

 [Paper 리뷰] Fast Hardware-aware Neural Architecture Search
[Paper 리뷰] Fast Hardware-aware Neural Architecture Search
Fast Hardware-aware Neural Architecture Search 다양하고 많은 양의 hardware에 대해 최적의 convolutional neural architecture를 설계하는 것은 어려움 Neural Architecture Search (NAS)는 이러한 hardware 다양성 문제를 고려해야함 HURRICANE 더 큰 search space를 통한 automatic hardware-aware search Two-stage search algorithm을 통한 다양한 hardware 맞춤형 최적화 논문 (CVPRW 2020) : Paper Link 1. Introduction 다양한 유형의 hardware device와 막대한 search cost는 NAS 적용의 주요한 걸..
 [Paper 리뷰] Zen-NAS: A Zero-Shot NAS for High-Performance Image Recognition
[Paper 리뷰] Zen-NAS: A Zero-Shot NAS for High-Performance Image Recognition
Zen-NAS: A Zero-Shot NAS for High-Performance Image Recognition Accuracy predictor는 Neural Architecture Search (NAS)의 핵심 구성요소 높은 성능의 accuracy predictor를 구현하려면 상당한 양의 계산이 필요함 Zen-Score Network expressivity를 나타내는 새로운 zero-shot index 모델의 accuray와 양의 상관관계를 가짐 학습된 network parameter 없이 무작위로 초기화된 network를 통해 few forward 추론만 수행 Zen-NAS Zen-Score를 기반으로 주어진 추론 예산하에서 target network의 Zen-Score를 최대화하는 NAS 알고..
 [Paper 리뷰] HELP: Hardware-Adaptive Efficient Latency Prediction for NAS via Meta-Learning
[Paper 리뷰] HELP: Hardware-Adaptive Efficient Latency Prediction for NAS via Meta-Learning
HELP: Hardware-Adaptive Efficient Latency Prediction for NAS via Meta-Learning 배포와 device별 제약 조건을 만족하기 위해 Neural Architecture Search (NAS)는 hardware를 고려해야 함 기존에는 Lookup table / Latency estimator를 통해 target device의 latency sample을 수집 -> 서로 다른 사양의 hardware를 많이 요구하기 때문에 비실용적임 Hardware-adaptive Efficient Latency Predictor (HELP) Device별 latency 추정 문제를 meta-learning 문제로 공식화 Latency를 출력하는 black-box를 고..
 [Paper 리뷰] MAE-DET: Revisiting Maximum Entropy Principle in Zero-Shot NAS for Efficient Object Detection
[Paper 리뷰] MAE-DET: Revisiting Maximum Entropy Principle in Zero-Shot NAS for Efficient Object Detection
MAE-DET: Revisiting Maximum Entropy Principle in Zero-Shot NAS for Efficient Object Detection Object detection에서 backbone architecture의 추론 시간을 줄이기 위해 Nerual Architecture Search (NAS)를 도입 기존 NAS 방식은 GPU 및 시간 자원이 많이 필요하므로 빠른 연구 개발을 위해 Zero-shot NAS 방식을 제안 MAE-DET Maximun Entropy Principle을 통해 network parameter를 훈련시키지 않고 효율적인 detection backbone을 설계 Architecture desgin 비용은 zero에 가깝지만 SOTA의 성능을 발휘 De..
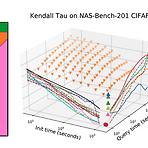 [Paper 리뷰] How Powerful Are Performance Predictors in Neural Architecture Search?
[Paper 리뷰] How Powerful Are Performance Predictors in Neural Architecture Search?
How Powerful Are Performance Predictors in Neural Architecture Search? Neural Architecture Search (NAS)의 계산 비용을 줄이기 위해서 neural architecture의 성능을 예측하는 방식이 제안됨 Performance predictor는 NAS에서 효과적이지만, 최적화된 Initialization time, Query time 설정과 합의된 평가 지표의 부족으로 다양한 Performance predictor들 간의 효과적인 비교가 어려움 여러 Performance predictor들에 대한 대규모 연구 결과 제시 Learning curve extrapolation, Weight-sharing, Supervised lea..
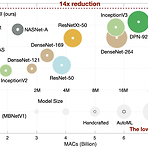 [Paper 리뷰] Once-For-All: Train One Network and Specialize it for Efficient Deployment
[Paper 리뷰] Once-For-All: Train One Network and Specialize it for Efficient Deployment
Once-For-All: Train One Network and Specialize it for Efficient Deployment 다양한 edge device에서 자원 제약을 만족하는 효율적인 inference의 어려움 Once-For-All (OFA) training / search를 분리하여 cost를 줄임 OFA에서 추가적인 training 없이 sub-network를 얻을 수 있음 Progressive Shrinking OFA network training을 위해 제안 -> depth/width/kernel/resolution pruning 논문 (ICRL 2020) : Paper Link OFA의 개선버전 : CompOFA 리뷰 1. Introduction model size의 증가는 har..