

 [Paper 리뷰] Lightweight Zero-Shot Text-to-Speech with Mixture of Adapters
[Paper 리뷰] Lightweight Zero-Shot Text-to-Speech with Mixture of Adapters
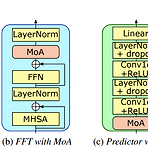
Lightweight Zero-Shot Text-to-Speech with Mixture of AdaptersLarge-scale model을 기반으로 한 zero-shot text-to-speech는 speaker characteristic reproducing에서 우수한 성능을 보이고 있지만, 실제로 활용하기에는 너무 큼Zero-Shot TTS with MoAMixture of Adapters (MoA) module을 non-autoregressive TTS 모델의 decoder와 variance adaptor에 결합Speaker embedding을 기반으로 speaker characteristics와 관련된 적절한 adapter를 선택하여 adatation ability를 향상논문 (INTERSPE..
 [Paper 리뷰] FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech Synthesis
[Paper 리뷰] FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech Synthesis
FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech SynthesisFast, Lightweight Text-to-Speech 모델에 대한 요구사항이 커지고 있음FLY-TTSDecoder를 Fourier spectral coefficient를 생성하는 ConvNeXt block으로 대체하고, inverse STFT를 적용하여 waveform을 합성Model size를 compress 하기 위해 text encoder와 flow-based model에 grouped parameter-sharing을 도입추가적으로 합성 품질 향상을 위해 large pre-trained WavLM을 통해 adversarial training 함논문 (I..
 [Paper 리뷰] MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
[Paper 리뷰] MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
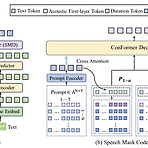
MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-SpeechZero-shot Text-to-Speech는 few-second unseen speaker voice prompt로 강력한 voice cloning capability를 달성할 수 있음BUT, 대부분의 기존 방식들은 우수한 합성 품질에 비해 추론 속도, model size 측면의 한계가 있음MobileSpeechDiscrete codec를 기반으로 speech codec의 hierarchical information과 weight mechanism을 incorporate 하는 Speech Mask Decoder module을 도입- 특히 text와 spe..
 [Paper 리뷰] DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning
[Paper 리뷰] DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning
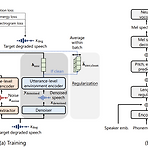
DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning대부분의 text-to-speech system은 well-designed 환경에서 수집된 고품질 corpus를 활용하므로 데이터 수집 비용이 높음DRSpeechNoisy speech corpora를 training data로 활용할 수 있는 noise-robust text-to-speech 모델Frame-level encoder를 통해 time-variant additive noise를 represent 하고 utterance-level encoder를 사용하여 time-invarian..
 [Paper 리뷰] VECL-TTS: Voice Identity and Emotional Style Controllable Cross-Lingual Text-to-Speech
[Paper 리뷰] VECL-TTS: Voice Identity and Emotional Style Controllable Cross-Lingual Text-to-Speech
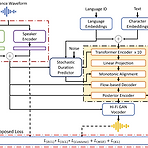
VECL-TTS: Voice Identity and Emotional Style Controllable Cross-Lingual Text-to-SpeechText-to-Speech는 여전히 voice identity와 emotional style 측면에서 합성의 한계가 있음VECL-TTSSource language의 reference speech에서 voice identity와 emotional style을 추출한 다음 cross-lingual technique을 사용해 target language로 transfer 함Multi-lingual speaker와 emotion embedding block을 도입하고 음성 품질을 향상하기 위해 content loss와 style consistency loss를..
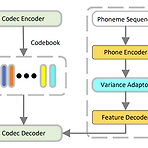 [Paper 리뷰] DelightfulTTS2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
[Paper 리뷰] DelightfulTTS2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
DelightfulTTS2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders일반적으로 text-to-speech는 mel-spectrogram을 intermediate representation으로 사용하는 cascaded pipeline을 활용함BUT, acoustic model과 vocoder는 개별적으로 training 되고, pre-designed mel-spectrogram은 sub-optimal 하다는 한계가 있음DelightfulTTS2Automatically learned speech representation과 joint optimization을 활용한 end-to-end text-to-speech 모..