

티스토리 뷰
Paper/ASR
[Paper 리뷰] BlockDecoder: Boosting ASR Decoders with Context and Merger Modules
feVeRin 2025. 11. 10. 13:55반응형
BlockDecoder: Boosting ASR Decoders with Context and Merger Modules
- Attention-based Encoder-Decoder model에서 decoder는 Automatic Speech Recognition output을 autoregressively generate 함
- 특히 initial layer는 textual context를 build 하고 later layer는 acoustic, textual informaiton을 merge 함 - BlockDecoder
- Purely text-based text encoder와 information을 combine 하는 merger를 도입
- Encoder representation을 reuse 하고 text encoder/merger를 separate 하여 modularity를 향상
- 논문 (NeurIPS 2025) : Paper Link
1. Introduction
- Whisper와 같은 Automatic Speech Recognition (ASR) system은 attention-based encoder-decoder를 주로 활용함
- Audio encoder는 input speech를 acoustically-rich representation으로 transform 하고 decoder는 encoder의 acoustic information을 previously predicted text와 combine 하여 text를 autoregressively generate 함
- 이때 ASR decoder는 self-attention과 cross-attention module을 모두 포함한 Transformer layer로 구성됨
- Self-attention module은 주어진 time-step에서 previous token에 attend 하고 cross-attention module은 audio encoder의 speech representation에 attend 함
- 특히 decoder가 deeper 할수록 self-attention은 local context에 focus 하고, initial decoder layer에서는 cross-attention block이 less effective 함
- 즉, decoder의 initial layer는 token sequence에 extensively relying 하여 text-only context를 generate 하므로 cross-attention의 효과가 떨어짐
- 반면 final layer의 경우 initial layer의 textual context와 audio encoder의 acoustic information을 merge 하여 final prediction을 얻음

-> 그래서 해당 decoder attention pattern을 반영한 BlockDecoder를 제안
- BlockDecoder
- Self-attention 만을 사용하는 Text Encoder와 audio encoder의 acoustic representation과 text encoder의 contextualized output을 integrate 하는 Merger를 활용
- 특히 Merger는 token sequence의 각 position에서 $K$ token을 autoregressively generate
< Overall of BlockDecoder >
- Attention pattern이 반영된 Text Encoder, Merger를 활용한 ASR decoder
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overall Architecture
- BlockDecoder는 hybrid Connectionist Temporal Classification (CTC)/attention model을 기반으로 함
- 해당 framework는 shared audio encoder, autoregressive decoder, CTC decoder로 구성됨
- 먼저 input speech sequence $\mathbf{X}=[x_{1},...,x_{T'}], \,\, x_{i}\in\mathbb{R}^{d}$가 주어지면 audio encoder는 이를 contextualized speech representation $\mathbf{H}=[h_{1},...,h_{T}]$로 mapping 함
- CTC와 autoregressive decoder는 $\mathbf{H}$를 기반으로 label sequence $\mathbf{y}=[y_{1},...,y_{W}],\,\, y_{i}\in\mathcal{V}$를 생성함
- $\mathcal{V}$ : pre-defined token vocabulary - CTC branch는 $\mathbf{y},\mathbf{H}$의 all possible alignment를 marginalizing 하여 CTC loss를 minimize 하고, decoder는 $\mathbf{H}$와 previous token $y_{0},...,y_{i-1}$에 대한 $y_{i}$의 conditional likelihood를 maximize 함
- 여기서 $y_{0}$는 $\text{<sos>}$ token을 의미하고, decoder는 attention-based autoregressive module로 구성됨
- CTC와 autoregressive decoder는 $\mathbf{H}$를 기반으로 label sequence $\mathbf{y}=[y_{1},...,y_{W}],\,\, y_{i}\in\mathcal{V}$를 생성함
- 논문에서는 해당 decoder를 BlockDecoder로 replace 하는 것을 목표로 함
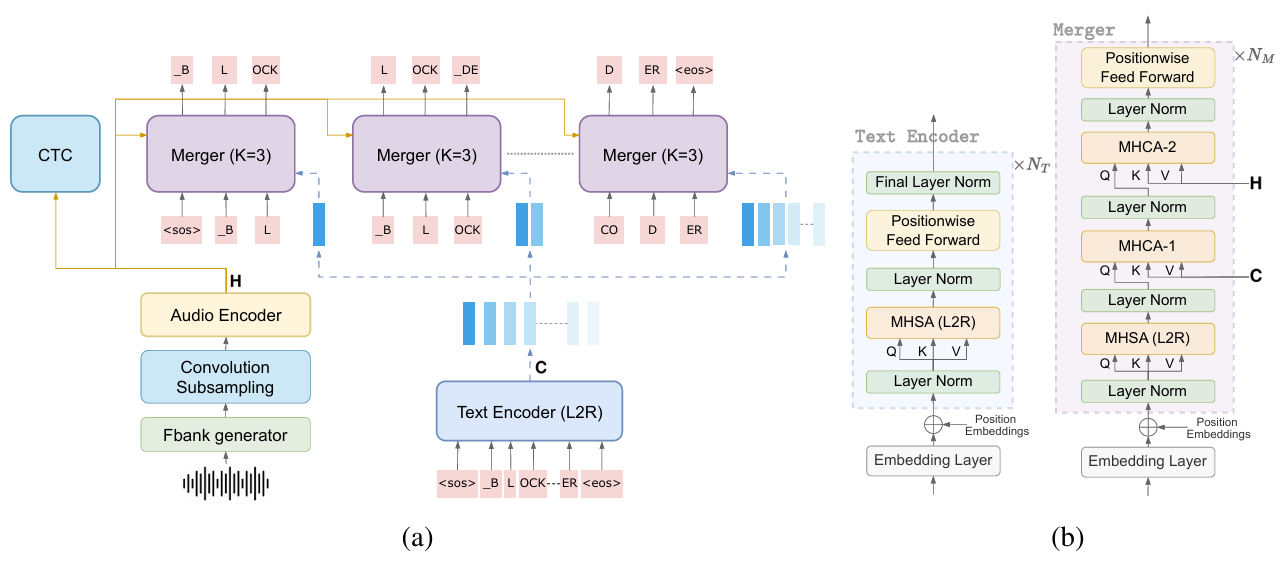
- BlockDecoder
- 논문은 standard decoder를 Text encoder와 Merger로 replace함
- Text encoder는 token sequence $\mathbf{y}$에 대한 rich textual context를 생성하고 Merger는 이를 $\mathbf{H}$와 combine 하여 block 내에서 $K$ token을 autoregressively generate 함
- Original decoder가 $N$ layer로 구성되어 있다면 BlockDecoder는 이를 text encoder, merger로 redistribute 함
- Text Encoder
- Text encoder는 information leakage를 방지하면서 token sequence $\mathbf{y}$에 대해 rich textual context를 생성하는 $N_{T}$ decoder layer stack으로 구성됨
- 구조적으로는 self-attention과 feed-forward sub-layer로만 구성되어 text에만 attend 함 - 특히 information leakage를 방지하기 위해 각 token $\mathbf{y}_{i}$는 appropriate masking을 사용하여 자신과 preceding token $\{y_{0},y_{1}, y_{2},...,y_{i-1}\}$에만 attend 함
- 이때 $j$-th text encoder layer의 output $\mathbf{C}^{j}$는:
(Eq. 1) $\hat{\mathbf{C}}=\text{MHSA}(\mathbf{C}^{j-1},\mathbf{C}^{j-1},\mathbf{C}^{j-1},\text{mask})$
(Eq. 2) $\hat{\mathbf{C}}^{j}=\mathbf{C}^{j-1}+\text{LayerNorm}_{att}(\hat{\mathbf{C}})$
(Eq. 3) $\hat{\mathbf{C}}=\hat{\mathbf{C}}^{j}+\text{LayerNorm}_{ff}(\text{Linear}(\hat{\mathbf{C}}^{j}))$
(Eq. 4) $\mathbf{C}^{j}=\text{LayerNorm}_{final}(\hat{\mathbf{C}})$
- $\hat{\mathbf{C}},\mathbf{C}^{j}\in \mathbb{R}^{W\times d}$, $\text{mask}\in \{\text{True, False}\}^{W\times W}$, $\text{MHSA}(*)$ : Multi-Head Self-Attention - Attention computation 시 $\text{mask}$는 Boolean matrix로 동작하고 $\text{mask}[a,b]$는 $a$-th token이 $\mathbf{y}$의 $b$-th token에 attend 할 수 있는지를 나타냄
- Text encoder에서는 information leakage를 방지하기 위해 $\text{mask}[a,b]=(b\leq a)$로 설정함 - Sinusoidal Positional Embedding $\text{PE}$에 대해 first layer input은 $\mathbf{C}^{0}=\text{PE}+(\text{Embedding}([y_{0},y_{1},...,y_{W}])$와 같음
- 각 text encoder layer에는 dropout이 적용되고, 각 layer end에는 $\text{LayerNorm}_{final}$이 추가됨
- 결과적으로 text encoder output은 $\mathbf{C}\in\mathbb{R}^{W\times d}$와 같음
- Text encoder는 information leakage를 방지하면서 token sequence $\mathbf{y}$에 대해 rich textual context를 생성하는 $N_{T}$ decoder layer stack으로 구성됨
- Merger
- Audio encoder로부터 audio context $\mathbf{H}$와 text encoder의 text-only context $\mathbf{C}$가 주어지면, Merger는 두 modality의 context를 jointly attend 하여 $K$ token block을 autoregressively generate 함
- 구조적으로 merger는 current block 내의 token에 causally attend 하는 self-attention block과 $\mathbf{C},\mathbf{H}$에 대한 2개의 cross-attention module을 활용함
- First cross-attention module은 current block 이전 $\mathbf{C}$의 contextualized representation에 attend 함
- Second cross-attention은 $\mathbf{H}$로부터 acoustic feature를 integrate 하여 merger가 생성하는 token이 audio에 faithful 하도록 보장함
- 결과적으로 $i$-th time step에서 merger는 previous token $y_{i-1}$과 $\mathbf{H},\mathbf{C}$에 condition 된 token sequence $\{y_{i},...,y_{i+K-1}\}$을 생성할 probability를 maximize 하도록 training 됨:
(Eq. 5) $ P\left(\{y_{i},...,y_{i+K-1}\}|y_{i-1},\mathbf{H},\mathbf{C}_{0:i-1}\right) =\prod_{k=0}^{K-1}\text{Merger}\left( \{y_{i-1},...,y_{i+k-1}\},\mathbf{H},\mathbf{C}_{0:i-1}\right)$ - Time step $i$에서 block 내의 $K$ token을 각각 생성할 때 merger는 $\mathbf{C}$의 first $i$ entry $\mathbf{C}_{0:i-1}$에 condition 되어 있음
- Merger는 각 time step에서 $K$ future token을 predict 할 수 있으므로 block 내의 token probability는 $\mathbf{C}$와 preceding token set의 multiple combination을 통해 compute 할 수 있음
- e.g.) Block size가 $3$인 경우, $y_{5}$의 probability는 $(\{y_{4}\},\mathbf{C}_{0:4}), (\{y_{3},y_{4}\},\mathbf{C}_{0:3}), (\{y_{2},y_{3},y_{4}\},\mathbf{C}_{0:2})$의 combination으로 compute 될 수 있음
- Attention, loss computation을 위해 length $|\mathbf{y}'|=K\times(W-K+1)$의 modified token sequence $\mathbf{y}'=[y_{0},y_{1},...,y_{K-1},y_{1},y_{2},...,y_{K},...,y_{W-K+1},...,y_{W}]$를 생성함
- 해당 sequence는 $K$ token으로 구성된 $(W-K+1)$ block을 포함하고, 이를 통해 attention mask를 configuring 하고 self-/cross-attention을 restrict 할 수 있음
- $\mathbf{y}'$의 length는 $K$에 따라 linearly grow 하므로 $K$에는 small value를 사용함 - 결과적으로 총 $N_{M}$ layer로 구성된 merger의 $j$-th layer $\mathbf{M}^{j}$ output은:
(Eq. 6) $ \hat{\mathbf{M}}^{j}=\text{MHSA}(\mathbf{M}^{j-1},\mathbf{M}^{j-1},\mathbf{M}^{j-1},\text{mask}_{self})$
(Eq. 7) $\hat{\mathbf{M}}=\mathbf{M}^{j-1}+\text{LayerNorm}_{self}(\hat{\mathbf{M}}^{j})$
(Eq. 8) $\hat{\mathbf{M}}^{j}=\text{MHCA}_{context}(\hat{\mathbf{M}},\mathbf{C},\mathbf{C},\text{mask}_{context})$
(Eq. 9) $\hat{\mathbf{M}}=\hat{\mathbf{M}}+\text{LayerNorm}_{context}(\hat{\mathbf{M}}^{j})$
(Eq. 10) $\hat{\mathbf{M}}^{j}=\hat{\mathbf{M}}+\text{LayerNorm}_{audio}(\text{MHCA}_{audio}(\hat{\mathbf{M}},\mathbf{H},\mathbf{H}))$
(Eq. 11) $\mathbf{M}^{j}=\hat{\mathbf{M}}+\text{LayerNorm}_{ff}(\text{Linear}(\hat{\mathbf{M}}^{j}))$
- $\hat{\mathbf{M}}^{*}, \mathbf{M}^{j}\in \mathbb{R}^{W\times d}$, $\text{MHSA}(*),\text{MHCA}(*)$ : Multi-Head Self-Attention/Cross-Attention
- $\text{mask}_{self},\text{mask}_{context}\in\{0,1\}^{W\times W}$ : Boolean matrix로써, $\text{mask}_{*}[a,b]=1$은 한 sequence의 $a$-th item이 다른 sequence의 $b$-th item을 attend 함을 의미함
- 해당 sequence는 $K$ token으로 구성된 $(W-K+1)$ block을 포함하고, 이를 통해 attention mask를 configuring 하고 self-/cross-attention을 restrict 할 수 있음
- Block 내 token에 대해 self-attention을 causally constrain 하기 위해 $\text{mask}_{self}[a,b]=(b<a)\&\left(\left\lfloor\frac{b}{K}\right\rfloor==\left\lfloor \frac{a}{K}\right\rfloor\right)$로 설정함
- $\mathbf{C}$로부터 information leakage를 방지하기 위해 $\text{mask}_{context}[a,b]=b\leq \left\lfloor \frac{a}{K}\right \rfloor$로 설정함
- 이후 각 sequence $\mathbf{y}'$의 block 내 token에 대한 embedding을 appropriate positional embedding과 함께 merger의 input으로 사용함
- 최종적으로 merger의 output probability는 simple feed-forward layer를 통해 token vocabulary size $\mathcal{V}$로 project 되고 softmax transformation을 적용하여 얻어짐
- 논문은 $\mathbf{C}$가 contextually rich 하도록 layer budge의 대부분을 text encoder에 allocate 함
- $\mathbf{H},\mathbf{C}$가 rich information을 가지면 small merger layer 만으로도 두 modality를 combine 할 수 있기 때문
- 결과적으로 cross-attention-free text encoder와 lightweight merger 간의 responsibility division을 통해 BlockDecoder는 기존 decoder 보다 더 빠르고 정확하게 동작할 수 있음
- Inference Strategy
- 추론 시에는 label-synchronous autoregressive beam search를 사용하여 best hypothesis를 find 함
- 즉, $i$-th decoding step에서 partially decoded hypothesis $\hat{\mathbf{y}}_{\leq i}$는 CTC와 BlockDecoder의 log probability에 대한 weighted combination으로 compute 됨:
(Eq. 12) $\mathcal{S}(\hat{\mathbf{y}}_{\leq i})=\delta \times \mathcal{S}_{ctc}(\hat{\mathbf{y}}_{\leq i})+(1-\delta)\times \mathcal{S}_{att}(\hat{\mathbf{y}}_{\leq i})$
- $\delta \in [0,1]$ : CTC, BlockDecoder module에서 score $\mathcal{S}_{ctc}, \mathcal{S}_{att}$의 relative importance를 결정하는 hyperparameter - $\mathcal{S}_{att}$는 text encoder, merger에 대한 다양한 input combination을 통해 compute 될 수 있음
- 이때 논문은 partially decoded hypothesis $\hat{\mathbf{y}}_{\leq i}$를 compute하기 위해 다음의 3가지 strategy를 고려함
- 즉, $i$-th decoding step에서 partially decoded hypothesis $\hat{\mathbf{y}}_{\leq i}$는 CTC와 BlockDecoder의 log probability에 대한 weighted combination으로 compute 됨:
- Strategy 1: Naive Block Decoding
- 가장 단순한 방식은 block 내의 모든 position을 활용하여 각 decoding step에서 text encoder, merger를 통해 forward pass를 수행함
- 즉, $\hat{\mathbf{y}}_{\leq i}$에 대한 attention score는:
(Eq. 13) $\mathcal{S}_{att}(\hat{\mathbf{y}}_{\leq i})=\log \left(\prod_{j=1}^{i} \text{Merger}(\{y_{j-K},..., y_{j-1}\},\mathbf{H},\mathbf{C}')\right)$
- $\mathbf{C}'=\text{TextEncoder}(\{y_{0},y_{1},...,y_{j-K}\})$ - 이는 score를 생성할 때 항상 block 내의 last position을 활용하고, text encoder와 merger를 각 decoding step 마다 forward 해야 하므로 sub-optimal 함
- Strategy 2: Iterative Block Decoding
- Merger는 $K$ token을 predict 하기 위해 blockwise로 동작하므로, Iterative Block Decoding을 고려할 수 있음
- 이때 merger는 context vector $\mathbf{C}'$을 update 하기 위해 text encoder를 통해 forward pass를 수행하기 전에 $K$ token을 continuously predict 함 - 그러면 $\hat{\mathbf{y}}_{\leq i}$에 대한 score는:
(Eq. 14) $\mathcal{S}_{att}(\hat{\mathbf{y}}_{\leq i})=\log \left(\prod_{j=1}^{i}\text{Merger}( \{y_{s},...,y_{j-1}\},\mathbf{H},\mathbf{C}')\right)$
- $\mathbf{C}'=\text{TextEncoder}(\{y_{0},y_{1},...,y_{s}\})$, $s=\left\lfloor \frac{j-1}{K}\right\rfloor \times K$ - Merger는 text encoder를 $K$ step 마다 한 번만 forward 하므로 Naive approach 보다 더 efficient 함
- Merger는 $K$ token을 predict 하기 위해 blockwise로 동작하므로, Iterative Block Decoding을 고려할 수 있음
- Strategy 3: Full Block Averaging
- Full Block Averaging은 block 내 모든 position의 score를 활용하여 성능을 향상함
- $\hat{\mathbf{y}}_{\leq i}$의 final score는 $\mathbf{C}'$과 preceding token의 모든 combination에 대한 score의 average로 얻어짐:
(Eq. 15) $\mathcal{S}_{att}(\hat{\mathbf{y}}_{\leq i})\log\left(\prod_{j=1}^{i}\frac{1}{K}\sum_{k=1}^{K} \text{Merger}(\{y_{j-k},...,y_{j-1}\},\mathbf{H},\mathbf{C}')\right)$
- $\mathbf{C}'=\text{TextEncoder}(\{y_{0},y_{1},...,y_{j-k}\})$ - 해당 방식은 merger를 $K$번 invoke 하므로 높은 성능에 비해 higher inference latency를 가짐

- Complexity of BlockDecoder
- BlockDecoder의 computaitonal complexity를 standard decoder와 비교해 보면
- 먼저 $T$를 acoustic feature $\mathbf{H}$의 length, $W$를 token sequence $\mathbf{y}$의 length, $K$를 Merger의 block size, $d$를 attention computation의 dimensionality라고 하자
- ASR task에서는 $W\ll T$ - BlockDecoder는 $N_{T}$ layer의 text encoder와 $N_{M}$ layer의 merger로 구성됨
- $N=N_{T}+N_{M}$ - Training 시 text encoder는 input으로 $\mathbf{y}$를 사용하고 merger는 modified sequence $\mathbf{y}'$를 input으로 사용함
- 이때 $|\mathbf{y}'|=(W-K+1)K\approx WK$이고, BlockDecoder의 overall attention computation은 $\mathcal{O}(N_{T}(W^{2}d)+N_{M}(WK^{2}+W^{2}K+WKT)d)$의 complexity를 가짐
- Standard decoder는 $\mathcal{O}(N(W^{2}+WT)d)$의 complexity를 가짐 - 따라서 $K\approx \frac{N}{2N_{M}}$을 choice 하는 경우 BlockDecoder는 standard decoder와 거의 동일한 attention operation을 수행함
- 이때 $|\mathbf{y}'|=(W-K+1)K\approx WK$이고, BlockDecoder의 overall attention computation은 $\mathcal{O}(N_{T}(W^{2}d)+N_{M}(WK^{2}+W^{2}K+WKT)d)$의 complexity를 가짐
- $B$ beam width를 사용한 beam-search inference 시 standard decoder는 $\mathcal{O}(WB(NW+NT)d)$의 attention computation complexity를 가짐
- BlockDeocder의 경우, Naive block decoding을 사용하면 $\mathcal{O}(WB(NW+N_{M}(K+T))d)$의 time complexity를 소모함
- BUT, $K\ll T, N_{M}\ll N$이므로 BlockDecoder는 standard decoder 보다 더 적은 attention을 수행함 - Iterative block decoding은 Naive approach와 비슷하지만 $K$ step 마다 text encoder를 한 번만 forward 하므로 더 빠른 추론 속도를 가짐
- Full block averaging의 경우 $\mathcal{O}(WB(N_{T}W+N_{M}K(K+W+T))d)$의 complexity를 가짐
- BlockDeocder의 경우, Naive block decoding을 사용하면 $\mathcal{O}(WB(NW+N_{M}(K+T))d)$의 time complexity를 소모함
- 먼저 $T$를 acoustic feature $\mathbf{H}$의 length, $W$를 token sequence $\mathbf{y}$의 length, $K$를 Merger의 block size, $d$를 attention computation의 dimensionality라고 하자
3. Experiments
- Settings
- Dataset : LibriSpeech, Tedlium2, Aishell, CommonVoice
- Comparisons : Transformer, ContextNet, Conformer, QuartzNet
- Results
- 전체적으로 BlockDecoder의 RTF가 가장 뛰어남
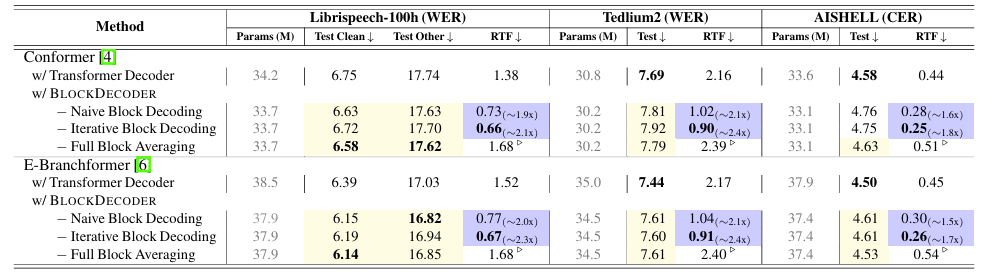
- WER 측면에서도 BlockDecoder가 가장 우수함

- Downstream Task
- SLU task에서도 우수한 성능을 달성함

- Non-English ASR에서도 우수한 성능을 보임

- Ablation Study
- Attention plot 측면에서 BlockDecoder는 accurate alignment를 보임

- Merger layer 수 $N_{M}$이 증가할수록 더 나은 WER을 얻을 수 있음

- Block Size $K$가 증가할수록 WER은 저하됨

반응형
'Paper > ASR' 카테고리의 다른 글
댓글