

반응형
 [Paper 리뷰] VQMIVC: Quantization and Mutual Information-based Unsupervised Speech Representation Disentanglement for One-Shot Voice Conversion
[Paper 리뷰] VQMIVC: Quantization and Mutual Information-based Unsupervised Speech Representation Disentanglement for One-Shot Voice Conversion
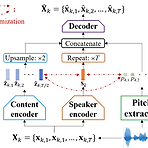
VQMIVC: Quantization and Mutual Information-based Unsupervised Speech Representation Disentanglement for One-Shot Voice ConversionOne-shot voice conversion은 speech representation disentanglement를 통해 효과적으로 수행될 수 있음- BUT, 기존 방식은 speech representation 간의 correlation을 무시하므로 content information이 leakage 될 수 있음VQMIVCContent encoding 과정에서 vector quantization을 사용하고 training 중에 correlation metric으로써 mutu..
Paper/Conversion
2024. 8. 13. 09:41
반응형