

 [Paper 리뷰] DualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance
[Paper 리뷰] DualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance
DualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance다양한 control demand 하에서 speaker-fidelity와 text-intelligibility 간의 optimal balance를 달성하는 것은 어려움DualSpeechPhoneme-level latent diffusion과 Dual classifier-free guidance를 도입Sophisticated control을 통해 fidelity와 intelligibility를 향상논문 (INTERSPEECH 2024) : Paper Link1. IntroductionText-to-Speech (TTS)는 hum..
 [Paper 리뷰] FlashSpeech: Efficient Zero-Shot Speech Synthesis
[Paper 리뷰] FlashSpeech: Efficient Zero-Shot Speech Synthesis
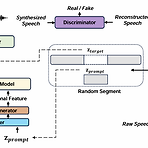
FlashSpeech: Efficient Zero-Shot Speech Synthesis최근의 large-scale zero-shot speech synthesis는 language model과 diffusion을 기반으로 구축되므로 computationally intensive 하고 generation process가 느림FlashSpeechLatent consistency model을 기반으로 adversarial consistency training을 도입Prosody generator module을 통해 prosody diversity를 향상논문 (MM 2024) : Paper Link1. IntroductionText-to-Speech (TTS)에서 zero-shot synthesis는 addi..
 [Paper 리뷰] PitchFlow: Adding Pitch Control to a Flow-Matching based TTS Model
[Paper 리뷰] PitchFlow: Adding Pitch Control to a Flow-Matching based TTS Model
PitchFlow: Adding Pitch Control to a Flow-Matching based TTS ModelFlow-matching Text-to-Speech model은 stability와 control 측면에서 한계가 있음PitchFlowSpeaker scoring과 pitch guidance를 도입하여 생성된 speech의 timbre와 pitch contour를 controlPrior에 대한 optimal choice를 통해 similarity를 개선하고 classifier guidance를 통해 fine-grained pitch contorl을 지원논문 (INTERSPEECH 2024) : Paper Link1. Introduction최근의 Text-to-Speech (TTS) mod..
 [Paper 리뷰] NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTS
[Paper 리뷰] NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTS
NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTSExpressive text-to-speech는 다음의 어려움이 존재함- Reference audio에 background noise가 포함된 경우 highly dynamic prosody information을 추출하기 어려움- Unseen speaking style에 대한 generalization이 가능해야 함NoreSpeechKnowledge distillation을 통해 teacher model에서 noise-agnostic speaking style을 학습하는 diffusion model에 기반한 DiffStyle m..
 [Paper 리뷰] GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
[Paper 리뷰] GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-SpeechCross-lingual text-to-speech는 다음의 어려움이 있음- Timbre, pronunciation은 서로 correlate 되어 있음- Speech style에는 language-agnostic, language-specific part가 포함되어 있음GenerTTSPronunciation/style과 timbre를 disentangle 하기 위해 HuBERT-based information bottleneck을 도입Language-specific information을 제거하기 위해 style, ..
 [Paper 리뷰] MultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-Speech
[Paper 리뷰] MultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-Speech
MultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-SpeechZero-Shot Text-to-Speech를 위해서는 많은 training data가 필요하고 기존보다 cost 증가함MultiVerse기존의 data-driven method 보다 더 적은 training data를 사용하면서 zero-shot 환경에서 Text-to-Speech, Style transfer를 수행하는 multi-task modelSource-filter theory-based disentanglement를 활용하고 filter-related/source-related representation을 모델링하기 위한 prompt를 도입Prosody similar..