

티스토리 뷰
Paper/TTS
[Paper 리뷰] EME-TTS: Unlocking the Emphasis and Emotion Link in Speech Synthesis
feVeRin 2025. 7. 23. 17:03반응형
EME-TTS: Unlocking the Emphasis and Emotion Link in Speech Synthesis
- Emotional Text-to-Speech와 emphasis-controllable speech synthesis를 integrate 할 수 있음
- EME-TTS
- Emphasis pseudo-label과 variance-based emphasis feature 기반의 weakly supervised learning을 활용
- 추가적으로 Emphasis Perception Enhancement block을 통해 emotion signal과 emphasis position 간의 interaction을 향상
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- 기존의 emotional Text-to-Speech (TTS) model은 speech expressiveness 측면에서 한계가 있음
- 이때 expressive speech를 생성하기 위해서는 prominent prosodic region을 emphasis 할 수 있어야 함
- Emotional TTS와 emphasis-controllable synthesis는 intrinsically link 되어 있기 때문 - 이를 위해서는 다음을 고려해야 함:
- Expressiveness를 향상하기 위해 emphasis를 가장 효과적으로 활용할 수 있는 방법
- 다양한 emotional condition에서 emphasis clarity와 stability를 preserve 할 수 있는 방법
- 이때 expressive speech를 생성하기 위해서는 prominent prosodic region을 emphasis 할 수 있어야 함
-> 그래서 위의 고려사항들을 반영해 emphasis-control과 emotional TTS를 connect한 EME-TTS를 제안
- EME-TTS
- Emotional speech dataset에서 emphasis pseudo-label을 annotate하고 variance-based emphasis modeling approach를 도입
- Emphasis Perception Enhancement (EPE) block을 활용하여 emphasis clarity와 stability를 향상
< Overall of EME-TTS >
- Emphasis pseudo-label, EPE block을 활용한 emphasis-controllable emotional TTS model
- 결과적으로 기존보다 뛰어난 expressiveness를 달성
2. Method
- Overview
- EME-TTS는 EmoSpeech를 기반으로 emotion embedding과 emphasis position을 condition으로 사용함
- 해당 condition은 각각 emotion label과 emphasis pseudo-label을 통해 얻어짐
- 구조적으로 EME-TTS는 phoneme encoder, variance adapter, frame decoder로 구성됨
- Phoneme encoder는 text에서 추출된 input phoneme sequence를 phonetic feature로 encoding 함
- Variance adapter는 duration, pitch, energy modeling을 통해 explicit emphasis control을 위한 variance-based emphasis feature를 integrate 함
- Frame decoder는 frame-level hidden representation을 mel-spectrogram으로 변환함

- Weakly Supervised Emphasis Pseudo-Labeling
- Sentence 내에서 word emphasis를 결정하는 것에는 상당한 subjectivity가 관여하므로 multiple valid emphasis position이 존재할 수 있음
- 따라서 large-scale labeled emphasis data를 확보하는 것에는 한계가 있음
- 이를 위해 논문은 Continuous Wavelet Transform (CWT)를 통해 prominence score를 compute 하는 기존 EE-TTS와 달리 EmphaClass emphasis recognizer를 활용함
- EmphaClass는 frame-level classification을 위해 pre-trained Self-Supervised Learning (SSL) speech model을 fine-tuning 하고, score를 aggregate 하여 word-level emphasis를 결정함
- 결과적으로 논문은 EmphaClass를 통해 Emotional Speech Dataset (ESD)를 annotate 하여 emphasis pseudo-label을 얻음
- Variance Adapter
- Variance adapter는 prosodic variation을 modeling 하고 regulate 함
- 구조적으로 variance adapter는 encoded phoneme에서 각각의 prosodic feature를 predict 하는 pitch, duration, energy predictor로 구성됨
- 추가적으로 emphasized region의 local deviation을 capture 하여 해당 prediction을 refine 하는 variance-based pitch, duration predictor를 포함함
- Upsampling mechanism은 phoneme-level prosodic feature가 decoder로 전달되기 전에 frame-level hidden sequence에 align 되도록 보장함
- 논문은 emphasis를 explicitly control 하기 위해 variance-based prosodic feature를 local modulation signal로 incorporate 함
- 특히 energy를 omit 하고 pitch, duration variance feature만 modeling 함
- 이때 variance feature는 다음과 같이 formulate 됨:
(Eq. 1) $\text{Pitch Variance}=W_{F_{0}}-S_{F_{0}}$
(Eq. 2) $\text{Duration Variance} = W_{dur}-S_{dur}$
- $W_{F_{0}}, W_{dur}$ : emphasized region 내 phoneme의 average pitch, duration
- $S_{F_{0}}, S_{dur}$ : sentence-level average - 위의 value는 emphasized word의 $\text{start},\text{end}$를 제공하는 emphasis pseudo-label을 사용하여 variance pitch predictor, variance duration predictor을 통해 얻어짐
- Training 시 predicted pitch feature $P_{pre}$는 (Eq. 1)을 통해 pitch variance feature $P_{pre}^{V}$를 compute 하는 데 사용되고, 해당 loss는 target pitch feature $P_{tar}$를 사용하여 얻어짐:
(Eq. 3) $\mathcal{L}_{P}=\text{MSE}\left(P_{pre}+P_{pre}^{V},P_{tar}\right)$
- $\text{MSE}$ : predicted, target value 간의 Mean Squared Error - 마찬가지로 pitch variance loss는:
(Eq. 4) $\mathcal{L}_{P}^{V}=\text{MSE}\left(P_{pre}^{V},P_{tar}^{V}\right)$ - Duration modeling에도 동일한 approach를 활용할 수 있음:
(Eq. 5) $\mathcal{L}_{D}=\text{MSE}\left(D_{pre}+D_{pre}^{V},D_{tar}\right)$
(Eq. 6) $\mathcal{L}_{D}^{V}=\text{MSE}\left(D_{pre}^{V},D_{tar}^{V}\right)$
- Variance feature $P_{pre}^{V}, D_{pre}^{V}$는 emphasized region에만 적용되고, non-emphasized region은 $0$으로 설정됨
- 이때 direct variance calculation은 extreme value나 negative emphasis score로 이어질 수 있으므로 data distribution에 따라 feature를 $[0,2]$ range로 normalize 하고 regularization을 적용함
- 구조적으로 variance adapter는 encoded phoneme에서 각각의 prosodic feature를 predict 하는 pitch, duration, energy predictor로 구성됨
- Emphasis Perception Enhancement Block
- EME-TTS의 phoneme encoder와 frame decoder는 기존 Feed-Forward Transformer block을 multiple stacked Emphasis Perception Enhancement (EPE) block으로 replace 하여 구성됨
- 각 EPE block은 Multi-Head Attention (MHA), Conditional Cross Attention (CCA), Emphasis Adapter (EA)를 integrate 하여 emphasis perception modeling을 refine 하고, stable emphasis를 maintain 하도록 보장함
- 이때 input hidden sequence는 self-attention 및 conditional normalization layer를 통해 처리된 다음, convolutional layer를 통해 further refine 됨
- Emotion embedding과 emphasis position은 external condition으로 작용함 - MHA는 hidden sequence 내의 global dependency를 capture 하여 model이 phoneme 간의 contextual relationship을 추출할 수 있도록 함
- CCA는 emotional cue를 incorporate 하여 self-attention을 re-weight 하고 attention distribution을 주어진 emotion embedding $c$에 따라 adjust 할 수 있도록 함:
(Eq. 7) $ Q=W_{q}\cdot h, \,\, K=W_{k}\cdot c,\,\, V=W_{v}\cdot c$
(Eq. 8) $w=\text{softmax}\left(\frac{Q\cdot K^{\top}}{\sqrt{d}}\right)$
(Eq. 9) $\text{CCA}=w\cdot V$
- $h$ : input feature, $w$ : computed attention weight
- 이때 input hidden sequence는 self-attention 및 conditional normalization layer를 통해 처리된 다음, convolutional layer를 통해 further refine 됨
- 한편으로 expressive speech에서 특정 word의 prominence는 emotion에 따라 변하므로 emphasis perception의 inconsistency로 이어질 수 있음
- 이로 인해 emphasis position의 unintended shift나 artifact가 발생하여 speech quality가 저하될 수 있음 - 이를 해결하기 위해 논문은 pre-defined emphasis region에서 attention distribution을 refine 하는 EA를 도입함
- 여기서 EA는 emotional variation으로 인한 interference를 minimize 하면서 emphasis perceptibility를 explicitly enhance 하는 것을 목표로 함
- 즉, initial attention weight $w$가 주어지면 adjust weight는 다음과 같이 compute 됨:
(Eq. 10) $w_{adjusted}=w+\Delta w,\,\,\, \Delta w=\text{strength}\cdot \text{mask}(\text{start},\text{end})$
- $\text{mask}(\text{start},\text{end})$ : designated emphasis position을 identify 하는 역할
- $\text{strength}$ : emphasis intensity를 scale 하는 역할 - 결과적으로 EA를 통해 emphasized word가 perceptually distinct 하도록 보장하고, attention modulation을 통해 emphasis representation을 refine 하여 artifact를 reduce 할 수 있음
- 각 EPE block은 Multi-Head Attention (MHA), Conditional Cross Attention (CCA), Emphasis Adapter (EA)를 integrate 하여 emphasis perception modeling을 refine 하고, stable emphasis를 maintain 하도록 보장함
3. Experiments
- Settings
- Dataset : Emotional Speech Dataset (ESD)
- Comparisons : EmoSpeech, CosyVoice2
- Results
- EPE를 사용하면 emphasis accuracy를 향상할 수 있음

- Emotion accuracy 측면에서도 EME-TTS가 가장 우수함
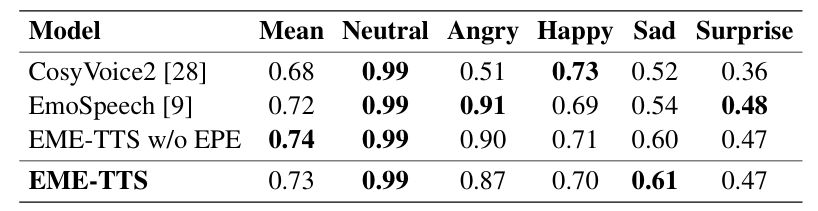
- EME-TTS는 subjective evaluation에서도 뛰어난 성능을 보임
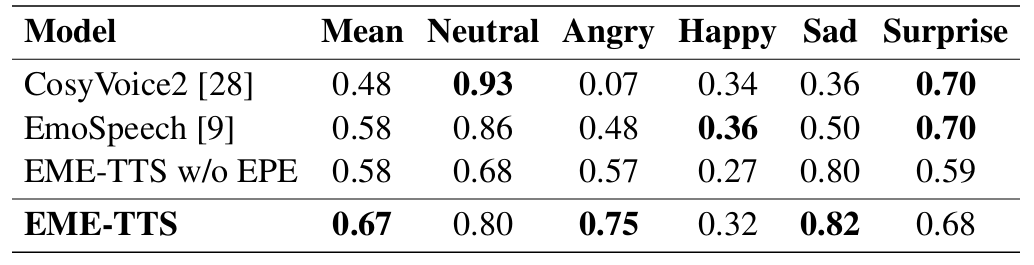
- Improvement of Emotional Expressiveness through Emphasis
- EME-TTS는 isolated, contextual sentence 모두에서 expressive speech를 생성할 수 있음
- 특히 contextualized setting에서 더 나은 expressiveness를 달성함

- Speech Quality and Naturalness
- Naturalness 측면에서도 우수한 품질을 달성함
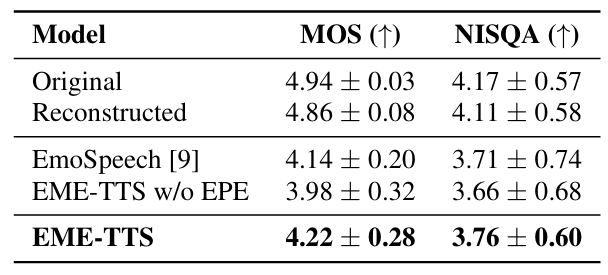
반응형
'Paper > TTS' 카테고리의 다른 글
댓글