

티스토리 뷰
Paper/TTS
[Paper 리뷰] UMETTS: A Unified Framework for Emotional Text-to-Speech Synthesis with Multimodal Prompts
feVeRin 2025. 4. 3. 19:51반응형
UMETTS: A Unified Framework for Emotional Text-to-Speech Synthesis with Multimodal Prompts
- Emotional Text-to-Speech (TTS)는 oversimplified emotional label이나 single-modality input에 의존하므로 human emotion을 효과적으로 반영하지 못함
- UMETTS
- Emotion Prompt Alignment module과 Emotion Embedding-Induced TTS module을 활용하여 multiple modality의 emotional cue를 반영
- Emotion Prompt Alignment module은 contrastive learning을 통해 text, audio, vision modality에서 얻은 emotional feature를 align 하고 multimodal information에 대한 coherent fusion을 지원
- Emotion Embedding-Induced TTS module은 aligned emotional embedding을 text-to-speech model에 integrate 하여 intended emotion을 accurately reflect
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Emotional Text-to-Speech (E-TTS)는 synthetic voice에 emotional depth를 add 하는 것을 목표로 함
- BUT, 기존의 E-TTS model은 emotion label이나 reference speech와 같은 oversimplified reprsentation, single-modality input에 의존함
- 특히 reference audio에서 추출한 Global Style Token (GST)는 speaker characteristic을 emotional/prosodic element로부터 fully disentangle 하지 못하므로 out-of-domain data에 대해 suboptimal performance를 보임 - 한편으로 text, audio, visual information과 같은 multi-modal cue를 incorporate 하면 synthesized speech에 대한 expressiveness를 향상할 수 있음
- BUT, 기존의 E-TTS model은 emotion label이나 reference speech와 같은 oversimplified reprsentation, single-modality input에 의존함
-> 그래서 multiple modality의 emotional information을 활용하는 UMETTS를 제안
- UMETTS
- Emotion Prompt Alignment (EP-Align) module의 cue anchoring mechanism을 통해 다양한 modality에서 emotional data를 aligning 하여 multi-modal information의 seamless fusion을 지원
- 즉, contrastive learning을 기반으로 다양한 modality에 대한 emotional feature를 synchronize 하고 distribution discrepancy를 완화함 - Emotion Embedding-Induced TTS (EMI-TTS) module은 aligned emotional embedding을 통해 expressive, emotionally resonant speech를 생성
- TTS model을 aligned emotional embedding과 integrate 하여 intended emotion을 반영함
- Emotion Prompt Alignment (EP-Align) module의 cue anchoring mechanism을 통해 다양한 modality에서 emotional data를 aligning 하여 multi-modal information의 seamless fusion을 지원
< Overall of UMETTS >
- Multi-modality information을 반영하기 위해 EP-Align, EMI-TTS module을 활용하는 emotional TTS framework
- 결과적으로 기존보다 뛰어난 expressiveness를 달성
2. Method
- UMETTS framework는 vision, audio, text의 multi-modal cue를 활용하여 emotionally expressive speech를 생성하는 것을 목표로 함
- 이를 위해 논문은 Emotion Prompt Alignment Module (EP-Align)과 Emotion Embedding-Induced TTS (EMI-TTS)의 2가지 module을 활용함

- Emotion Prompt Alignment Module (EP-Align)
- EP-Align은 vision, audio, text, prompt의 multi-modality에서 emotional representation을 추출하고 align 함
- 이를 위해 multi-modal emotion data tuple $\text{Tup}^{emo}=\langle v,a,s,p\rangle$를 사용함
- $v$ : visual data, $a$ : audio input, $s$ : text input, $p$ : emotional prompt label - 각 modality는 emotion feature를 추출하는 modality-specific encoder $\mathcal{E}=\{\mathcal{E}^{vis},\mathcal{E}^{audio},\mathcal{E}^{tex},\mathcal{E}^{prop}\}$를 통해 처리됨
- 이후 해당 feature는 unified emotion embedding $u^{emo}$로 align 되고 synthesis를 위해 EMI-TTS로 전달됨
- 이를 위해 multi-modal emotion data tuple $\text{Tup}^{emo}=\langle v,a,s,p\rangle$를 사용함
- Multi-modal Feature Extraction
- 각 encoder는 raw input을 shared internal feature space로 transforming 하여 input modality를 process 함
- 각 modality $\mu\in\{vis,audio,tex,prop\}$에 대해, extracted feature representation $f^{\mu}$는 $f^{\mu}=\mathcal{E}(x^{\mu})$와 같이 얻어짐
- $x^{\mu}$ : modality $\mu$에 대한 input data - Shared embedding space는 learnable projection matrix를 사용하여 $u^{\mu}=f^{\mu}\cdot W^{\mu\text{-}pro}$과 같이 얻어짐
- Prompt Anchoring and Alignment
- 논문은 modality 간 consistency를 보장하기 위해 prompt-anchoring scheme을 사용하여 서로 다른 modality의 emotion feature를 align 함
- Prompt embedding $u^{prop}$은 alignment modality $\eta$에 따라 select 되고 $u^{prop}=f^{prop}\cdot W^{prop\text{-}\eta},\,\,\eta\in\{vis,audio,tex\}$와 같이 calculate 됨
- Alignment는 prompt의 explicit emotion embedding $u^{exp}$와 vision/audio/text의 implicit emotion embedding $u^{imp}$ 간의 cosine similarity를 통해 further refine 될 수 있음:
- 즉, $\text{logits}=e^{t}\cdot\left(\sigma(u^{exp}\cdot \sigma(u^{imp})^{\top})\right)$
- $t$ : learned temperature parameter, $\sigma(\cdot)$ : embedding에 대한 normalization function
- Prompt embedding $u^{prop}$은 alignment modality $\eta$에 따라 select 되고 $u^{prop}=f^{prop}\cdot W^{prop\text{-}\eta},\,\,\eta\in\{vis,audio,tex\}$와 같이 calculate 됨
- 결과적으로 alignment loss는 symmetric cross-entropy를 통해 compute 됨:
(Eq. 1) $\mathcal{L}_{align}=-\log \frac{e^{\text{logits}}}{\sum^{K}e^{\text{logits}}}-\log \frac{e^{\text{logits}^{\top}}}{\sum e^{\text{logits}^{\top}}} $
- $K$ : batch의 total sample 수 - Inference 시에는 implicit embedding에 대해 highest similairty를 가지는 emotion embedding을 select 하여 final aligned emotion representation $u^{emo}$로 사용함
- 논문은 modality 간 consistency를 보장하기 위해 prompt-anchoring scheme을 사용하여 서로 다른 modality의 emotion feature를 align 함

- Emotion Embedding-Induced TTS (EMI-TTS)
- EMI-TTS module은 emotionally expressive speech를 생성하기 위해, model library $\mathcal{M}$의 pre-trained TTS model을 사용하여 aligned emotion embedding $e^{\mu}$와 input text $\text{Tex}$를 integrate 함
- 이때 EMI-TTS는 VITS, FastSpeech2, Tacotron2와 같은 TTS model을 지원함 - Speech Synthesis Workflow
- 먼저 input text $\text{Tex}$를 text encoder를 사용하여 linguistic feature sequence $h_{lg}$로 encoding 함:
- $h_{lg}=\text{TextEncoder}(\text{Tex})$ - 이후 linguistic feature는 emotion embedding $u^{emo}$와 speaker embedding $u^{spk}$와 concatenate 되어 augmented representation을 구성함:
- $h_{lg}^{emo}=\text{Concat}(h_{lg},u^{emo},u^{spk})$ - Augmented feature는 acoustic model로 전달되어 acoustic feature $h_{ac}$를 생성함
- 최종적으로 vocoder는 해당 acoustic feature를 final speech waveform으로 변환함:
- $\text{Audio}^{emo}=\text{Vocoder}(h_{ac})$
- 먼저 input text $\text{Tex}$를 text encoder를 사용하여 linguistic feature sequence $h_{lg}$로 encoding 함:
- Model Variants
- EMI-TTS framework는 여러 TTS model variant를 지원함
- VITS Variant
- VITS variant는 variational inference와 normalizing flow를 기반으로 emotion embedding $u^{emo}$를 incorporate 함
- 해당 embedding은 Emotion-condition Flow 내의 Spectrogram Encoder와 Emotional WaveNet (EWN)에 도입됨 - 그러면 affine transformation operator $\text{AX}()$는 다음과 같이 emotion conditioning을 수행함:
(Eq. 2) $h_{0},h_{1}=h;\,\,h_{1}^{'}=\text{AX}(\text{EWN}(h_{0}+u^{emo}),h_{1})$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, h'=\text{Connection}(h'_{1},h_{0})$
- $h_{0}, h_{1}$ : hidden state, $h'_{1}$ : emotion conditioning 이후의 updated hidden state
- VITS variant는 variational inference와 normalizing flow를 기반으로 emotion embedding $u^{emo}$를 incorporate 함
- FastSpeech2 Variant
- FastSpeech2 variant에서 emotion embedding은 speaker, emotion information을 unified conditioning feature $c$로 merge 하는 Conditional Cross Attention mechanism에 incorporate 됨
- 이때 attention mechanism은 Query $Q$, Key $K$, Value $V$에 대해 $Q=W_{q}\cdot h,\,\,K=W_{k}\cdot c, \,\,V=W_{v}\cdot c$와 같이 formulate 됨
- $W_{q},W_{k},W_{v}$ : learnable projection matrix - 그러면 attention-weighted output은:
(Eq. 3) $h^{emo}=\text{softmax}\left(\frac{Q\cdot K^{\top}}{\sqrt{d}}\right)\cdot V+h$
- $d$ : hidden state dimension, $h^{emo}$ : emotion-conditioned output - 결과적으로 해당 attention mechanism을 통해 Mel-spectrogram Decoder와 Duration Predictor를 adjust 하여 intended emotional tone을 반영함
- Tacotron2 Variant
- Tacotron2 variant에서 emotion embedding $u^{emo}$와 speaker embedding $u^{spk}$는 attention mechanism에 directly integrate 됨
- Character-encoded linguistic feature $h_{lg}$는 emotion, speaker embedding과 concatenate 됨:
- $h_{lg}^{emo}=\text{Concat}(h_{lg},u^{emo},u^{spk})$ - 이후 Location & Emotion Sensitive Attention module을 통해 context vector를 생성함
- 최종적으로 해당 vector는 Recurrent Neural Network (RNN)을 통해 emotional/linguistic context를 반영하는 speech를 생성하는 데 사용됨
- EMI-TTS framework는 여러 TTS model variant를 지원함
3. Experiments
- Settings
- Dataset : MELD, MEAD, ESD, RAF-DB
- Comparisons : EmoSpeech, GenerSpeech, MM-TTS
- Results
- 전체적으로 UMETTS의 합성 성능이 가장 우수함
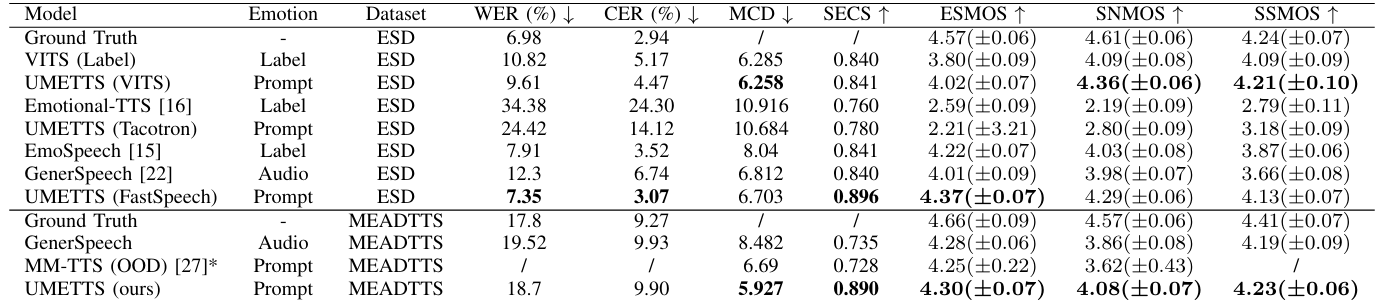
- Impact of EP-Align on Emotion Classification
- EP-Align은 basic, compound emotion을 predict 하는데 효과적임
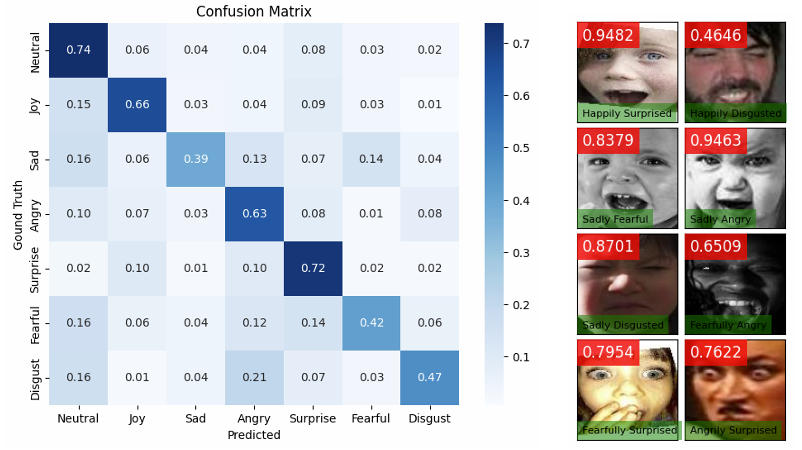
- Effect of Emotion Labels vs. Aligned Prompts on Speech Quality
- EP-Align은 multiple modality의 emotional cue를 활용하여 expressive speech를 생성할 수 있음

반응형
'Paper > TTS' 카테고리의 다른 글
댓글