

 [Paper 리뷰] Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis System
[Paper 리뷰] Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis System
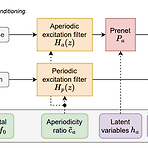
Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis SystemEnd-to-End controllable speech synthesis를 위해 Mel-cepstral synthesis filter를 활용할 수 있음Differentiable Mel-Cepstral Synthesis FilterMel-cepstral synthesis filter를 통해 voice characteristics와 pitch는 각각 frequency warping parameter와 fundamental frequency를 통해 control 될 수 있음이때 End-to-End 방식으로 최적화할 수 있도록 diffetentiab..
 [Paper 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
[Paper 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Generative Adversarial Network (GAN)을 활용한 음성 합성은 autoregressive에 비해 낮은 품질을 보임 하지만 GAN을 활용하면 sampling과 메모리 효율성을 향상할 수 있음 HiFi-GAN 다양한 period를 가지는 sinusoidal pattern을 모델링 Autoregressive 모델보다 더 빠르고 고품질의 음성을 합성 논문 (NeurIPS 2020) : Paper Link 1. Introduction 대부분의 음성 합성 모델은 two-stage 구조를 가짐 Text로 부터 mel-spectrog..