

티스토리 뷰
Paper/Representation
[Paper 리뷰] ParaMETA: Towards Learning Disentangled Paralinguistic Speaking Styles Representations from Speech
feVeRin 2026. 1. 28. 13:42반응형
ParaMETA: Towards Learning Disentangled Paralinguistic Speaking Styles Representations from Speech
- Emotion, gender, age와 같은 다양한 speaking style에 대한 representation을 학습할 수 있어야 함
- ParaMETA
- 각 style에 대한 dedicated sub-space로 speech를 project 하여 disentangled, task-specific embedding을 얻음
- Inter-task interference와 negative transfer를 mitigate 하여 single model로 multiple paralinguistic task를 처리
- 논문 (AAAI 2026) : Paper Link
1. Introduction
- Speaking style representation은 emotion, age, gender recognition과 같은 다양한 task에서 활용됨
- BUT, 기존 방식들은 각 task 별로 separate model을 training 하므로 computationally expensive 함
- 특히 CLAP은 speech와 text를 unified embedding space로 align 하여 효과적인 representation을 추출함
- BUT, CLAP은 text caption에 describe 된 모든 speaking style을 포함하는 unified embedding을 활용하므로 inter-task interference, negative transfer 문제가 발생할 수 있음
- 결과적으로 individual style attribute를 contorl 하고 isolate 하기 어려워짐
-> 그래서 다양한 speaking style을 효과적으로 disentangle 할 수 있는 ParaMETA를 제안
- ParaMETA
- META embedding space에서 shared label을 가진 speech sample을 grouping 하여 dataset의 style label utility를 maximize
- 이후 task-specific sub-space에서 META embedding을 각 task에 맞게 separate space로 project
< Overall of ParaMETA >
- Task-specific modeling을 활용한 paralinguistic representation learning framework
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Task $T$를 emotion, age, gender와 같은 specific speaking style이라고 하자
- 각 task $t\in T$는 distinct class set $C_{t}$에 속하고 각 class는 해당 speaking style의 possible value를 represent 함
- 여기서 논문은 각 speech가 task 당 최대 하나의 class에 assign 된다고 가정함 - 결과적으로 각 task $t$가 set $C_{t}$에 해당하는 class를 가질 때, objective는 $T$ task의 speech sample과 해당 label에 대해 $T$ task-specific embedding을 학습하는 것을 목표로 함
- 각 task $t\in T$는 distinct class set $C_{t}$에 속하고 각 class는 해당 speaking style의 possible value를 represent 함
- Speech Encoder
- Frequency bin 수 $F$, frame 수 $t$에 대해, mel-spectrogram을 $\text{MEL}\in\mathbb{R}^{F\times t}$라고 하자
- 그러면 speech encoding process는:
(Eq. 1) $x=\text{Encoder}(\text{MEL}), \,\,\, x\in\mathbb{R}^{D}$
- $D$ : speech embedding dimension - 이때 ParaMETA는 model-agnostic representation learning framework로써 CNN, LSTM, Q-Former, Standard Transformer와 같은 다양한 encoder backbone architecture를 활용할 수 있음
- CNN-based encoder의 경우 $\text{MEL}$을 convolutional layer과 time dimension에 대한 global mean pooling을 적용하여 fixed-length embedding을 얻음
- LSTM-based encoder의 경우 final hidden state를 sequence representation으로 사용함
- Q-Former는 learnable latent query set을 도입해 cross-attention을 기반으로 spectrogram에 attend 함
- Transformer-based encoder는 $\text{MEL}$에 self-attention과 time step에 대한 sum pooling을 적용해 final embedding을 얻음
- 그러면 speech encoding process는:
- META Embedding
- 논문은 speech embedding $X$를 얻은 다음 META space에서 contrastive learning의 first-stage를 수행함
- 여기서 기존의 contrastive learning은 positive/negative pair를 사용함
- BUT, 해당 binary formulation은 non-identical pair를 equally dissimilar 하게 취급하므로 partially overlapping speaking style 간의 nuanced relationship을 capture 하지 못함 - 이를 해결하기 위해 논문은 positive-to-less-positive contrastive regulation scheme을 채택함
- 즉, 모든 negative pair를 동일하게 취급하지 않고 shared speaking style 수를 기반으로 similarity를 정의함
- 결과적으로 논문은 더 많은 speaking style을 가지는 speech를 더 similar 한 것으로 취급하여 META space에서 closely embedding 되도록 함
- e.g.) $\texttt{[female, happy]}$는 META space에서 $\texttt{[male, sad]}$ 보다 $\texttt{[female, sad]}$에 더 close 해야 함
- Batch size $B$, embedding dimensionality $D$에 대해 $X\in \mathbb{R}^{B\times D}$를 speech embedding batch, $x_{i}\in\mathbb{R}^{D}$를 batch의 $i$-th embedding이라고 하자
- 이때 각 speech sample은 서로 다른 speaking style에 해당하는 $T$ task-specific label을 가짐
- $i$-th sample에서 $t$-th task의 class index $y_{i}^{(t)}$에 대해, task-wise label은 $y_{i}\in\mathbb{Z}^{T}$와 같음
- Batch에 대한 complete label set은 $Y\in \mathbb{Z}^{B\times T}$와 같고 각 row $y_{i}$는 $i$-th embedding에 대한 annotation에 해당함
- 그러면 batch 내 embedding pair $(i,j)$에 대해 shared class의 proportion을 기준으로 class-wise similarity score $w_{i,j}\in[0,1]$을 구할 수 있음
- Similarity는 모든 $T$ task에서 matching label 수의 평균으로 정의되고, final similarity weight $\hat{w}_{i,j}$는 batch 전체에서 self-pair를 제외하고 similarity score를 normalize 하여 얻어짐:
(Eq. 2) $ \hat{w}_{i,j}=\frac{w_{i,j}}{\sum_{k\neq i}w_{i,k}},\,\,\, w_{i,j}=\frac{1}{T}\sum_{t=1}^{T}\nVdash\left[y_{i}^{(t)}=y_{j}^{(t)}\right]$ - 이후 $x_{i}$와 다른 모든 embedding $x_{k}\,\, (k\neq i)$ 간의 cosine similarity에 softmax를 적용하여 sample $j$가 sample $i$의 positive일 log-probability를 compute 함:
(Eq. 3) $\log p_{i,j}=\log \frac{\exp(\cos(x_{i},x_{j}))}{\sum_{k\neq i}\exp(\cos(x_{i},x_{k}))}$
- $\cos(\cdot, \cdot)$ : cosine similarity
- Similarity는 모든 $T$ task에서 matching label 수의 평균으로 정의되고, final similarity weight $\hat{w}_{i,j}$는 batch 전체에서 self-pair를 제외하고 similarity score를 normalize 하여 얻어짐:
- 추가적으로 더 많은 speaking style를 share 하는 sample과 close 하도록 embedding space를 guide 하기 위해, META embedding regularization loss $\mathcal{L}_{META}$를 도입함:
(Eq. 4) $\mathcal{L}_{META}=-\frac{1}{B}\sum_{i=1}^{B}\sum_{j\neq i}^{B}\hat{w}_{i,j}\log p_{i,j}$
- 여기서 기존의 contrastive learning은 positive/negative pair를 사용함

- Task-Specific Embedding
- 논문은 task-wise interference를 줄이기 위해 task-specific structural regularization을 추가적으로 도입함
- 이를 위해 $T$ independent linear projection layer를 사용하여 shared META embedding을 하나의 task에 대한 dedicated sub-space로 mapping 함
- 이는 각 sub-space가 task와 relevant 한 feature에만 exclusively focus 하도록 하여 interpretable, disentangled representation을 유도함 - 먼저 $Z\in\mathbb{R}^{B\times D}$를 shared META embedding의 batch라고 하자
- 각 task $t\in\{1,...,T\}$에 대해, shared embedding을 lower-dimensional task-specific sub-space로 mapping 하는 task-specific linear projection $f_{t}:\mathbb{R}^{D}\rightarrow \mathbb{R}^{d}$를 정의할 수 있음
- 그러면 resulting task-specific embedding은 $z^{(t)}=f_{t}(Z)\in\mathbb{R}^{B\times d}$와 같이 얻어짐 - 이후 각 task 내에서 class-level disciminability를 향상하기 위해 task-specific embedding space에 supervised contrastive loss를 independent 하게 적용함:
(Eq. 5) $\mathcal{P}^{(t)}_{i}=\left\{j|j\neq i,y^{(t)}_{j}=y^{(t)}_{i}\right\}$
- $y_{i}^{(t)}\in C_{t}$ : class label, $z_{i}^{(t)}$ : task $t$의 speech sample $i$의 embedding
- 서로 다른 class label을 가지는 다른 모든 sample $j\neq i$는 negative로 취급함 - 결과적으로 task $t$에 대한 supervised contrastive loss는:
(Eq. 6) $\mathcal{L}_{SCL}^{(t)}=-\frac{1}{B}\sum_{i=1}^{B}\frac{1}{|\mathcal{P}_{i}^{(t)}|}\sum_{j \in\mathcal{P}_{i}^{(t)}}\log\frac{e^{\cos(z_{i},z_{j})}}{\sum_{k\neq i} e^{\cos(z_{k},z_{j})}}$
- 해당 objective는 동일한 class의 embedding이 task-specific sub-space 내에서 closely cluster 되도록 함 - 모든 task에 대한 total supervised contrastive loss는:
(Eq. 7) $\mathcal{L}_{SCL}=\sum_{t=1}^{T}\mathcal{L}_{SCL}^{(t)}$
- (Eq. 7)은 모든 $T$ task 간의 independence를 유지하면서 각 task-specific embedding space의 intra-class compactness와 inter-class separabiltiy를 보장함
- 각 task $t\in\{1,...,T\}$에 대해, shared embedding을 lower-dimensional task-specific sub-space로 mapping 하는 task-specific linear projection $f_{t}:\mathbb{R}^{D}\rightarrow \mathbb{R}^{d}$를 정의할 수 있음
- 이를 위해 $T$ independent linear projection layer를 사용하여 shared META embedding을 하나의 task에 대한 dedicated sub-space로 mapping 함
- Prototype Learning
- Contrastive learning은 classification과 같은 downstream task를 위한 class representation을 제공하지 않음
- 이를 위해 논문은 각 task-specific sub-space 내에서 class anchor로 사용되는 prototype embedding을 도입함
- 먼저 각 task $t$에 대해 prototype matrix를 $P^{(t)}\in\mathbb{R}^{C_{t}\times d}$라고 하자
- 여기서 $C_{t}$는 task $t$의 class 수, $p_{c}^{(t)}\in\mathbb{R}^{d}$는 class $c$의 prototype을 의미함
- e.g.) $p_{\text{adult}}^{(\text{age})}$는 $\texttt{age}$ classification task에서 $\texttt{adult}$ class에 해당하는 prototype과 같음 - 해당 prototype는 randomly initialize 되고 training 시 Exponential Moving Average (EMA) update를 통해 class의 centroid로 gradually move 함
- 즉, task-specific embedding $Z^{(t)}\in\mathbb{R}^{B\times d}$와 해당 class label $y_{i}^{(t)}$가 주어지면 batch 내에서 각 class의 centroid $c\in\{1,...,C_{t}\}$는 다음과 같이 compute 됨:
(Eq. 8) $ z_{c}^{(t)}=\frac{1}{|\mathcal{I}_{c}^{(t)}|}\sum_{i\in \mathcal{I}_{c}^{(t)}}z_{i}^{(t)}, \,\,\,\text{where}\,\,\mathcal{I}_{c}^{(t)}=\left\{i|y_{i}^{(t)}=c\right\}$
- $z_{c}^{(t)}\in\mathbb{R}^{d}$ : current batch 내에서 task $t$의 class $c$에 assign 된 sample의 average embedding - 한편으로 task $t$의 class $c$에 대한 prototype $p_{c}^{(t)}\in\mathbb{R}^{d}$는 EMA를 통해 다음과 같이 update 됨:
(Eq. 9) $p_{c}^{(t)}\leftarrow m\cdot p_{c}^{(t)}+(1-m)\cdot z_{c}^{(t)}$
- $m\in[0,1)$ : momentum coefficient, 논문에서는 $m=0.99$로 설정
- 여기서 $C_{t}$는 task $t$의 class 수, $p_{c}^{(t)}\in\mathbb{R}^{d}$는 class $c$의 prototype을 의미함
- Prototype은 speech embedding의 distributional centroid를 reflect 하지만 추가적으로 embedding 자체가 해당 prototype과 align 되도록 보장할 수 있음
- 이를 위해 논문은 prototype alignment loss $\mathcal{L}_{PAL}$을 도입하여 각 sample embedding을 task-specific sub-space 내에서 해당 class prototype으로 pull 함
- Task $t$에 대해 sample $i$의 task-specific embedding을 $z_{i}^{(t)}\in\mathbb{R}^{d}$, class label $c$의 prototype을 $p_{c}^{(t)}\in\mathbb{R}^{d}$라고 하면, prototype alignment loss $\mathcal{L}_{PAL}$은 다음과 같음:
(Eq. 10) $\mathcal{L}_{PAL}=\sum_{t=1}^{T}\frac{1}{B}\sum_{i=1}^{B}\left(1-\cos\left( z_{i}^{(t)},p_{c}^{(t)}\right)\right)$
- 해당 objective는 각 embedding이 task-specific space 내에서 semantic center와 close 하도록 유도하여 class-level consistency와 learned representation의 discriminative structure를 향상함
- Text and Speech Alignment
- Speech-based, text-based style control을 모두 지원하는 unified framework를 위해 intended speaking style을 describe 하는 style caption을 incorporate 함
- 각 caption은 pre-trained text encoder를 통해 encoding 되고 resulting embedding은 해당 task-specific sub-space로 project 됨
- 이때 modality 간 semantic consistency를 보장하기 위해 동일한 prototype alignment loss를 projected text embedding에 적용함
- 즉, projected embedding과 caption이 참조하는 target style class의 prototype 간의 distance를 minimize 함 - 결과적으로 final training objective는 META space regularization, task-specific supervised contrastive loss, protoype alignment loss를 combine 하여 얻어짐:
(Eq. 11) $\mathcal{L}=\mathcal{L}_{META}+\mathcal{L}_{SCL}+\mathcal{L}_{PAL}^{(Speech)}+\mathcal{L}_{PAL}^{(Text)}$
- Downstram Application
- ParaMETA framework는 disentangled, task-specific paralinguistic embedding을 활용하여 다양한 downstream task에 활용될 수 있음
- Speaking Style Classification
- 먼저 speech input이 주어지면 shared META embedding을 추출하고 projection head를 통해 task-specific representation을 얻음
- 이후 각 task-specific embedding은 cosine similarity를 사용하여 most similar class prototype과 match 됨
- Style Controllable TTS
- Speech-to-Speech setting의 경우 task-specific embedding을 concatenate 해 TTS model을 conditioning 하여 generated speech가 reference의 speaking style을 mimic 하도록 함
- Text-based setting의 경우 desired style에 대한 caption을 encoding 하여 prototype space로 project 하고, 해당 style prototype과 align 하여 speech generation을 conditioning 함
- Speaking Styles Manipulation
- Disentangled embedding을 활용하여 specific speaking style에 대한 fine-grained control을 수행함
- Speaking Style Classification
3. Experiments
- Settings
- Dataset : Baker, LJSpeech, ESD, CREMA-D, Genshin Impact
- Comparisons : CLAP
- Results
- 전체적으로 ParaMETA의 성능이 가장 우수함

- $t$-SNE 결과를 확인해 보면 META space는 distinct cluster를 가짐
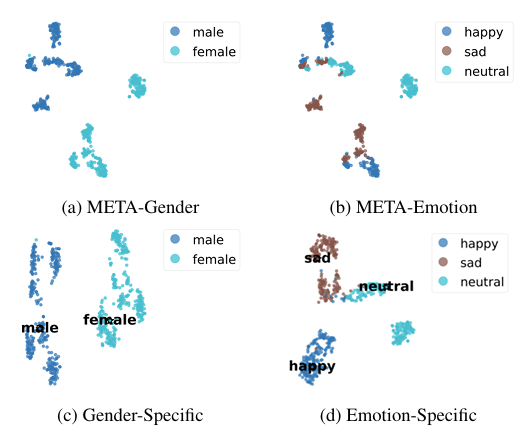
- Style-Controllable TTS
- TTS 측면에서도 뛰어난 성능을 달성함
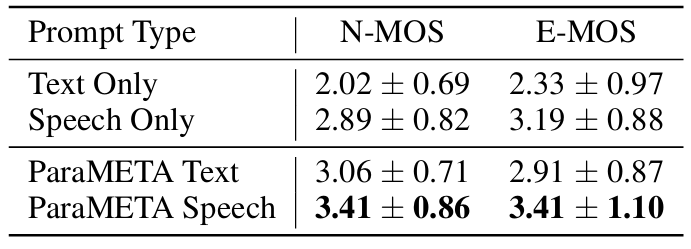
- Speaking Styles Manipulation
- Style manipulation에서도 우수한 성능을 보임

- Computational Resource
- 기존 방식과 비교하여 ParaMETA는 더 적은 resource를 사용함

반응형
'Paper > Representation' 카테고리의 다른 글
댓글