

 [Paper 리뷰] Efficient Neural Music Generation
[Paper 리뷰] Efficient Neural Music Generation
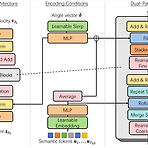
Efficient Neural Music GenerationMusicLM은 semantic, coarse acoustic, fine acoustic modeling을 통해 뛰어난 음악 생성 능력을 보여주고 있음BUT, MuiscLM은 fine-grained acoustic token을 얻기 위해 많은 계산 비용이 필요함MeLoDy고품질의 음악 생성이 가능하면서 forward pass의 효율성을 개선한 LM-guided diffusion modelSemantic modeling을 위해 MusicLM을 inherit 하고 dual-path diffusion과 audio VAE-GAN을 사용하여 conditioning semantic token을 waveform으로 decoding특히 dual-path dif..
 [Paper 리뷰] Textually Pretrained Speech Language Models
[Paper 리뷰] Textually Pretrained Speech Language Models
Textually Pretrained Speech Language Models Speech language model은 textual supervision 없이 acoustic data 만을 처리하고 생성함 Textually Warm Initialized Speech Transformer (TWIST) Pretrained textual languaga model의 warm-start를 사용하여 speech language model을 training Parameter 수와 training data 측면에서 가장 큰 speech language model을 제시 논문 (NeurIPS 2023) : Paper Link 1. Introduction 음성에는 단순한 textual context 이상의 정보가 포..
 [Paper 리뷰] AudioLM: A Language Modeling Approach to Audio Generation
[Paper 리뷰] AudioLM: A Language Modeling Approach to Audio Generation
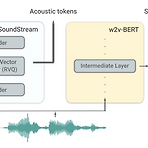
AudioLM: A Language Modeling Approach to Audio Generation 고품질 audio 생성을 위해 long-term consistency를 갖춘 language model을 활용할 수 있음 AudioLM Input audio를 discrete token sequence에 mapping 하고 해당 representation space에서 audio 생성을 language modeling으로 cast 함 Audio에 pre-train 된 masked language model의 discretized activation을 사용하여 neural audio codec의 long-term structure와 discrete code를 capture 논문 (TASLP 2023) :..
 [Paper 리뷰] MusicLM: Generating Music From Text
[Paper 리뷰] MusicLM: Generating Music From Text
MusicLM: Generating Music From Text 주어진 text description으로부터 high-fidelity의 음악을 생성하는 Language Model을 구성할 수 있음 MusicLM Conditional music generation process를 hierarchical sequence-to-sequence modeling으로 cast 추가적으로 music-text pair를 가진 MusicCaps dataset을 공개 논문 (Google Research 2023) : Paper Link 1. Introduction Conditional neural audio generation은 text-to-speech와 lyrics-conditioned music generation,..
 [Paper 리뷰] Pengi: An Audio Language Model for Audio Tasks
[Paper 리뷰] Pengi: An Audio Language Model for Audio Tasks
Pengi: An Audio Language Model for Audio Tasks Audio domain에서 사용되는 language model에는 Audio Captioning이나 Audio Question Answering과 같은 open-ended task를 처리하는 기능이 부족함 Pengi 모든 audio task를 text generation task로 framing 하고 transfer learning을 적용하는 audio language model Text encoder와 audio encoder는 continuous embedding sequence로 각각의 input을 represent 하고, 얻어진 두 sequence는 pre-trained frozen language model을 p..
 [Paper 리뷰] AudioGen: Textually Guided Audio Generation
[Paper 리뷰] AudioGen: Textually Guided Audio Generation
AudioGen: Textually Guided Audio Generation Text-to-Audio 생성에는 몇 가지 어려움이 있음 - 동시에 말하는 speaker를 분리하는 것과 같이 object를 구별하는 것이 어려움 - Scarce text annotation은 모델의 확장을 어렵게 함 - 고품질 audio 합성을 위해서는 높은 sampling rate가 필요하므로 sequence가 길어짐 AudioGen Learnt discrete audio representation을 기반으로 동작하는 autoregressive 모델 다양한 audio sample을 mix 하여 모델이 source 분리를 internally learn 하는 augmentation을 도입 빠른 추론을 위해 multi-strea..