

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SAC: Neural Speech Codec with Semantic-Acoustic Dual-Stream Quantization
feVeRin 2026. 7. 1. 13:00반응형
SAC: Neural Speech Codec with Semantic-Acoustic Dual-Stream Quantization
- Speech codec은 semantically-rich representation과 high-quality reconstruction에 대한 trade-off가 존재함
- SAC
- Semantic-acoustic dual-stream quantization을 활용해 semantic, acoustic modeling을 disentangling
- 두 개의 dedicated stream을 각각의 respective role에 맞게 optimize
- 논문 (ACL 2026) : Paper Link
1. Introduction
- Speech tokenizer는 continuous speech waveform을 token sequence로 discretize 함
- 특히 EnCodec과 같은 neural audio codec을 활용하면 fine-grained acoustic detail을 capture 할 수 있음
- BUT, 해당 acoustic token은 semantic content가 부족하므로 text-based Language Model에서 weaker alignment가 발생함 - 이를 해결하기 위해 SpeechTokenizer, X-Codec 등은 semantic supervision을 incorporate 하여 semantic representation을 향상함
- BUT, semantic alignment 측면에서는 여전히 한계가 있음
- 특히 EnCodec과 같은 neural audio codec을 활용하면 fine-grained acoustic detail을 capture 할 수 있음

-> 그래서 neural codec의 semantic, acoustic modeling을 모두 개선한 SAC을 제안
- SAC
- Semantic stream, acoustic stream으로 구성된 dual-stream architecture를 도입
- 각 pathway를 통해 speech encoding을 explicitly disentangle 하여 semantic-acoustic trade-off를 해결
< Overall of SAC >
- Semantic stream, Acoustic stream을 활용한 dual-stream neural codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- SAC은 2개의 discrete encoding stream을 활용함:
- Semantic stream은 pre-trained semantic tokenizer를 사용해 linguistic content를 modeling 함
- Acoustic stream은 speech codec을 통해 semantic token이 missing 하는 acoustic information을 제공함
- Model Architecture
- SAC은 VQ-VAE framework를 기반으로 dual-stream encoder-quantizer와 unified codec decoder로 구성됨
- Semantic Stream
- 논문은 pre-trained semantic tokenizer를 채택해 semantic stream이 semantic consistency를 보장하도록 함
- 해당 semantic tokenizer는 input speech를 12.5Hz frame rate의 discrete token으로 tokenize 함
- Input waveform $x$가 주어지면 tokenizer는 50Hz에서 fine-grained continuous representation $\mathbf{S}_{c}$를 추출함
- 해당 $\mathbf{S}_{c}$는 auxiliary semantic supervision의 target으로도 사용됨 - 다음으로 temporal pooling layer는 $\mathbf{S}_{c}$를 12.5Hz의 $\mathbf{S}$로 downsampling 하고, 해당 feature는 vector quantization을 통해 quantize 되어 quantized embedding $\mathbf{S}_{q}$를 생성함
- Input waveform $x$가 주어지면 tokenizer는 50Hz에서 fine-grained continuous representation $\mathbf{S}_{c}$를 추출함
- Training 시 논문은 semantic tokenizer를 freeze 하여 semantic stream이 acoustic detail에 bias 되지 않고 linguistic content에만 exclusively focus 하도록 함
- 추가적으로 acoustic detail에 대한 temporal alignment를 위해 $\mathbf{S}_{q}$는 ConvNeXt-based adapter로 upsample 되어 semantic feature $\mathbf{S}'_{q}$를 생성함
- Acoustic Stream
- Acoustic token은 semantic token에서 missing 된 acoustic detail을 complement 하기 위해 사용됨
- 이를 위해 논문은 EnCodec architecture를 기반으로 stride $\tau$의 stacked convolutional, temporal donwsampling layer를 사용해 frame-level acoustic representation $\mathbf{A}$를 추출함
- 추가적으로 DAC를 따라 $\mathbf{A}$를 lower-dimensional embedding space로 mapping 하는 factorized code projection을 적용하고, $L_{2}$ distance 기반의 single-codebook quantization을 수행함
- 이때 codebook under-utilization을 방지하기 위해 inactive entry는 randomly sampled embedding으로 re-initialize 됨
- Acoustic representation은 low-bitrate setting에서 25Hz, high-bitrate setting에서 50Hz를 사용하고, 이때 stride $\tau$는 각각 $(2,2,4,5,8), (2,4,5,8)$로 설정됨
- Decoder
- Quantized acoustic embedding $\mathbf{A}_{q}$는 feature dimension을 따라 semantic embedding $\mathbf{S}_{q}^{'}$과 concatenate 되어 unified representation $\mathbf{U}$를 생성함
- 이후 해당 joint representation은 ConvNeXt-based pre-net으로 process 되어 fused feature sequence $\mathbf{F}$를 생성함
- Fused representation $\mathbf{F}$는 semantic stream의 linguistic information과 acoustic stream의 timbre, acoustic detail을 integrate 함 - 결과적으로 $\mathbf{F}$는 mirrored decoder를 통해 waveform $\tilde{x}$를 reconstruct 하는 데 사용되고, 이때 deconvolution stride $\tau=(8,5,4,2)$로 설정됨
- 여기서 X-Codec을 따라 key linguistic information을 preserve 하는 auxiliary semantic reconstruction objective를 도입할 수 있음
- $\mathbf{F}$는 CNN-based semantic decoder에 input 되어 reconstructed semantic feature $\tilde{\mathbf{S}}_{c}$를 predict 하고, 이때 Mean Squared Error (MSE) loss는:
(Eq. 1) $\mathcal{L}_{sem}=||\tilde{\mathbf{S}}_{c}-\mathbf{S}_{c}||_{2}^{2}$
- $\mathbf{S}_{c}$ : ground-truth semantic feature
- 여기서 X-Codec을 따라 key linguistic information을 preserve 하는 auxiliary semantic reconstruction objective를 도입할 수 있음

- Auxiliary Speaker Feature Supervision
- Timbre reconstruction을 향상하기 위해 논문은 explicit speaker feature supervision을 도입함
- 먼저 ERes2Net을 사용해 speaker embedding $\mathbf{S}_{p}$를 supervision target으로 extract 함
- 이후 prediction을 위해 fused representation $\mathbf{F}$의 temporal mean/variance를 compute 하고 global feature $\mathbf{f}$로 concatenate 함
- 해당 vector는 2-layer MLP projector를 통해 predicted speaker embedding $\tilde{\mathbf{S}}_{p}$를 생성함 - 최종적으로 $\tilde{\mathbf{S}}_{p}, \mathbf{S}_{p}$ 간에 MSE loss를 적용하여 timbre information을 modeling 함:
(Eq. 2) $ \mathbf{f}=[\text{Mean}_{t}(\mathbf{F});\text{Std}_{t}(\mathbf{F})]$
(Eq. 3) $ \mathcal{L}_{spk}=\left|\left| \tilde{\mathbf{S}}_{p}-\mathbf{S}_{p}\right|\right|_{2}^{2} =\left|\left| \text{Proj}(\mathbf{f})-\mathbf{S}_{p}\right|\right|_{2}^{2}$
- Training Objective
- SAC은 VQ-GAN framework 하에서 optimize 됨
- Reconstruction Loss
- Reconstruction loss $\mathcal{L}_{recon}$은 DAC를 따라 multiple scale의 reconstructed, ground-truth audio에 대한 $L_{1}$ distance로 얻어짐 - VQ Loss
- Acoustic stream에서 codebook은 encoder output과 quantized embedding 간의 $L_{2}$ distance를 minimize 하도록 optimize 되고, gradient는 Straight-Through Estimator (STE)를 통해 propagate 됨
- VQ loss $\mathcal{L}_{vq}$는 commitment term을 포함함
- Discriminative Loss
- 논문은 Multi-Period Discriminator (MPD), Multi-Scale STFT-based Discriminator (MS-STFT)를 사용함
- Discriminator는 least-squares GAN objective로 optimize 되고, generator는 adversarial loss $\mathcal{L}_{adv}$와 feature matching loss $\mathcal{L}_{feat}$를 사용함
- 결과적으로 overall generator loss는:
(Eq. 4) $\mathcal{L}_{G}=\lambda_{recon}\mathcal{L}_{recon}+\lambda_{vq}\mathcal{L}_{vq}+\lambda_{adv}\mathcal{L}_{adv}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{sem}\mathcal{L}_{sem}+\lambda_{spk}\mathcal{L}_{spk}$
- $\lambda$ : hyperparameter
- Reconstruction Loss
3. Experiments
- Settings
- Dataset : Emilia, WenetSpeech4TTS, LibriSpeech, LibriHeavy, MLS
- Comparisons : DAC, EnCodec, SpeechTokenizer, SemantiCodec, X-Codec, WavTokenizer 등
- Results
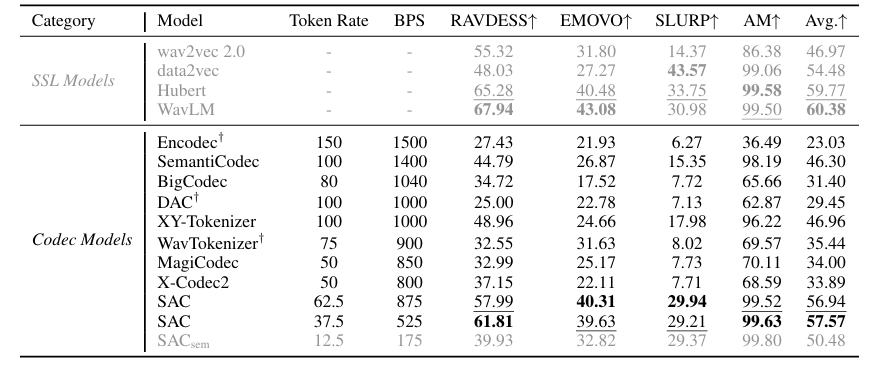
- 전체적으로 SAC은 우수한 성능을 보임

- Low-bitrate에서도 뛰어난 성능을 달성함

- Semantic representation 측면에서도 SAC이 가장 뛰어남
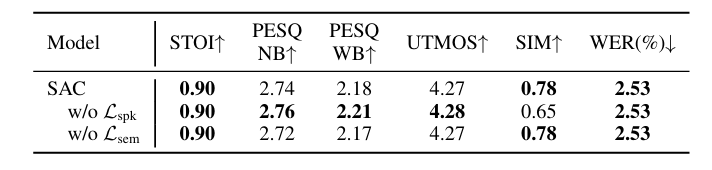
- Ablation Study
- Auxiliary feature supervision은 성능 향상에 유효함
- Speech Decoupling
- SAC은 효과적인 information disentanglement이 가능함

- 실제로 semantic-only, acoustic-only reconstruction은 full reconstruction에 비해 detail을 반영하지 못함

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글