

티스토리 뷰
Paper/TTS
[Paper 리뷰] ImmersiveTTS: Environment-Aware Text-to-Speech with Multimodal Diffusion Transformer and Domain-Specific Representation Alignment
feVeRin 2026. 7. 2. 14:37반응형
ImmersiveTTS: Environment-Aware Text-to-Speech with Multimodal Diffusion Transformer and Domain-Specific Representation Alignment
- Environmental audio와 함께 speech를 jointly generate 하는 것은 어려움
- ImmersiveTTS
- Mutimodal diffusion Transformer를 기반으로 transcript-aligned speech latent와 text-conditioned environmental context를 joint attention으로 fuse
- Semantic consistency를 향상하기 위해 domain-specific representation alignment objective를 도입
- 논문 (ACL 2026) : Paper Link
1. Introduction
- Text-guided audio generation은 크게 Text-to-Speech (TTS)와 Text-to-Audio (TTA)로 나뉨
- TTA는 natural language description을 기반으로 non-speech audio를 생성하고, TTS는 text input을 기반으로 natural-sounding human speech waveform을 생성함
- BUT, TTA는 linguistic content가 포함된 human speech를 생성하기 어렵고, TTS는 acoustic environment를 반영하기 어려움
- 즉, heterogeneous audio sub-modality를 single model에서 synthesis 할 수 없음 - 이를 위해 VoiceLDM과 같은 environment-aware TTS model을 고려할 수 있지만, 여전히 naturalness 측면에서 한계가 있음
-> 그래서 speech와 environmental audio를 explicitly modeling할 수 있는 ImmersiveTTS를 제안
- ImmersiveTTS
- Multimodal Diffusion Transformer (MM-DiT)를 기반으로 dual-stream backbone을 구축해 transcript-aligned speech feature와 text-conditioned environmental context에 assign
- 추가적으로 Representation Alignment (REPA) strategy를 활용하여 cross-modal learning을 개선
< Overall of ImmersiveTTS >
- Dual-stream architecture를 활용해 speech, environmental audio를 modeling 하는 environment-aware TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Preliminaries on Flow Matching
- Flow matching은 $\mathbb{R}^{d_{z}}$에서 simple prior $\pi_{0}$와 data distribution $\pi_{1}$ 간의 transformation을 학습함
- 해당 transformation은 time $t\in[0,1]$에 대해 Ordinary Differential Equation (ODE)로 정의됨:
(Eq. 1) $ \frac{d}{dt}Z_{t}=v(Z_{t},t),\,\,\,Z_{0}\sim\pi_{0},\,\,\,Z_{1}\sim\pi_{1}$
- $v:\mathbb{R}^{d_{z}}\times[0,1]\rightarrow \mathbb{R}^{d_{z}}$ : time-dependent velocity field, $\pi_{0}$ : standard Gaussian distribution $\mathcal{N}(0,I)$ - Field는 neural network $v_{\theta}$로 parameterize 되고, random pair $(Z_{0},Z_{1})$을 connecting 하는 staright path의 veclocity와 neural network velocity 간의 Mean Squared Error를 minimize 하여 training 됨:
(Eq. 2) $\mathcal{L}_{Flow}(\theta)=\mathbb{E}_{t,Z_{0},Z_{1}}\left[\left|\left| (Z_{1}-Z_{0})-v_{\theta}(Z_{t},t)\right|\right|^{2}\right]$
-$Z_{t}=(1-t)Z_{0}+tZ_{1}$ : $Z_{0}\sim\pi_{0}, Z_{1}\sim \pi_{1}$ 간의 linear interpolation, $t\in[0,1]$ : time step - Learned velocity field $v_{\theta}$가 주어지면 flow-based model은 sample을 straight trajectory를 따라 prior $\pi_{\theta}$에서 target distribution $\pi_{1}$로 transport 함
- 해당 transformation은 time $t\in[0,1]$에 대해 Ordinary Differential Equation (ODE)로 정의됨:
- Audio Compression
- Speech, general audio characteristic에 대한 unified latent space를 capture 하기 위해 AudioLDM2의 pre-trained Variational AutoEncoder (VAE)를 사용함
- $X_{wav}\in\mathbb{R}^{d\cdot f_{s}}$를 duration $d$, sampling rate $f_{s}$의 raw waveform이라고 하자
- Mel bin $F$, mel-spectrogram length $L$에 대해, $X_{wav}$는 log-mel spectrogram $X_{mel}\in\mathbb{R}^{F\times L}$로 convert 됨
- VAE encoder는 time-frequency axis를 $\times 4$로 downsampling 하여 $X_{mel}$을 latent representation $Z\in\mathbb{R}^{8\times F/4\times L/4}$로 compress 함
- 이후 VAE decoder는 $Z$로부터 $\hat{X}_{mel}$을 reconstruct하고 pre-trained vocoder를 통해 $\hat{X}_{mel}$을 waveform $\hat{X}_{wav}$로 convert 함
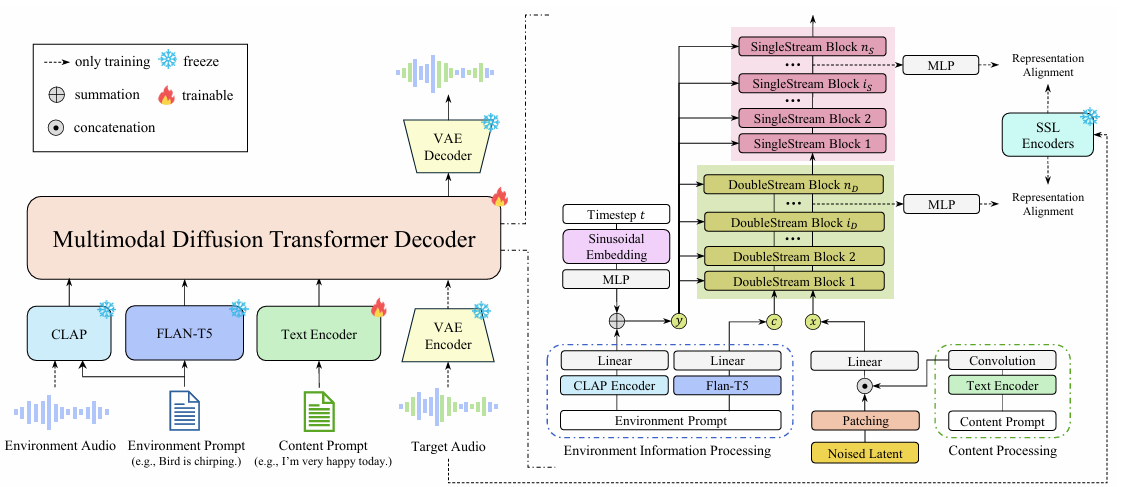
- Multimodal Diffusion Transformer for Environment-Aware Text-to-Speech
- 논문은 linguistic content를 preserve 하면서 environmental context와 align 하는 speech를 생성하는 것을 목표로 함
- Model은 content prompt $y_{cont}$, environment prompt $y_{env}$의 2가지 textual input으로 condition 됨
- 특히 speech latent와 environmental cue 간의 interplay를 modeling 하기 위해 MM-DiT backbone을 사용하고, Flux architecture를 활용해 high-fidelity synthesis를 수행함
- Double-stream stage는 $y_{env}$에서 derive 된 fine-grained environment context token을 encode 하는 environmental context stream과 $y_{cont}$로 condition 되어 noisy audio latent $Z_{t}$를 process 하는 speech stream으로 구성됨
- 이때 parallel stream은 joint attention을 통해 information exchange를 수행함 - 이후 speech stream의 representation을 single-stream block으로 forward 하여 self-attention layer를 통해 further refine 함
- Double-stream stage는 $y_{env}$에서 derive 된 fine-grained environment context token을 encode 하는 environmental context stream과 $y_{cont}$로 condition 되어 noisy audio latent $Z_{t}$를 process 하는 speech stream으로 구성됨
- Environmental Context Stream
- Audio generation을 위해 coarse, global sound semantic encoder인 CLAP과 fine-grained detail encoder인 T5 encoder를 고려함
- 먼저 $y_{env}$에서 CLAP embedding을 MLP를 사용해 project 하고, diffusion timestep embedding과 combine 하여 AdaLN module을 condition 함
- 이때 AdaLN scale과 shift parameter $(\gamma, \beta)$를 Transformer block에 대해 modulate 하여 generation process를 globally condition 할 수 있음 - 추가적으로 $y_{env}$의 token-level T5 embedding에 linear projection을 적용하고 environment context에 대한 input sequence로 사용함
- 이를 통해 double-stream layer에서 joint attention을 활용해 local environmental detail에 selectively attend 할 수 있음
- 먼저 $y_{env}$에서 CLAP embedding을 MLP를 사용해 project 하고, diffusion timestep embedding과 combine 하여 AdaLN module을 condition 함
- Audio generation을 위해 coarse, global sound semantic encoder인 CLAP과 fine-grained detail encoder인 T5 encoder를 고려함
- Environment-Aware Speech Stream
- Content prompt $y_{cont}$를 follow 하는 intelligible speech를 생성하기 위해, 논문은 linguistic feature를 speech stream에 directly inject 하는 explicit temporal alignment를 도입함
- Glow-TTS를 따라 text encoder는 $y_{cont}$를 hidden representation $\tilde{\mu}_{1:L}$로 convert 하고 Monotonic Alignment Search (MAS)는 phoneme-level duration $d'_{1:L}$을 estimate 함
- 이후 hidden vector는 $d'$을 기준으로 expand 되어 frame-level pior mel representation $\mu$를 생성함
- Text encoder, duration predictor는 prior loss $\mathcal{L}_{Prior}$와 MAS-based duration loss $\mathcal{L}_{Dur}$로 optimize 됨
- Prior representation $\mu$를 audio latent space와 align 하기 위해, $\mu$를 convolution network로 process 함
- 이를 통해 얻어진 feature는 noisy latent $Z_{t}$와 channel dimension으로 concatenate 되고 environment-aware speech stream으로 전달됨
- 해당 speech stream은 MM-DiT layer 내에서 environment context stream sequence와 joint attention 되어 information exchange를 수행함

- Domain-Specific Representation Alignment
- Training stability를 향상하기 위해 논문은 REPA strategy를 도입함
- Domain-Specific SSL Encoders
- Domain-specific REPA를 위해 WavLM, ATST-Frame을 target encoder로 하는 dual-teacher strategy를 적용함
- WavLM은 speech-specialized SSL model로써 precise phonetic, linguistic fidelity를 위해 사용됨
- ATST-Frame은 audio-specialized SSL model로써 rich environmental acoustic event를 capture 함
- Alignment Objective
- $K$ pre-trained SSL encoder set을 $\{E_{k}\}_{k=1}^{K}$라고 하자
- Target audio $X\sim p_{data}$에 대해 $k$-th encoder는 target representation $r_{k}=E_{k}(X)\in \mathbb{R}^{B\times L_{k}\times D_{k}}$를 생성함
- $B$ : batch size, $L_{k}$ : sequence length, $D_{k}$ : sequence dimensionality - 이때 model은 해당 target과 align 되기 위해 speech stream의 intermediate layer에서 hidden feature $h_{k}\in\mathbb{R}^{B\times L_{h}\times D_{h}}$를 추출함
- 이후 MLP projector를 통해 $h'_{k}=\text{MLP}_{k}(h_{k})$로 project 하여 Transformer feature를 encoder representation space로 mapping 함 - 다음으로 projected feature $h'_{k}$, target feature $r_{k}$의 temporal resolution을 interpolate/pooling 하여 common temporal length $\tilde{L}$에 match 하고, synchronized sequence $\tilde{h}'_{k},\tilde{r}_{k}$를 얻음
- Target audio $X\sim p_{data}$에 대해 $k$-th encoder는 target representation $r_{k}=E_{k}(X)\in \mathbb{R}^{B\times L_{k}\times D_{k}}$를 생성함
- 이때 REPA loss는 cosine similarity $\text{CosSim}(\cdot, \cdot)$으로 정의됨:
(Eq. 3) $\mathcal{L}_{SSL_{k}}=-\mathbb{E}_{X}\left[\text{CosSim}\left(\tilde{r}_{k}, \tilde{h}'_{k}\right)\right]$ - 결과적으로 total objective는 domain-specific alignment loss의 weighted sum으로 얻어짐:
(Eq. 4) $\mathcal{L}_{REPA}=\sum_{k=1}^{K}\lambda_{k}\mathcal{L}_{SSL_{k}}$
- $\lambda_{k}=1$ : hyperparameter
- $K$ pre-trained SSL encoder set을 $\{E_{k}\}_{k=1}^{K}$라고 하자
- Training and Inference
- Training
- ImmersiveTTS는 4가지 loss로 training 됨
- Velocity predictor와 convolutional mapper는 flow matching objective $\mathcal{L}_{Flow}$와 alignment objective $\mathcal{L}_{REPA}$로 optimize 됨
- Text encoder와 duration predictor는 conditioning path를 통해 backpropagate 된 gradient를 receive 하고 MAS-based prior loss $\mathcal{L}_{Prior}$, duration loss $\mathcal{L}_{Dur}$로 supervise 됨
- 결과적으로 final objective loss는:
(Eq. 5) $\mathcal{L}=\lambda_{P}\mathcal{L}_{Prior}+ \lambda_{D}\mathcal{L}_{Dur}+\lambda_{F}\mathcal{L}_{Flow}+\lambda_{R}\mathcal{L}_{REPA}$
- Training 시 CLAP, T5 encoder는 freeze 되고 time step $t\in(0,1)$은 mean $0$, variance $1$의 logit-Normal distribution에서 draw 됨 - 추가적으로 논문은 flexible control을 위해 content, environment prompt sequence를 $0.1$ probability로 independently masking 하는 Classifier-Free Guidance (CFG)를 채택함
- ImmersiveTTS는 4가지 loss로 training 됨
- Inference
- 먼저 random noise $Z_{0}\sim \mathcal{N}(0,I)$에서 sampling을 수행함
- 이때 explicit velocity field는 dual-CFG를 사용해 adjust 됨:
(Eq. 6) $\tilde{v}_{\theta}(Z_{t},y_{env},y_{cont})=v_{\theta}(Z_{t},y_{env},y_{cont}) + \omega_{env}\left(v_{\theta}(Z_{t},y_{env},\emptyset_{cont})-v_{\theta}(Z_{t},\emptyset_{env},\emptyset_{cont})\right) +\omega_{cont}\left(v_{\theta}(Z_{t},\emptyset_{env},y_{cont})-v_{\theta}(Z_{t},\emptyset_{env},\emptyset_{cont})\right)$
- $\omega_{env},\omega_{cont}$ : 각 modality 별 guidance scale, $\emptyset_{env}, \emptyset_{cont}$ : 각 modality 별 null-condition - 그런 다음 Euler method를 사용해 (Eq. 1)의 ODE를 solve 함:
(Eq. 7) $Z_{t+\tau}=Z_{t}+\tau\cdot \tilde{v}_{\theta}(Z_{t},t,y_{env},y_{cont})$
- 생성된 latent는 VAE decoder로 decode 되고 pre-trained vocoder를 통해 waveform으로 synthesize 됨
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : VoiceLDM, VoiceDiT
- Results
- 전체적으로 ImmersiveTTS의 성능이 가장 뛰어남

- Seed-TTS dataset에 대해서도 우수한 성능을 보임

- Objective evaluation 측면에서도 ImmersiveTTS가 가장 뛰어난 성능을 보임

- Representation Alignment
- 서로 다른 teacher alignment strategy에 대해 WavLM, ATST 조합을 사용했을 때 최고의 성능을 달성함

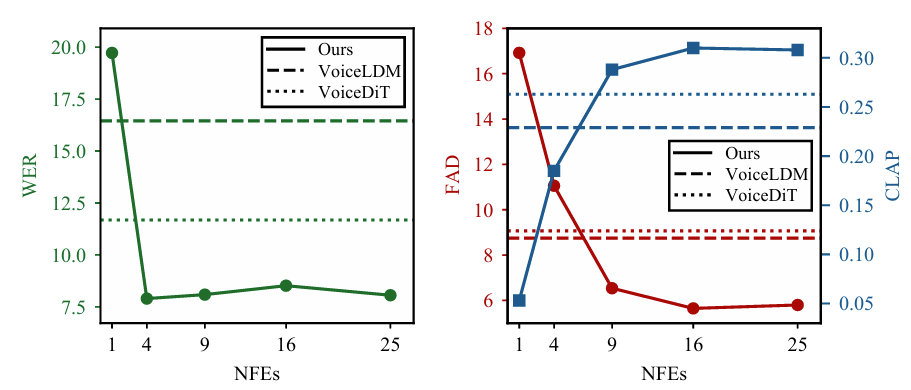
- Sampling Step
- $9$ sampling step을 사용했을 때 최적의 trade-off를 만족함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글