

티스토리 뷰
Paper/Representation
[Paper 리뷰] Wav2Vec-C: A Self-Supervised Model for Speech Representation Learning
feVeRin 2025. 6. 5. 17:34반응형
Wav2Vec-C: A Self-Supervised Model for Speech Representation Learning
- Wav2Vec 2.0과 VQ-VAE를 combine 하여 representation learning을 수행할 수 있음
- Wav2Vec-C
- Wav2Vec 2.0과 같이 contrastive loss를 사용하여 partially masked speech encoding에서 quantized representation을 reproduce하는 방법을 학습
- 이때 VQ-VAE와 같이 quantized representation에서 Wav2Vec 2.0 network의 input feature를 reconstruct 하는 consistency network를 통해 quantization process를 regularize
- 논문 (INTERSPEECH 2021) : Paper Link
1. Introduction
- Self-supervision은 data의 structural pattern을 contextual information으로 exploit 하여 unsupervised learning을 수행하는 방식으로써, 특히 Automatic Speech Recognition (ASR)에서 우수한 성능을 보이고 있음
- ASR task는 supervision을 위한 labeled data는 적지만 self-supervision을 위한 unlabeled data는 많기 때문
- 대표적으로 Wav2Vec 2.0은 Transformer의 contextualized representation을 활용하여 masked discrete speech encoding을 predict 함
- 특히 discretized code에 대해 정의된 contrastive loss를 통해, codebook을 포함한 built-in differentiable Vector Quantization module에서 self-supervision을 drive 함
-> 그래서 Wav2Vec 2.0을 기반으로 rigorously defined self-supervised learning problem을 solve 할 수 있는 Wav2Vec-C를 제안
- Wav2Vec-C
- Discrete speech representation에 대한 additional regularization을 통해 codebook learning을 facilitate 하고 discrete code를 input feature로 reconstruct
- 이를 통해 learnt representation과 input feature 간의 consistency를 maintain
< Overall of Wav2Vec-C >
- Wav2Vec 2.0과 VQ-VAE를 combine한 Self-Supervised Learning model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- Wav2Vec 2.0
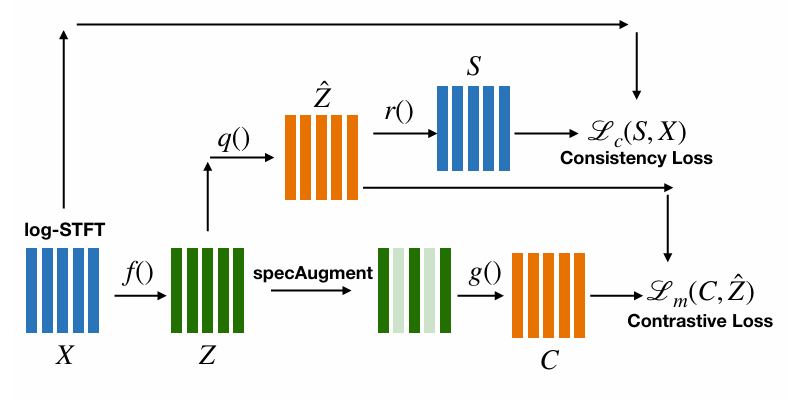
- 논문은 Wav2Vec 2.0을 기반으로 하는 대신, log-STFT feature를 input으로 사용함
- 먼저 encoder network $f:\mathcal{X}\rightarrow \mathcal{Z}$는 input feature $X=[x_{1},x_{2},...,x_{T}]$를 latent embedding space로 mapping 함
- 이후 해당 embedding은 vector quantization module $q:\mathcal{Z}\rightarrow \hat{\mathcal{Z}}$에 의해 quantize 됨
- Embedded vector $Z=[z_{1},z_{2},...,z_{T}]\in\mathcal{Z}$는 SpecAugment module을 통해 embedding의 portion을 randomly mask 하여 $Z_{masked}$를 생성함 - Masked embedding은 context network $g:\mathcal{Z}\rightarrow \mathcal{C}$에 전달되어 context representation $C=[c_{1},c_{2},...,c_{T}]$의 set을 생성함
- Network training 시에는 context representation과 vector quantized embedding $\hat{Z}=[\hat{z}_{1},\hat{z}_{2},...,\hat{z}_{T}]$ 간의 contrastive score를 maximize 함
- Wav2Vec-C
- Wav2Vec 2.0은 $q$가 학습한 underlying speech unit과 관련된 diverse code set을 활용하여, $g$가 contrastive loss를 통해 contextual representation을 학습할 수 있도록 함
- BUT, Wav2Vec 2.0의 problem formulation은 locally-optimal codebook을 생성할 수 있음
- 이때 highly probable optima는 다음과 같음:
- Voice Activity Detection (VAD) codebook
- Speech, non-speech애 대한 2가지 code를 assign 하는 방법 - Temporally Invariant codebook
- Model이 specific code를 fixed temporal location에 assign 하여 good contrastive loss를 얻는 방법
- Voice Activity Detection (VAD) codebook
- 한편으로 논문의 training data는 fixed temporal location에서 발생하는 similar query term으로 구성됨
- 이는 model이 underlying speech sound와 irrespective 하게 recurrent encoder를 통해 specific temporal instance에서 fixed code를 assign 하도록 함
- 따라서 기존 Wav2Vec 2.0의 codebook learning method는 다른 dataset이나 model architecture에 대해 generalize 되기 어려움
- 해당 codebook learning 문제를 해결하기 위해 Wav2Vec-C는 code가 input feature $X$에 대한 information을 explicitly carry 하도록 enforce 함
- 먼저 additional consistency network $r:\hat{\mathcal{Z}}\rightarrow \mathcal{S}$를 통해 quantized encoding $\hat{Z}=[\hat{z}_{1},\hat{z}_{2},...,\hat{z}_{T}]$를 consistency vector $S=[s_{1},s_{2},...,s_{T}]$로 reconstruct 함
- 그리고 network training 중에 input $X$와 $S$ 간의 normed distance를 minimize 함 - 해당 network는 input log-STFT feature에서 feature domain으로 information flow를 allow 하고, latent space가 low reconstruction error를 위한 meaningful information을 preserve 하도록 함
- 결과적으로 이는 Wav2Vec 2.0과 VQ-VAE를 integrate 한 것으로 볼 수 있음
- 먼저 additional consistency network $r:\hat{\mathcal{Z}}\rightarrow \mathcal{S}$를 통해 quantized encoding $\hat{Z}=[\hat{z}_{1},\hat{z}_{2},...,\hat{z}_{T}]$를 consistency vector $S=[s_{1},s_{2},...,s_{T}]$로 reconstruct 함
- Encoder Network $f$
- Wav2Vec-C의 encoder network $f$는 hidden dimension이 768인 3-layer LSTM으로 구성됨
- Encoder gradient는 training 중에 codebook stabilize를 위해 $\gamma=0.1$의 factor로 scale 됨
- Vector Quantization $q$
- 논문은 $G$ codebook $Q=[Q^{(1)},Q^{(2)},...,Q^{(G)}]$와 product quantization module을 활용함
- 먼저 각 codebook $Q^{(i)}\in\mathbb{R}^{V\times K}$는 dimension $K$의 $V$ code set으로 represent 됨
- LSTM encoded representation $z\in\mathbb{R}^{768}$은 $G$ representation set $z_{split}=\{z^{(1)},z^{(2)},...,z^{(G)}\}$로 split 됨
- $z^{(i)}\in\mathbb{R}^{768/G},\,\in\{1,2,...,G\}$ - 이후 각 $z^{(i)}$는 $Q^{(i)}$에서 하나의 code $e\in \mathbb{R}^{K}$를 select 하여 quantized representation $\hat{z}^{(i)}$를 얻음
- 최종적으로 모든 codebook에서 representation $\hat{z}^{(i)},\,i=\{1,2,...,G\}$는 final quantized encoding $\hat{z}$를 구성하기 위해 concatenate 됨
- 논문은 $V=320$ code, $K=384$ dimension을 가진 $G=2$ codebook을 사용함
- 추가적으로 Wav2Vec-C는 다음 2가지의 VQ technique을 고려함:
- Gumbel-Softmax
- 각 split $z^{(i)}\in z_{split}$은 trainable linear transformation을 통과하여 logit $l^{(i)}\in\mathbb{R}^{V}$를 생성함
- 해당 logit은 Gumbel-Softmax를 통과하여 forward pass에서 code selector로 사용할 수 있는 $V$ code에 대한 hard distribution을 생성함 - Backpropagation 시에는 softmax distribution의 true gradient를 사용하여 code selection process를 completely differentiable 하게 구성함
- 각 split $z^{(i)}\in z_{split}$은 trainable linear transformation을 통과하여 logit $l^{(i)}\in\mathbb{R}^{V}$를 생성함
- $k$-means
- Forward pass에서 $k$-means codebook은 $z^{(i)}$에 대해 closest squared distance의 code $e$를 $Q^{(i)}$로부터 select 함:
(Eq. 1) $\hat{z}^{(i)}=\arg\min_{e\in Q^{(i)}}||z^{(i)}-e||_{2}$
- BUT, backpropagation에서 straight-through estimator는 quantized embedding에 대한 gradient computation을 bypass 하고 graident를 continuous embedding $z$에 copy 함 - 따라서 논문은 2가지의 loss term을 추가로 incorporate 함:
(Eq. 2) $\mathcal{L}_{k}=\left|\left| \text{sg}(z^{(i)})-\hat{z}^{(i)}\right|\right|_{2}+ \beta\left|\left| z^{(i)}-\text{sg}(\hat{z}^{(i)})\right|\right|_{2}$
- $\text{sg}(\cdot)$ : stop-gradient operator, $\beta=0.25$ : hyperparameter - $\mathcal{L}_{k}$의 minimization에서, first term은 quantized representation이 continuous encoded representation에 close 하도록 push 함
- Commitment loss에 해당하는 second term은 encoding $z^{(i)}$가 quantized embedding $\hat{z}^{(i)}$에 commit 하도록 enforce 함
- Forward pass에서 $k$-means codebook은 $z^{(i)}$에 대해 closest squared distance의 code $e$를 $Q^{(i)}$로부터 select 함:
- Gumbel-Softmax
- Masking
- Context network 이전에 continuous encoding $Z=[z_{1},z_{2},...,z_{T}]$의 portion을 mask 하기 위해 SpecAugment module을 도입함
- 이때 각 utterance 마다 5개의 mask를 사용하고, 각 mask의 maximum width는 utterance length의 $16\%$에 해당함
- 평균적으로 논문은 encoded frame의 $40\%$를 mask 함
- 이때 각 utterance 마다 5개의 mask를 사용하고, 각 mask의 maximum width는 utterance length의 $16\%$에 해당함
- Context Network $g$
- Context network는 model dimension 1024, inner feed-forward dimension 4096, 16 attention head, sinusoidal positional embedding을 가지는 5개의 Transformer layer로 구성됨
- Context representation $C=[c_{1},c_{2},...,c_{T}]$와 quantized encoding $\hat{Z}=[\hat{z}_{1},\hat{z}_{2},...,\hat{z}_{T}]$ 간의 contrastive score는:
(Eq. 3) $ \mathcal{L}_{m}=-\log\frac{\exp(d(c_{t},\hat{z}_{t}))/\kappa}{\sum_{z\in\Theta}\exp(d(c_{t},z))/\kappa}$
- $t\in\{1,2,...,T\}$, $\Theta$ : $\hat{z}_{t}$와 $N$ negative sample의 selection으로 구성된 set
- $\kappa$ : temperature variable, $d$ : cosine similarity $d(x,y)=\frac{x^{\top}y}{||x||\,||y||}$ - 논문은 utterance encoding $\hat{Z}$에서 $N=50$의 negative sample을 uniformly sample 하고, Wav2Vec 2.0을 따라 $\kappa$를 update 함
- Context representation $C=[c_{1},c_{2},...,c_{T}]$와 quantized encoding $\hat{Z}=[\hat{z}_{1},\hat{z}_{2},...,\hat{z}_{T}]$ 간의 contrastive score는:
- Consistency Network $r$
- Consistency network $r$은 quantized embedding $\hat{Z}=[\hat{z}_{1},\hat{z}_{2},...,\hat{z}_{T}]$를 consistency vector $S=[s_{1},s_{2},...,s_{T}]$로 mapping 하는 3-layer LSTM으로 구성되고, $S,X$ 간의 $L_{2}$ normed distance를 다음과 같이 minimize 함:
(Eq. 4) $\mathcal{L}_{c}=||x_{t}-s_{t}||_{2}$
- Loss
- Training 시 primary contrastive loss와 함께 codebook loss, consistency loss를 minimize 함
- 이때 training loss는:
(Eq. 5) $\mathcal{L}=\mathcal{L}_{m}+\mathcal{L}_{cb}+\gamma\mathcal{L}_{c}$
- Codebook loss $\mathcal{L}_{cb}$는 VQ type에 따라 다른 형태를 가짐
- $\gamma=0$인 경우 consistency loss가 ignore 되므로 Wav2Vec 2.0에 해당하고, $\gamma=1$인 경우 Wav2Vec-C에 해당함 - Gumbel-softmax VQ의 경우, codebook loss는 $\mathcal{L}_{cb}=\alpha\mathcal{L}_{d}$로 주어지고, 이때 $\mathcal{L}_{d}$는 Gumbel-softmax distribution에 대한 diversity loss를 의미함:
(Eq. 6) $\mathcal{L}_{d}=\frac{GV-\sum_{g=1}^{G}\exp\left(-\sum_{v=1}^{V} p_{g,v}\log p_{g,v}\right)}{GV}$
- $p_{g,v}$ : $v$-th code에 대한 $g$-th codebook의 probability assignment
- $\alpha=1.5$ : VQ의 codebook collapse를 방지하기 위한 weight - $k$-means VQ의 경우, codebook loss는 $k$-means loss와 동일함 (즉, $\mathcal{L}_{cb}=\mathcal{L}_{k}$)
- 이때 training loss는:
3. Experiments
- Settings
- Dataset : 아래 표 참고
- Comparisons : Wav2Vec 2.0

- Results
- Wav2Vec-C를 적용하는 경우 전반적인 ASR 성능을 향상할 수 있음

- Discussions on Codebook Utilization
- Wav2Vec-C (GS)는 $100\%$의 codebook utilization을 달성할 수 있음

- $t$-SNE 측면에서 Wav2Vec-C는 inter-cluster overlap이 나타나지 않음

반응형
'Paper > Representation' 카테고리의 다른 글
댓글