

 [Paper 리뷰] NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTS
[Paper 리뷰] NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTS
NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTSExpressive text-to-speech는 다음의 어려움이 존재함- Reference audio에 background noise가 포함된 경우 highly dynamic prosody information을 추출하기 어려움- Unseen speaking style에 대한 generalization이 가능해야 함NoreSpeechKnowledge distillation을 통해 teacher model에서 noise-agnostic speaking style을 학습하는 diffusion model에 기반한 DiffStyle m..
 [Paper 리뷰] GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
[Paper 리뷰] GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-SpeechCross-lingual text-to-speech는 다음의 어려움이 있음- Timbre, pronunciation은 서로 correlate 되어 있음- Speech style에는 language-agnostic, language-specific part가 포함되어 있음GenerTTSPronunciation/style과 timbre를 disentangle 하기 위해 HuBERT-based information bottleneck을 도입Language-specific information을 제거하기 위해 style, ..
 [Paper 리뷰] QGAN: Low Footprint Quaternion Neural Vocoder for Speech Synthesis
[Paper 리뷰] QGAN: Low Footprint Quaternion Neural Vocoder for Speech Synthesis
QGAN: Low Footprint Quaternion Neural Vocoder for Speech SynthesisNeural vocoder는 space/time complexity 측면에서 resource-constraint가 존재함QGANQuaternion convolution과 multi-scale/period discriminator를 사용하여 structual compression을 달성Stability를 보장하기 위해 quaternion domain에서 weight-normalization을 도입논문 (INTERSPEECH 2024) : Paper Link1. IntroductionNeural vocoder는 intermediate speech representation을 translati..
 [Paper 리뷰] X-Singer: Code-Mixed Singing Voice Synthesis via Cross-Lingual Learning
[Paper 리뷰] X-Singer: Code-Mixed Singing Voice Synthesis via Cross-Lingual Learning
X-Singer: Code-Mixed Singing Voice Synthesis via Cross-Lingual LearningSinging Voice Synthesis는 여전히 musical score의 annotation에 의존적이고 code-mixed singing voice를 생성하는 데는 한계가 있음X-SingerPhoneme annotation이 없는 code-mixed lyrics로 구성된 music score를 처리하는 music score encoder를 도입- Music score encoder는 code-mixed lyrics를 encode하기 위해 language code-switching을 채택하고, phoneme annotation에 대한 의존성을 줄이기 위해 mixture al..
 [Paper 리뷰] QHM-GAN: Neural Vocoder based on Quasi-Harmonic Modeling
[Paper 리뷰] QHM-GAN: Neural Vocoder based on Quasi-Harmonic Modeling
QHM-GAN: Neural Vocoder based on Quasi-Harmonic Modeling기존 end-to-end neural vocoder는 black-box nature로 인해 speech의 intrinsic structure를 revealing 하지 못하므로 고품질 합성의 한계가 있음QHM-GANQuasi-Harmonic Model을 기반으로 network architecture를 개선Speech signal을 quasi-harmonic component로 parameterize 하여 고품질 합성을 지원하고, time consumption과 network size를 절감논문 (INTERSPEECH 2024) : Paper Link1. IntroductionVocoder는 acoustic ..
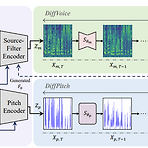 [Paper 리뷰] Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-Shot Speaker Adaptation
[Paper 리뷰] Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-Shot Speaker Adaptation
Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-Shot Speaker AdaptationVoice Conversion은 여전히 inaccurate pitch와 low speaker adaptation 문제를 가지고 있음Diff-HierVC2가지 diffusion model을 기반으로 하는 hierarchical voice conversion model- Target voice style로 F0를 효과적으로 생성할 수 있는 DiffPitch를 도입하고,- 이후 생성된 F0를 DiffVoice에 전달하여 target voice styl..