\left(\frac{||\mathbf{y}^{S}||_{2}^{2}}{||\mathbf{y}^{E}||_{2}^{2}}\right) = 10\log\left(\frac{||\mathbf{Y}^{S}||_{2}^{2}}{||\mathbf{Y}^{E}||_{2}^{2}}\right)$ - Separated background environment magnitude spectrogram $\mathbf{Y}_{env}^{E}$에 scailing factor를 적용하여 synthesized speech의 SNR이 environment prompt와 match 되도록 할 수 있음:
(Eq. 5) $10\log \left(\frac{||\mathbf{Y}_{spk}^{S}||^{2}_{2}}{||\mathbf{Y}_{env}^{E}\cdot \text{Scale}||_{2}^{2}}\right)=10\log \left(\frac{||\mathbf{Y}_{env}^{S}||_{2}^{2}}{||\mathbf{Y}_{env}^{E}||_{2}^{2}}\right)$
- $\text{Scale}=\sqrt{||\mathbf{Y}^{S}_{spk}||_{2}^{2}/||\mathbf{Y}^{S}_{env}||_{2}^{2}}$ - 추론 시 $\mathbf{Y}_{env}^{E}$는 calculated factor로 scale 된 다음, mel-spectrogram으로 transform 되어 environmental speech generation의 final environment condition으로 사용됨
- Environment prompt는 background acoustic environment를 imitate 하는 것 외에도 synthesized speech에서 SNR을 preserve 할 수 있어야 함
- SES module을 사용하여 $\mathbf{y}_{spk}$에서 speech component, $\mathbf{y}_{env}$에서 background environment component를 separate 함
3. Experiments
- Settings
- Dataset : LibriTTS + DNS-Challenge
- Comparisons : F5-TTS
- Results
- 전체적으로 DAIEN-TTS의 성능이 가장 우수함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글