
반응형
 [Paper 리뷰] Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
[Paper 리뷰] Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
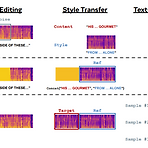
Voicebox: Text-Guided Multilingual Universal Speech Generation at ScaleLarge-scale generative model은 고품질의 output을 생성할 수 있지만, scale과 task generalization 측면에서 한계가 있음Voicebox주어진 audio context와 text를 기반으로 speech를 infill 하도록 train 된 non-autoregressive flow-matching modelIn-context learning을 통해 cross-lingual zero-shot synthesis, noise removal, content editing, style conversion 등의 다양한 task를 지원논문 (NeurI..
Paper/Language Model
2024. 7. 6. 13:20
반응형