

 [Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
[Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
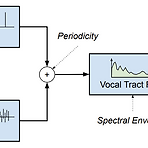
Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech SynthesisNeural vocoder를 통해 고품질의 audio를 합성할 수 있지만, 여전히 low-end device에서는 real-time으로 사용하기 어려움한편으로 Digital Signal Processing 기반의 vocoder는 lightweight FFT를 통해 구현될 수 있으므로 neural vocoder보다 빠르게 동작가능함- BUT, vocal tract의 approximate representation에 대해 over-smoothed acoustic model prediction을 사용하므로 합성 품질이 저하되는 경향이 있음DDSP VocoderDi..
 [Paper 리뷰] DeviceTTS: A Small-Footprint, Fast, Stable Network for On-device Text-to-Speech
[Paper 리뷰] DeviceTTS: A Small-Footprint, Fast, Stable Network for On-device Text-to-Speech
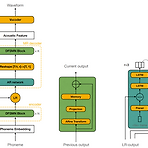
DeviceTTS: A Small-Footprint, Fast, Stable Network for On-device Text-to-Speech기존의 tex-to-speech 모델은 크고 복잡한 network로 구성되기 때문에, 원활한 배포를 지원할 수 있는 on-device text-to-speech에 적합한 모델이 필요함DeviceTTSDuration predictor를 통해 encoder, decoder 간의 bridge를 제공모델 size를 줄이기 위해 Deep Feedforward Sequential Memory Network (DFSMN)을 도입추가적으로 추론 속도를 높이기 위해, mix-resolution decoder를 채택논문 (ICASSP 2021) : Paper Link1. Introd..
 [Paper 리뷰] BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extraction and Waveform Generation
[Paper 리뷰] BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extraction and Waveform Generation
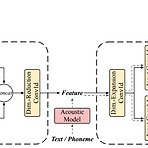
BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extraction and Waveform GenerationSTFT domain 내에서 feature extraction과 reverse waveform generation이 가능한 vocoder를 구성할 수 있음BiVocoderFeature extraction을 위해 STFT에서 파생된 amplitude, phase spectrea를 input으로 사용하고, 이를 convolution network를 통해 long-frame-shift, low-dimensional feature로 변환Waveform generation을 위해 symmetric network를 채택하여 amplitude, p..
 [Paper 리뷰] VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
[Paper 리뷰] VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
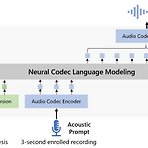
VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech SynthesizersText-to-Speech를 위해 language modeling을 활용할 수 있음VALL-ENeural audio codec에서 파생된 discrete code를 사용하여 training 된 language model기존의 continuous signal regression이 아닌 conditional language modeling으로 text-to-speech를 접근특히 in-context learning capability를 제공하여 unseen speaker를 3초 이내의 acoustic prompt를 통해 personalized speech를 합성 가능논문..
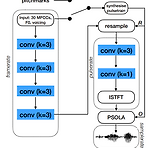 [Paper 리뷰] Puffin: Pitch-Synchronous Neural Waveform Generation for Fullband Speech on Modest Devices
[Paper 리뷰] Puffin: Pitch-Synchronous Neural Waveform Generation for Fullband Speech on Modest Devices
Puffin: Pitch-Synchronous Neural Waveform Generation for Fullband Speech on Modest DevicesLow-powered device에서 사용할 수 있는 neural vocoder가 필요함PuffinDifferentiable pitch synchronous overlap-add를 사용하여 adversarially training 하고,Speech sample을 생성하기 위해 pitch synchronous inverse STFT를 채택논문 (ICASSP 2023) : Paper Link1. IntroductionNeural vocoder는 data-driven 방식으로 human speech 수준의 합성 품질을 달성하고 있음이러한 음성 합성 모..
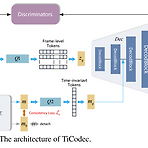 [Paper 리뷰] Fewer-Token Neural Speech Codec with Time-Invariant Codes
[Paper 리뷰] Fewer-Token Neural Speech Codec with Time-Invariant Codes
Fewer-Token Neural Speech Codec with Time-Invariant CodesNeural codec은 speech를 discrete token으로 변환하는 데 사용되지만, excessive token sequence는 오히려 prediction accuracy에 부정적인 영향을 줄 수 있음TiCodecTime-invariant information을 별도의 code로 encoding/quantizing하여 encoding에 사용되는 frame-level information의 양을 줄임Utterance에서 time-invariant code의 consistency를 향상하기 위해, time-invariant encoding consistency loss를 도입논문 (ICASSP ..