
티스토리 뷰
Paper/TTS
[Paper 리뷰] VECL-TTS: Voice Identity and Emotional Style Controllable Cross-Lingual Text-to-Speech
feVeRin 2024. 7. 2. 09:48반응형
VECL-TTS: Voice Identity and Emotional Style Controllable Cross-Lingual Text-to-Speech
- Text-to-Speech는 여전히 voice identity와 emotional style 측면에서 합성의 한계가 있음
- VECL-TTS
- Source language의 reference speech에서 voice identity와 emotional style을 추출한 다음 cross-lingual technique을 사용해 target language로 transfer 함
- Multi-lingual speaker와 emotion embedding block을 도입하고 음성 품질을 향상하기 위해 content loss와 style consistency loss를 채택
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Cross-Lingual Text-to-Speech (TTS)는 original speaker의 distinctive voice identity와 emotional nuance를 유지하면서 target language에 대한 고품질 음성을 생성하는 것을 목표로 함
- 일반적으로 TTS에 제공되는 input text에는 특정한 emotional cue가 포함될 수 있지만, target speaker에 대한 style-specific nuance를 capture 하지 못하는 경우가 많음
- 따라서 TTS system은 trained style을 기준으로 음성을 생성하게 됨 - 이를 해결하기 위해서는 reference speech signal에서 voice identity style information을 추출하는 것이 필요함
- BUT, 기존 방식들은 대부분 reference signal과 target text가 동일한 language로 되어있다는 가정에 기반하고 있음
- 한편으로 YourTTS, StyleTTS2는 다양한 language의 reference signal을 활용하여 voice identity를 control 했지만, emotion 측면에서는 controllability의 한계를 보임
- 특히 VITS 기반의 YourTTS는 stochastic duration predictor를 통해 phoneme duration을 예측할 때 instability로 인해 unnatural speech가 생성되는 경향이 있음
- BUT, 기존 방식들은 대부분 reference signal과 target text가 동일한 language로 되어있다는 가정에 기반하고 있음
- 일반적으로 TTS에 제공되는 input text에는 특정한 emotional cue가 포함될 수 있지만, target speaker에 대한 style-specific nuance를 capture 하지 못하는 경우가 많음
-> 그래서 voice identity와 emotional style을 동시에 control 할 수 있는 cross-lingual TTS 모델인 VECL-TTS를 제안
- VECL-TTS
- Stochastic duration predictor에 대한 conditioning mechanism을 도입
- 즉, speaker와 emotion embedding feature를 모두 사용하여 duration이 두 style에 모두 영향을 받을 수 있도록 함 - 추가적으로 pronunciation error를 줄이기 위해, training 중에 wav2vec2-based self-supervised speech representation을 integrating 한 content loss를 적용
- Stochastic duration predictor에 대한 conditioning mechanism을 도입
< Overall of VECL-TTS >
- Multi-lingual speaker/emotion embedding extractor를 사용해 cross-lingual speaker/emotion transfer를 달성
- Stochastic duration predictor에서 stable phoneme duration을 생성하기 위해 speaker/emotion embedding을 반영
- Emotion controllability를 더욱 향상하기 위해 emotion consistency loss를 도입하고, wav2vec2-based self-supervised representation을 활용한 content loss를 통해 pronunciation error를 방지
- 결과적으로 기존 모델들보다 뛰어난 cross-lingual TTS 성능을 달성
2. Method
- VECL-TTS Model
- VECL-TTS는 아래 그림과 같이 YourTTS를 기반으로 구성됨
- 먼저 10개의 tranformer block과 196 hidden channel을 가진 transformer-based text encoder를 사용함
- 이때 multi-lingual control을 위해 각 input character embedding에 4-dimensional language embedding을 concatenate 함
- 이를 통해 모든 character에서 language information을 사용하도록 text encoder를 condition 하여 보다 stable 한 output을 보장할 수 있음 - Text module의 decoder로는 4개의 affine coupling layer를 stack 해 사용함
- 이때 각 layer는 4개의 WaveNet residual block으로 구성됨
- 이때 multi-lingual control을 위해 각 input character embedding에 4-dimensional language embedding을 concatenate 함
- Output speech waveform 생성을 위한 vocoder로써는 HiFi-GAN을 활용함
- 한편으로 linear spectrogram을 latent variable로 변환하기 위해 16개의 WaveNet residual block으로 구성된 posterior encoder를 사용하는 Variational AutoEncoder (VAE)를 채택함
- 해당 latent variable은 vocoder와 flow-based decoder에 전달되어 end-to-end 합성을 지원
- 특히 learned latent variable은 model이 mel-spectrogram 대신 own representation을 얻을 수 있게 하여, 더 나은 representation을 활용하도록 도움
- 해당 latent variable은 vocoder와 flow-based decoder에 전달되어 end-to-end 합성을 지원
- 추가적으로 VECL-TTS는 stochastic duration predictor (SDP)를 활용하여 input text에서 다양한 rhythm을 생성함
- 먼저 SDP는 dilated depth-separable convolution (DDSC) 기반의 spline flow로 구성되어 각 character의 duration을 예측하고 parallel output을 생성하는데 사용됨
- 이때 cross-lingual setting에서도 서로 다른 emotion을 가진 음성을 생성할 수 있도록 emotion embedding을 추출하는 multi-lingual emotion encoder를 도입함
- 결과적으로 해당 embedding을 통해 YourTTS encoder-decoder를 conditioning 하여 emotion speech를 생성함
- VECL-TTS에는 VAE nature로 인해 KL-divergence loss $\mathcal{L}_{KL}$이 포함됨
- 해당 loss는 desired multivariate normal distribution을 얻기 위해 Evidence Lower BOund (ELBO)를 최대화하는 것을 목표로 함
- 먼저 10개의 tranformer block과 196 hidden channel을 가진 transformer-based text encoder를 사용함

- Emotion Style Control
- 한 language에서 다른 language로 speaker와 emotion을 transfer 하는 것은 prosody pattern과 nuance의 차이로 인해 어려움이 있음
- 따라서 language-specific emotion representation을 얻기 위해 multi-lingual emotion encoder를 training 함
- 이러한 pre-trained emotion encoder를 사용함으로써 단순한 emotion ID나 one-hot encoding을 사용하는 것보다 reference audio에서 더 다양한 emotion information representation을 얻을 수 있음
- 구조적으로 multi-lingual emotion encoder는 parallel 2D CNN과 transformer encoder로 구성된 emotion recognition model을 활용함
- 해당 emotion recognition model은 language-independent representation을 학습하기 위해 multi-lingual data로 training 되고, test set에서 $91.28\%$의 F1-score를 보임
- 결과적으로 emotion encoder에서 얻어진 embedding은 emotion characteristic을 나타내고, emotional audio를 생성하기 위해 encoder/decoder/duration predictor를 condition 하는 데 사용됨
- 추가적으로 VECL-TTS는 생성된 audio에서 targeted emotion을 preserve 하기 위해 Emotion Consistency Loss (ECL)을 도입함 - 여기서 ECL은 ground-truth와 생성된 audio에 대한 emotion embedding 간의 cosine similarity로 얻어짐:
(Eq. 1) $\mathcal{L}_{ECL}=\frac{-\alpha_{e}}{n}\sum_{i}^{n}\text{cos\_sim}(\phi_{e}(\text{gen}_{i}), \phi_{e}(\text{gt}_{i}))$
- $\phi_{e}(\text{gen}), \phi_{e}(\text{gt})$ : 생성된 audio와 ground-truth에 대한 emotion embedding을 얻는 function
- $\alpha_{e}$ : final loss에 대한 tuning parameter
- $\text{cos_sim}$ : cosine similarity function
- 따라서 language-specific emotion representation을 얻기 위해 multi-lingual emotion encoder를 training 함
- Speaker Identity Control
- Speaker characteristic을 다른 language로 transfer 하기 위해, speaker encoder에서 얻은 speaker embedding을 사용하여 TTS model을 conditioning 함
- 이때 speaker encoder로써 H/ASP model을 채택하고 final loss에 Speaker Consistency Loss (SCL)을 도입함
- SCL은 ground-truth에서 추출된 embedding과 생성된 audio 간의 cosine similarity로 얻어짐:
(Eq. 2) $\mathcal{L}_{SCL}=\frac{-\alpha_{s}}{n}\sum_{i}^{n} \text{cos_sim}(\phi_{s}(\text{gen}_{i}),\phi_{s}(\text{gt}_{i}))$ - 추가적으로 ECL, SCL에 외에 Mean Squared Error $\mathcal{L}_{MSE}$와 $\mathcal{L}_{KL}$을 포함한 content loss $\mathcal{L}_{content}$를 final loss에 추가함
- Content loss는 ground-truth에서 얻은 wav2vec2 embedding과 생성된 audio 간의 loss로 얻어짐
- SCL은 ground-truth에서 추출된 embedding과 생성된 audio 간의 cosine similarity로 얻어짐:
- 결과적으로 VECL-TTS의 final loss는:
(Eq. 3) $\mathcal{L}_{final}=\mathcal{L}_{ECL}+\mathcal{L}_{SCL}+\mathcal{L}_{content}+\mathcal{L}_{MSE}+ \mathcal{L}_{KL}$
- 이때 speaker encoder로써 H/ASP model을 채택하고 final loss에 Speaker Consistency Loss (SCL)을 도입함
3. Experiments
- Settings
- Dataset : VCTK, LIMMITS
- Comparisons : YourTTS, M3-TTS, METTS, CET
- Results
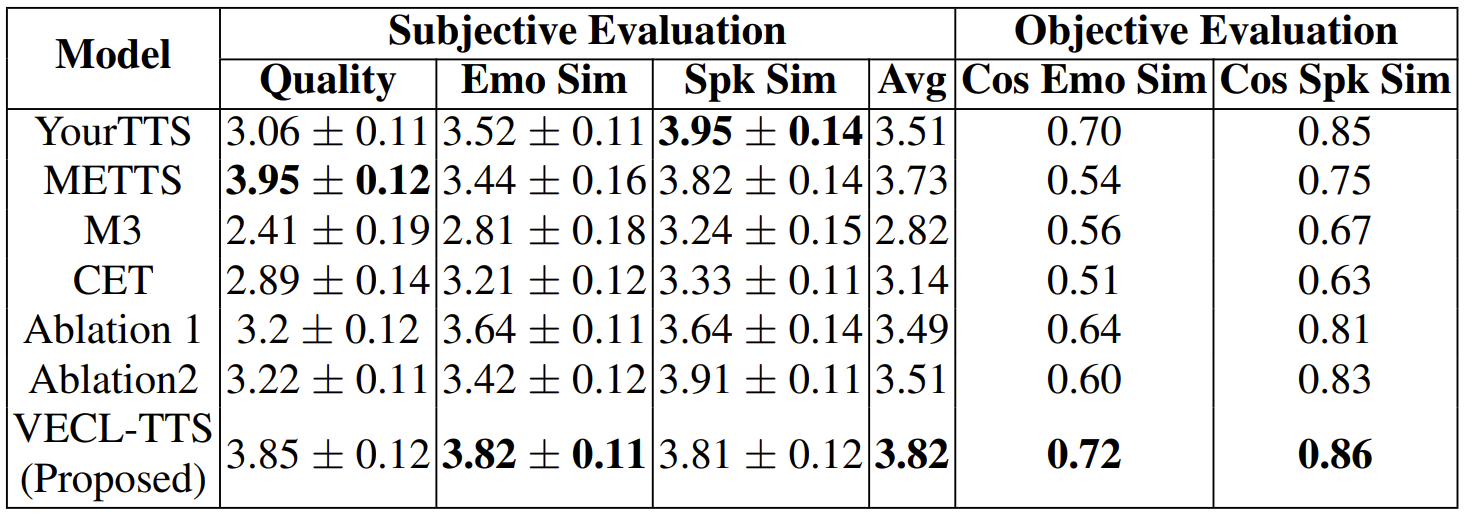
- Subjective/Objective Evaluation
- VECL-TTS는 MOS와 speaker similarity 모두에서 가장 우수한 성능을 달성함
- Ablation study 측면에서 ECL을 제거한 Ablation 1과 content loss를 제거한 Ablation 2를 비교해 보면, 기존 VECL-TTS 보다 성능이 저하됨
- Visual Analysis of VECL Model
- Mel-spectrogram 측면에서 합성된 결과를 비교해 보면
- 특정 emotion에 대해 VECL-TTS는 reference audio와 유사한 pitch variation을 따름
- 즉, VECL-TTS는 다양한 variation을 capture 할 수 있고, 기존 모델들보다 expressive 함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글