

반응형
 [Paper 리뷰] CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-training
[Paper 리뷰] CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-training
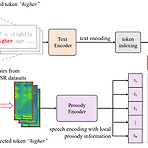
CLAPSpeech: Learning Prosody form Text Context with Contrastive Language-Audio Pre-trainingExpressive text-to-speech를 위한 masked token reconstruction은 prosody를 효과적으로 모델링하는 것이 어려움CLAPSpeech서로 다른 context에서 동일한 text token의 prosody variance를 explicitly learning 하는 cross-modal contrastive pre-training framework를 활용Encoder input과 contrastive loss를 설계하여 joint multi-modal space에서 text context와 해당 prosody..
Paper/TTS
2024. 7. 27. 12:14
반응형