

 [Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
[Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
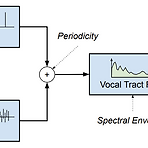
Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech SynthesisNeural vocoder를 통해 고품질의 audio를 합성할 수 있지만, 여전히 low-end device에서는 real-time으로 사용하기 어려움한편으로 Digital Signal Processing 기반의 vocoder는 lightweight FFT를 통해 구현될 수 있으므로 neural vocoder보다 빠르게 동작가능함- BUT, vocal tract의 approximate representation에 대해 over-smoothed acoustic model prediction을 사용하므로 합성 품질이 저하되는 경향이 있음DDSP VocoderDi..
 [Paper 리뷰] AutoVocoder: Fast Waveform Generation from a Learned Speech Representation Using Differentiable Digital Signal Processing
[Paper 리뷰] AutoVocoder: Fast Waveform Generation from a Learned Speech Representation Using Differentiable Digital Signal Processing
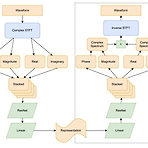
AutoVocoder: Fast Waveform Generation from a Learned Speech Representation Using Differentiable Digital Signal Processing Mel-spectrogram은 waveform으로부터 간단하게 추출될 수 있지만, mel-spectrogram에서 waveform을 생성하는 vocoder에는 많은 계산 비용이 필요함 AutoVocoder 기존 mel-spectrogram 방식에서 벗어나 inverse STFT의 differentiable implementation을 사용하여 waveform을 생성 결과적으로 기존 neural vocoder에 비해 14배 이상의 가속 효과를 달성 논문 (ICASSP 2023) : Paper..
 [Paper 리뷰] DDSP: Differentiable Digital Signal Processing
[Paper 리뷰] DDSP: Differentiable Digital Signal Processing
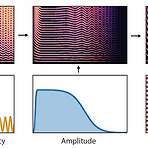
DDSP: Differentiable Digital Signal Processing대부분의 audio 생성 모델은 time 또는 frequency domain 중 하나에서 sampling을 생성함- Signal을 표현하는 데는 적합하지만 sound가 생성되고 인식되는 방식에 대한 knowledge를 활용하지 않음Vocoder의 경우 domain knowledge를 성공적으로 반영할 수 있지만 auto-differentiable-based 방식과는 통합하기 어려움Differentiable Digital Signal Processing (DDSP)기존의 signal processing 요소를 deep learning 방식과 통합Neural network의 expressive power를 잃지 않으면서 강력한..