

 [Paper 리뷰] Singing Voice Synthesis based on a Musical Note Position-aware Attention Mechanism
[Paper 리뷰] Singing Voice Synthesis based on a Musical Note Position-aware Attention Mechanism
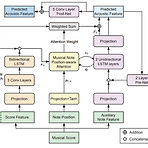
Singing Voice Synthesis based on a Musical Note Position-aware Attention Mechanism Singing Voice Synthesis를 위해 acoustic, temporal 모델링을 동시에 수행할 수 있는 sequence-to-sequence 모델을 활용할 수 있음 Musical Note Position-aware Attention Musical score가 주는 rhythm을 고려하여 attention weight를 추정 제안하는 attention mechanism을 활용하여 sequence-to-sequence 모델에서 simultaneous 모델링을 수행하고 temporal 모델링에 대한 robustness를 향상 논문 (ICASSP 202..
 [Paper 리뷰] Attention-based Neural Network for End-to-End Music Separation
[Paper 리뷰] Attention-based Neural Network for End-to-End Music Separation
Attention-based Neural Network for End-to-End Music Separation End-to-End separation은 speech separation 분야에서 우수한 성능을 보였지만 music separation에서는 아직 접목되지 않음 Sampling rate가 높은 dual channel data인 음악 신호를 모델링하기 위한 적절한 방법이 필요 Attention-based End-to-End Music Separation 멜로디, 톤과 같은 음악의 장기적인 특성을 캡처하기 위한 densely connected U-Net Separation module에 multi-head attention과 dual-path transformer를 적용 논문 (CAAI 2023)..