

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FlexiCodec: A Dynamic Neural Audio Codec for Low Frame Rates
feVeRin 2026. 4. 8. 12:54반응형
FlexiCodec: A Dynamic Neural Audio Codec for Low Frame Rates
- 기존 neural audio codec은 low frame rate에서 semantic information loss가 발생함
- FlexiCodec
- Dynamic frame rate를 사용해 semantic preservation을 향상
- ASR feature-assisted dual stream encoding과 Transformer bottelneck을 도입
- 논문 (ICLR 2026) : Paper Link
1. Introduction
- Neural audio codec은 raw speech를 compact discrete token으로 compress 함
- 특히 대부분의 neural audio codec은 encoder-quantizer-decoder architecture를 따름
- Encoder는 audio waveform을 fixed-rate continuous latent vector sequence로 downsampling 하고, 해당 vector는 Residual Vector Quantization (RVQ)를 통해 discrete index로 quantize 됨
- First RVQ layer token (RVQ-1)은 autoregressive language model에 주로 활용되고 remaining RVQ layer token (RVQ-rest)는 acoustic detail을 add 하는 데 사용됨
- BUT, 기존 neural codec은 high-temporal resolution에서 attention으로 인한 quadratic complexity burden, text-audio modality 간의 frame rate mismatch로 인한 성능 저하가 발생할 수 있음
- 이를 위해 low-frame-rate codec을 구성할 수 있지만, 여전히 semantic/phonetic content loss의 문제가 존재함
- 특히 대부분의 neural audio codec은 encoder-quantizer-decoder architecture를 따름
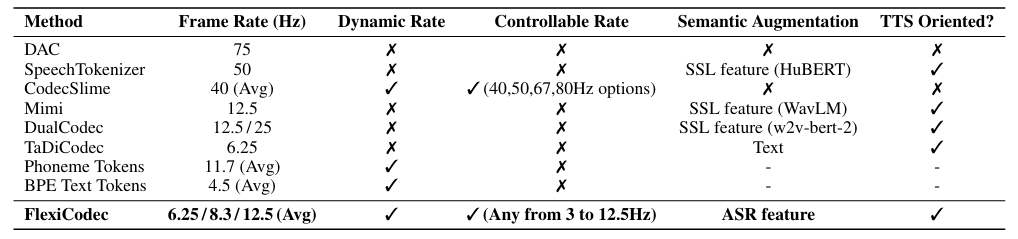
-> 그래서 low frame rate에서도 information을 효과적으로 preserve 할 수 있는 FlexiCodec을 제안
- FlexiCodec
- Dynamic frame rate를 도입해 phonetic complexity에 adapt 하는 detail을 encode
- Text prediction을 위한 Automatic Speech Recognition (ASR) feature를 활용하여 semantic information에 대한 concentrated source를 제공
< Overall of FlexiCodec >
- Dynamic frame rate allocation을 활용한 low-frame-rate neural codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- FlexiCodec은 very low average frame rate에서 semantic information을 preserve 하는 것을 목표로 함
- 이를 위해 dynamic frame rate를 활용하여 information-dense region에는 더 많은 temporal resolution을 allocate 하고 silence와 같은 information-sparse segment에는 더 적은 resolution을 allocate 함
- 구조적으로는 pre-trained ASR feature를 통해 semantic-rich RVQ-1 token을 encode 하고 adaptive frame merging process를 guide 함
- Dual-Stream Feature Extraction
- 먼저 논문은 16kHz waveform을 2개의 parallel encoder를 통해 semantic, acoustic information으로 decouple 함
- Pre-trained ASR model 기반의 ASR encoder는 frame 수 $T$, vector dimension $d$에 대해 semantic feature sequence $e_{s}\in\mathbb{R}^{T\times d}$를 추출함
- Convolutional codec encoder는 waveform을 downsampling 하여 12.5Hz의 waveform feature sequence $e_{a}\in\mathbb{R}^{T\times d}$를 생성함
- Codec encoder는 audio를 gradually downsample 하기 위해 $[4,4,5,8,2]$ stride를 가진 5개의 CNN block으로 구성되고, 각 CNN block은 ResNet과 strided 1D convolution으로 구성됨 - ASR model의 경우 encoder-only Transformer model인 SenseVoice-small을 사용함
- 이때 논문은 last layer의 hidden state를 semantic feature로 사용하고, 해당 16.67Hz output feature에 대해 linear interpolation을 적용하여 12.5Hz로 downsampling 함
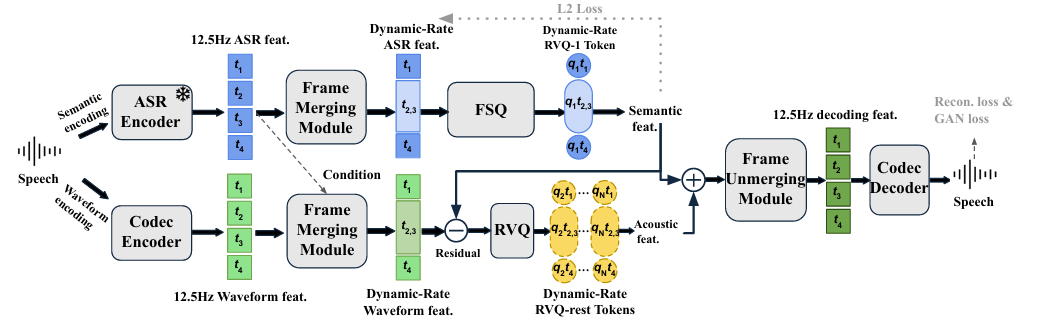
- Dynamic Frame Merging
- Dynamic frame merging module은 sequence 내의 frame 수를 compress 하여 일부 segment의 frame rate가 12.5Hz 보다 낮은 sequence를 생성함
- 논문은 semantic information loss를 최소화하면서 frame을 compress 하기 위해, semantically similar frame을 preferentially merging 하고 추출된 ASR feature를 reuse 하여 merging process를 guide 함
- 먼저 12.5Hz ASR feature vector를 $\{e_{s}[1],e_{s}[2],...,e_{s}[T]\}$라고 하자
- $t=1,...,T-1$에 대해 adjacent frame 간의 cosine-similarity는 $s_{t}=\cos \left(e_{s}[t],e_{s}[t+1]\right)$로 compute 됨
- 그러면 $\min_{t=i}^{j-1} s_{t}\geq\tau$와 같이 left-to-right로 scan 하여 adjacent similarity가 threshold $\tau$를 exceed 하는 maximal continguous segment $[i,i+1,...,j]$를 구성할 수 있음
- 해당 segment 내의 모든 frame은 semantic, acoustic stream에 대해 averaging 되어 single frame로 merge 됨:
(Eq. 1) $ \tilde{e}_{s}[k]=\frac{1}{\ell_{k}} \sum_{t=i}^{j}e_{s}[t],\,\,\, \tilde{e}_{a}[k]=\frac{1}{\ell_{k}}\sum_{t=i}^{j}e_{a}[t],\,\,\, \ell_{k}=j-i+1$
- $\tilde{e}_{s}[k]$ : semantic stream 내 compressed frame sequence의 $k$-th entry, $\tilde{e}_{a}[k]$ : acoustic stream 내의 sequence
- $\ell_{k}$ : original fix-frame-rate sequence를 reconstruct 하기 위해 record 된 merged frame length
- 한편 average-reduced sequence를 directly use 하면 reconstructed audio의 naturalness를 저하시킬 수 있음
- 이를 위해 논문은 original, averaged frame의 interleaved sequence를 process 하는 local windowed attention 기반의 Transformer를 채택함
- Frame Rate Flexibility
- FlexiCodec은 range에 따라 sampling 되는 flexible merging threshold $\tau$를 통해 training 되고, 추론 시에는 해당 $\tau$를 adjust 하여 frame rate control을 수행할 수 있음
- $\tau=1.0$의 경우, FlexiCodec은 12.5Hz fixed-frame-rate codec으로 동작함
- $\tau<1.0$의 경우, 새로운 sequence의 average frame rate는 12.5Hz 보다 낮음:
(Eq. 2) $\frac{\texttt{Total number of frames after merging}}{\texttt{Audio Duration in seconds}}$
- $\tau$를 낮게 설정하면 average frame rate가 감소함
- Semantic (RVQ-1) Quantization
- Dynamic-rate ASR feature는 Finite Scalar Quantizer (FSQ)를 통해 quantize 되어 discrete semantic token (RVQ-1 token)을 생성함
- FSQ는 input representation $e_{s}$를 $D$-dimensional low-rank space에 project 하고, 각 dimension은 rounding operation $\text{ROUND}$를 통해 $L$ level로 quantize 됨
- 이후 quantized low-rank vector $\bar{e}$는 original dimension $\hat{e}$로 re-project 됨:
(Eq. 3) $\bar{e}_{s}=\text{ROUND}\left(\text{Proj}_{down}(e_{s})\right),\,\,\,\hat{e}_{s}=\text{Proj}_{up}(\bar{e}_{s})$
- 이때 $\text{ROUND}$ function의 gradient를 estimate 하기 위해 straight-through estimation을 적용함 - Semantic token index $q_{s}$는 $q_{s}=\sum_{j=0}^{D-1}\bar{e}_{s}L^{j}$와 같이 얻어짐
- 추가적으로 FSQ block의 representation ability를 향상하기 위해 ConvNeXt block으로 wrap 하고 semantic token embedding과 unquantized semantic feature를 align 하기 위해 $L2$ loss $\mathcal{L}_{feat}$를 도입함
- Acoustic (RVQ-rest) Quantization
- Semantic token에 capture 되지 않는 detailed acoustic information을 encode 하기 위해, DualCodec을 따라 dynamic-rate waveform feautre에서 dynamic-rate ASR feature를 subtract 한 residual을 compute 함
- 해당 residual은 $(N-1)$-layer RVQ를 통해 quantize 되어 frame merging 이후의 sequence length $\hat{T}$에 대한 acoustic token $q_{2:N}\in\mathbb{Z}^{(N-1)\times \hat{T}}$를 생성함
- 추가적으로 논문은 training 시 quantizer dropout을 적용함
- 즉, RVQ-1에서 RVQ-$n$ layer만 subsequently decode 되고 $n\in[1,N]$은 randomly choice 됨
- $n=1$인 경우, semantic encoding stream 만 사용함
- Straight-through estimation은 codebook lookup을 통해 backpropagate 하기 위해 사용됨

- Frame Unmerging and Reconstruction
- Audio reconstruction을 위해 decoder path는 dynamic compression을 reverse 함
- 먼저 first $n$ chosen RVQ token의 embedding feature는 add 되어 decoding representation을 생성하고, 해당 dynamic-rate sequence는 frame unmerging module로 전달됨
- 이후 frame unmerging module은 frame length attribute를 사용하여 sequence를 12.5Hz로 expand 하고, transition smoothing과 feature representation refine을 위한 local attention 기반의 Transformer를 적용함
- 최종적으로 feature sequence는 codec encoder를 mirror 하는 convolutional codec decoder에 전달되어 output waveform을 생성함
- 결과적으로 FlexiCodec은 다음의 loss function을 통해 end-to-end training 됨:
(Eq. 4) $\mathcal{L}=\mathcal{L}_{recon}+\lambda_{GAN}\mathcal{L}_{GAN}+\lambda_{RVQ}\mathcal{L}_{RVQ}+\lambda_{feat}\mathcal{L}_{feat}$
- $\mathcal{L}_{recon}$ : multi-scale $L1$ mel-spectrogram reconstruction loss
- $\mathcal{L}_{GAN}$ : Multi-Period Discriminator, Multi-Resolution Spectrogram Discriminator에 대한 adversarial, feature matching loss
- $\mathcal{L}_{RVQ}$ : $L1$ codebook update loss와 RVQ commitment loss
- $\mathcal{L}_{feat}$ : RVQ-1 semantic token embedding, unquantized semantic feature 간의 $L2$ feature alignment loss
- 먼저 first $n$ chosen RVQ token의 embedding feature는 add 되어 decoding representation을 생성하고, 해당 dynamic-rate sequence는 frame unmerging module로 전달됨
3. Experiments
- Settings
- Dataset : LibriLight
- Comparisons : DAC, EnCodec, SpeechTokenizer, XCodec, TaDiCodec, TAAE, SemantiCodec, DualCodec, XYTokenizer, SNAC, TS3Codec, Mimi
- Results
- 전체적으로 FlexiCodec의 성능이 가장 우수함

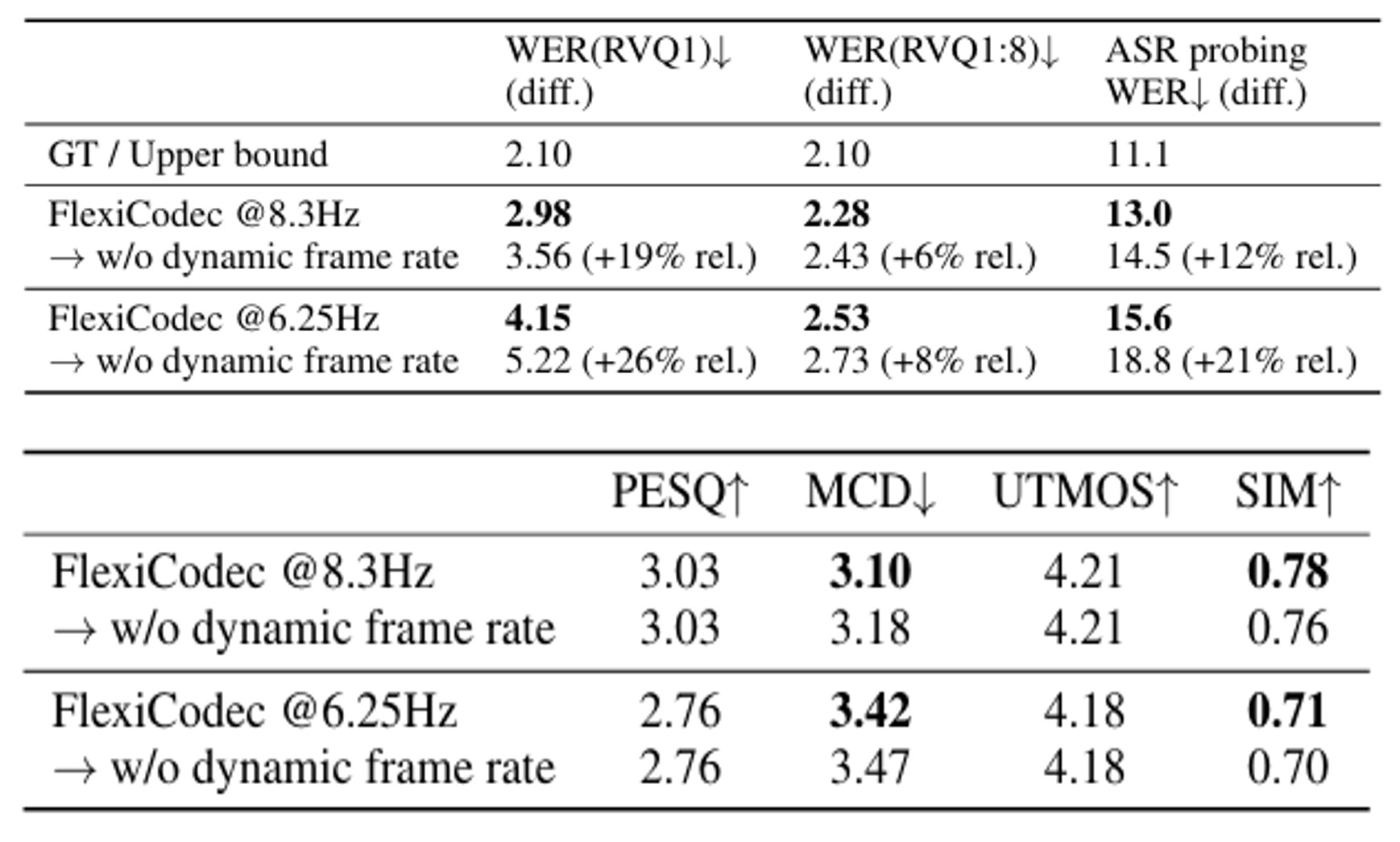
- Impact of Very Low Frame Rates
- FlexiCodec은 low frame rate에서도 semantic preservation이 가능함

- Dynamic Frame Merging
- Utterance-level phoneme rate와 FlexiCodec frame rate 간에는 strong positive correlation $r=0.775$가 존재함

- Merging threshold $\tau$는 frame rate와 semantic preservation 간의 trade-off를 control 함

- Dynamic frame rate는 semantic, acoustic quality 향상에 모두 유효함
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글