

티스토리 뷰
Paper/ETC
[Paper 리뷰] Lightweight Convolutional Neural Network Architecture Design for Music Genre Classification using Evolutionary Stochastic Hyperparameter Selection
feVeRin 2023. 7. 11. 13:30반응형
Lightweight Convolutional Neural Network Architecture Design for Music Genre Classification using Evolutionary Stochastic Hyperparameter Selection
- Music Genre Classification (MGC)은 대용량 음악 콘텐츠의 정확한 indexing, 분류를 위해서 높은 계산 비용이 필요
- CNN은 MGC에 적합한 network architecture이지만 음악과 architecture에 대한 도메인 지식이 필요
- MGA-CNN
- Stochastic Hyperparameter Selection을 통한 Genetic Algorithm 기반 최적 architecture search
- MGC 작업을 위한 CNN architecture 설계 자동화
- 논문 (Expert Systems 2023) : Paper Link
1. Introduction
- 스마트폰과 같은 휴대용 장치에서 대용량 음악 콘텐츠 시스템을 구성하기 어려움
- MGC 작업을 위한 nerual architecture는 높은 컴퓨팅 자원을 필요로함
- CNN은 MGC에 효과적인 성능을 보였지만 수작업으로 최적의 architecture를 구현하는 것은 소모적인 작업임
- Neural Architecture Search를 통한 최적 architecture 자동 설계는 소모적인 비용을 줄일 수 있음
- Evolutionary Algorithm (EA)은 가장 많이 사용되는 방식 중 하나
- Genetic Algorithm (GA), Evolutionary Strategy, Genetic Programming을 포함
- Crossover, mutation, selection을 통해 최적의 솔루션을 생성할 수 있음이 밝혀짐
- Evolutionary Algorithm (EA)은 가장 많이 사용되는 방식 중 하나
-> 그래서 MGC를 위한 경량화된 CNN architecture를 생성하기 위해 Genetic Algorithm을 활용하는 MGA-CNN을 제안
- MGA-CNN
- 제한된 자원에서 MGC를 위한 최적의 경량 CNN architecture를 생성
- Selective stochastic crossover, Choice-based mutation 활용
< Overall of MGA-CNN >
- MGC를 위한 경량화된 최적 CNN architecture를 자동 생성하는 시도
- 정렬된 hyperparameter dictionary를 통해 EA에서 사용되는 architecture representation 단순화
- 최적 search space 구성 및 다양화를 위한 Selective stochastic crossover, Choice-based mutation
- 짧은 실행시간과 적은 parameter 만으로도 SOTA와 비슷한 성능을 달성
2. Proposed Approach
- Candidate model with hyperparameter settings
- (목표) Candidate model architecture represenetation에서 CNN을 사용해 MGC에 대한 최적의 모델을 찾는 것
- Candidate model 구성
- 4개의 convolution layer
- 2개의 max-pooling layer
- 1개의 fully-connected layer
- 1개의 output layer
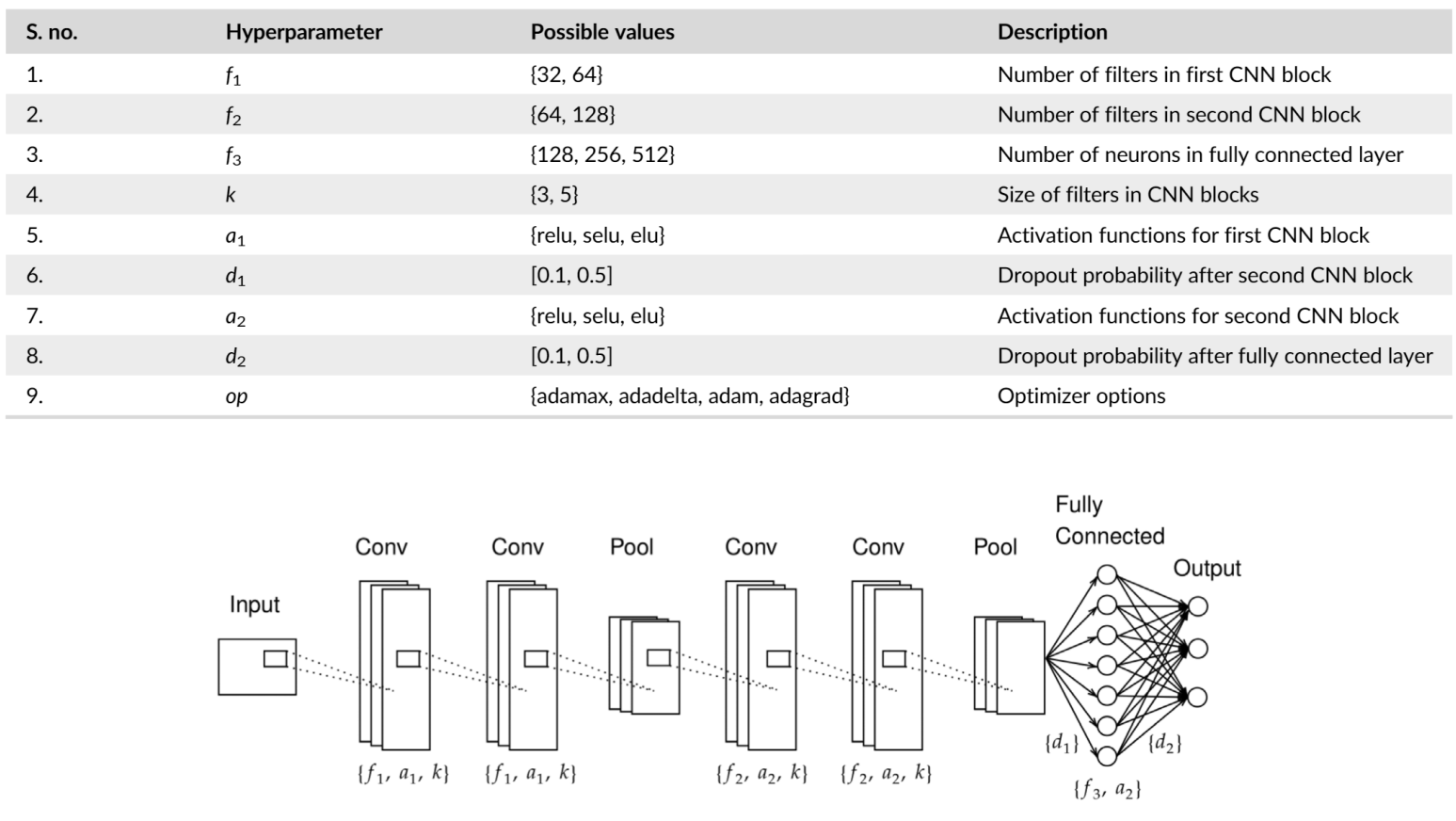
- Overview
- CNN 블록, candidate 모집단 크기, GA 반복 횟수, 음악파일에서 추출된 MFCC feature 기반
- MGA-CNN : MFCC feature를 활용해 최적의 CNN architecture를 찾아내는 GA 기반 접근법
- Evolution
1. 모집단 크기 $S_{p}$로 초기화
2. Global fitness $G_{bf}$, best global parameter $G_{bp}$에 대한 counter 0으로 초기화
- Empty ordered dictionary 이용
3. CNN architecture를 encoding 하는 각 candidate fitness는 evolution 과정에서 사용되는 dataset을 통해 평가
4. Fitness에 따라서 parents를 선택
5. Crossover, mutation, 새로운 children 생성 반복 - Selection
- 자연선택의 원리를 모방
1. 현재 모집단은 생성된 offspring과 parent로 구성
2. 허용되는 최대 generation 수를 넘을 때까지 counter 증가
3. 가변-길이 encoding 전략 활용
4. MGA-CNN에 의해 생성된 CNN architecture의 efficiency를 보장하는 방식으로 choice-based mutation 적용
- Evolution
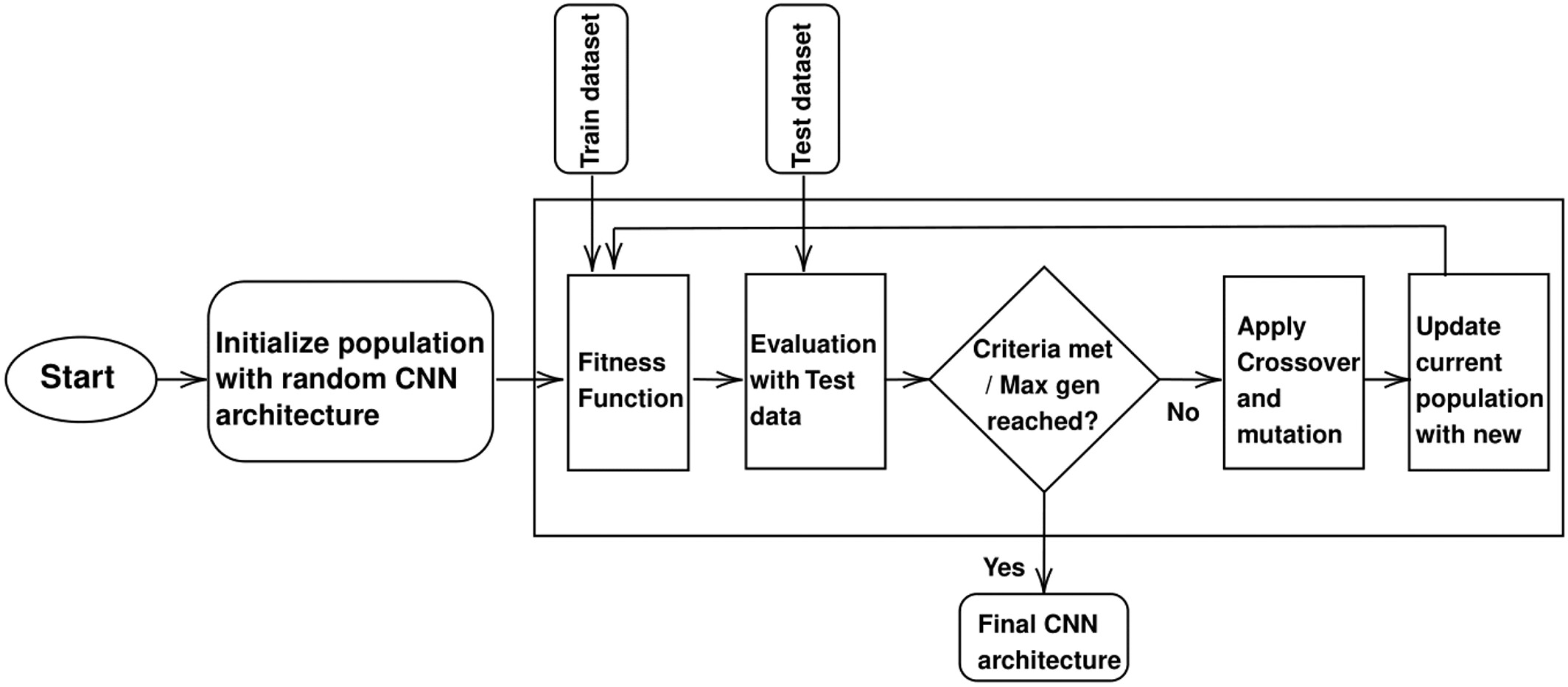

- Population initialization
- Candidate model의 CNN 블록은 convolution, pooling, fully-connected layer로 구성됨
- CNN의 성능은 filter 수와 convolution layer stack에 크게 의존 - Candiadate model의 parameter는 가능한 값을 가진 임의의 hyperparameter로 초기화됨
- 각 layer의 filter 수, activation function, dropout percentage, optimizer 등
- Hyperparameter setting 표 참고
- Candidate model의 CNN 블록은 convolution, pooling, fully-connected layer로 구성됨
- Parent Selection
- Popoulation initialization 이후 fitness score를 기반으로 각 candidate architecture를 평가
- Fitness score가 가장 좋은 두 개의 model을 선택하여 offspring generation
- 반복하면서 더 높은 fitness score를 가진 candidate로 population을 채움
- Parent model의 architecture feature가 child model로 복제됨

- Selective stochastic crossover
- Candidate model architecture의 offspring generation은 parent architecture의 crossover로 진행됨
- Child model architecture는 selective stochastic crossover를 통해 생성
1. $\{f_{1}, f_{2}, f_{3}, k \}$ : CNN filter 수, neuron 수, filter size, fully-connected layer 수
-> 두개의 parent 값들 사이에서 stochastic 하게 선택됨
2. $\{a_{1}, d_{1} \}$ : 첫 번째 CNN 블록에 대한 activation function, dropout 확률
-> hyperparameter search space를 줄이기 위해서 offspring architecture의 첫번째 CNN 블록과 pooling layer는 동일하게 유지
3. $\{a_{2}, d_{2}, op \}$ : 두 번째 CNN 블록에 대한 activation function, dropout 확률, optimizer
-> 두번째 CNN 블록은 Parent architecture들 간의 교환으로 생성 - Parent model에서의 selective swapping을 통해 hyperparameter 최적화를 위한 search space 확산을 제어할 수 있음


- Choice-based mutation
- 모집단의 다양성을 유지하고 중복성을 줄이기 위해서는 생성된 offspring candidate를 mutation 하는 것이 필요
1. 가능한 $\{f_{1}, f_{2}, d_{1}, d_{2}, op \}$ hyperparameter 중에서 choice-based stochastic assignment를 통해 offspring architecture를 mutate
2. Hyperparameter $\{f_{1}, f_{2}, f_{3} \}$는 parent architecture와의 편차를 제한하기 위해 mutation 과정에서 선택되지 않음
3. Choice-based hyperparameter를 조정한 다음, child model의 fitness score를 계산
4. Mutate 된 child architecture의 fitness가 parent보다 크면 mutate 된 architecture를 모집단에 추가
- Choice-based mutation 확률은 10%로 설정
5. Choice-based mutation 외에 모집단의 다양성을 높이기 위해 4 generation 마다 selective mutation을 적용
- Selective mutation은 100%로 설정
- 모집단의 다양성을 유지하고 중복성을 줄이기 위해서는 생성된 offspring candidate를 mutation 하는 것이 필요


- Fitness evaluation
- classification Accuracy (CA) 사용 : 정확하게 분류된 샘플과 총 샘플 수의 비율
- $CA = \frac{TP+TN}{TP+TN+FP+FN}$
- $TP$ : True-positive / $TN$ : True-Negative / $FP$ : False-Positive / $FN$ : False-Negative - 각 model 별로:
1. Model은 주어진 epoch 수만큼 dataset의 training split으로 학습됨
2. Dataset의 test split에 의해 CA가 계산되고 해당 값을 candidate CNN architecture에 대한 fitness score로 활용
3. Experiments
- Settings
- Datasets : Free Musci Archive (FMA), Indian regional music dataset (regional), Indian music genre dataset (Kaggle)
- Comparisons : GPSO-CNN, PSO-CNN, CNN-GA
- Comparison with existing approaches
- 제안된 MGA-CNN이 ResNet50에 비해 Kaggle, regional dataset에서 4.91%, 6.3%의 성능 개선을 보임
- FMA dataset에서는 ResNet50이 더 좋은 성능을 달성했지만, parameter 측면에서는 MGA-CNN은 95%나 적은 parameter를 사용함
- EfficientNet, MobileNet과 비교에서도 MGA-CNN은 83.1%, 69.64% 더 적은 parameter를 사용함
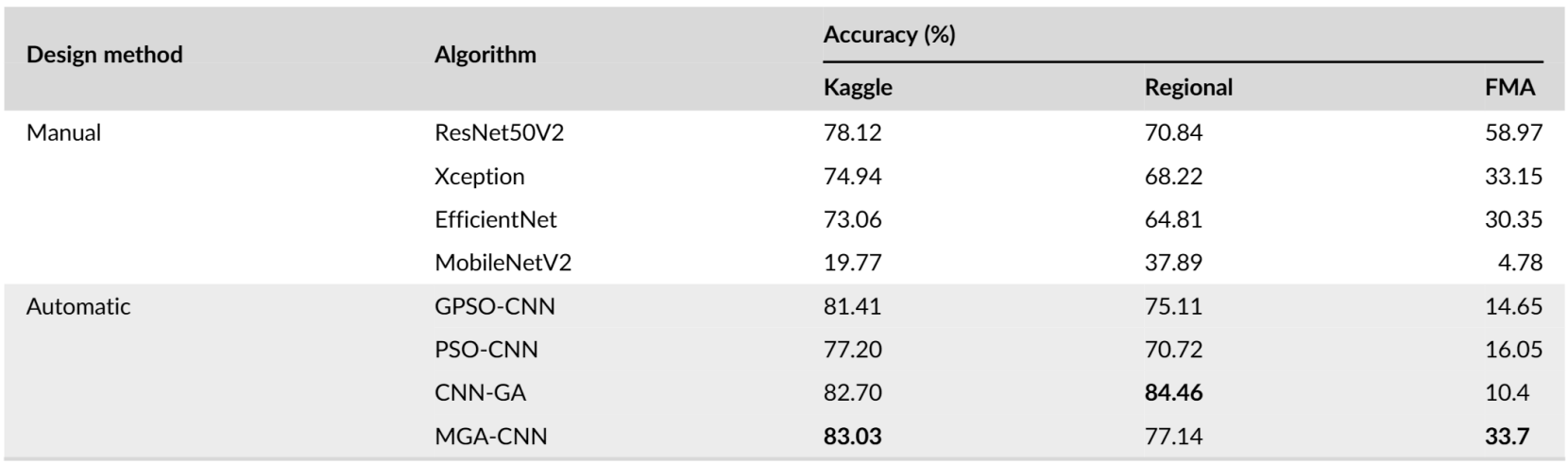
- MGA-CNN은 PSO-CNN보다 81% 더 적은 parameter를 사용하면서 모든 dataset에 대해 더 좋은 성능을 보임
- MGA-CNN이 더 적은 parameter를 사용하면서도 MGC에서 충분히 좋은 정확도를 달성할 수 있음
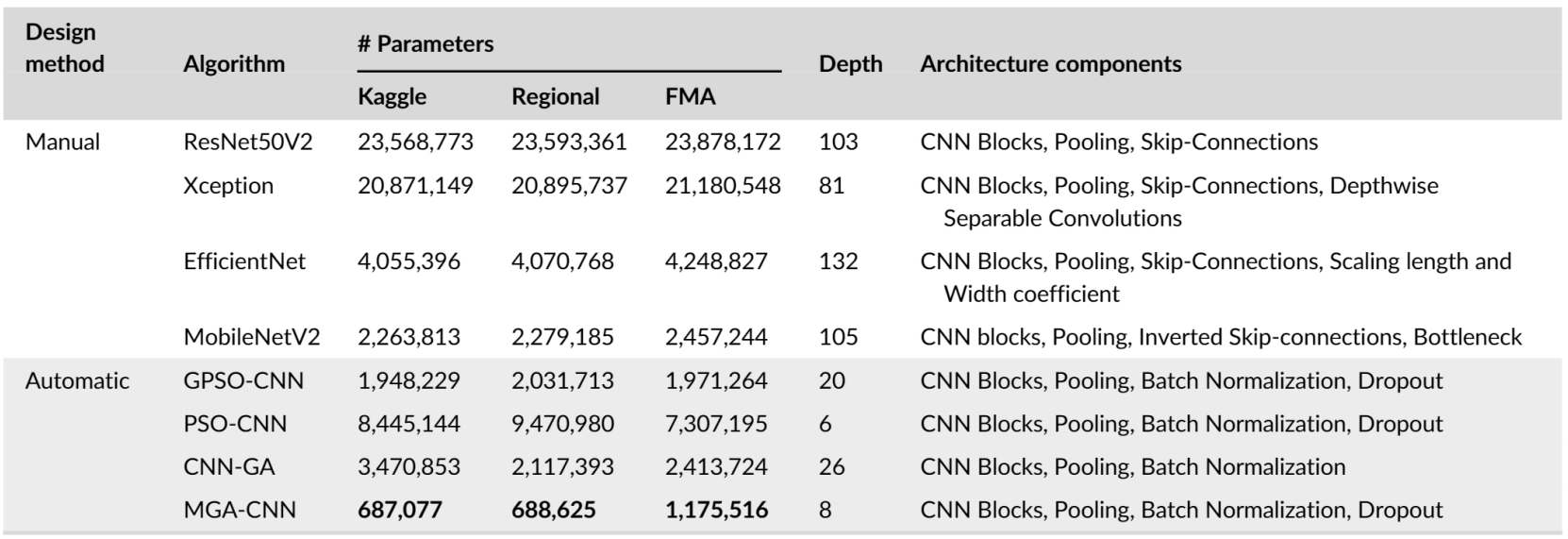
- GPU time 측면에서 MGA-CNN은 CNN-GA 보다 을 85.3% 더 적게 사용함
- PSO-CNN은 MGA-CNN 보다 학습 속도는 빠르게 측정되었지만 FMA dataset에서 좋은 성능을 보이지 못함


- Evolution trajectory of MGA-CNN
- 최고 Accuracy와 평균 CA 모두 generation이 진행됨에 따라 증가하는 경향을 보임
- 초기 generation에서 가장 성능이 좋지 않은 model이 등장하는 이유는 random initialization 때문
- 50 generation 이후부터는 성능이 크게 개선되지 않았기 때문에 algorithm이 수렴한 것으로 판단할 수 있음

- Error analysis
- Kaggle datasetdptj CNN-GA는 높은 epoch에서 약간의 overfitting을 보임
- PSO-CNN은 FMA trainset에서 높은 accuracy를 보였지만 validation set에서는 overfitting으로 인해 낮은 성능을 보임
- 제안한 MGA-CNN은 train/validation 모두에서 overfitting 없이 우수한 성능을 보임

- MGA-CNN의 confusion matrix를 봤을 때, 대부분의 장르에 대해 올바른 label 분류를 수행했음
- Semi-classic과 Sufi 장르에서 약간의 오분류를 보였는데, 이는 사람이 분류해도 비슷하게 분류하는 장르임

- Theoretical implications
- MGA-CNN의 time complexity 비교
- Population initialization : $O(P_{s})$
- $P_{s}$ : 모집단 크기 - Parent selection : $P_{s}$에 선형적으로 종속되어 있어 최악의 경우 $O(P_{s})$
- Selective stochastic crossover : 상수 시간 $O(k)$
- Choice-based mutation : $O(k)$
- Population initialization : $O(P_{s})$
- MGA-CNN의 전체 time complexity : $O(G_{max} \cdot P_{s} \cdot T_{max})$
- $G_{max}$ : 최대 반복 횟수
- $P_{s}$ : 모집단 크기
- $T_{max}$ : 가장 큰 architecture에 대한 최악 실행 시간
-> MGA-CNN에서 가장 큰 overhead 요소는 $G$이기 때문에 다른 접근 방식에 비해서 time complexity가 낮음 (lightweight!)
반응형
'Paper > ETC' 카테고리의 다른 글
댓글