

반응형
 [Paper 리뷰] VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
[Paper 리뷰] VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
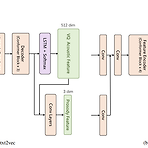
VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature대부분의 text-to-speech 모델은 acoustic model과 vocoder로 구성된 cascade system을 기반으로 함이때 acoustic feature로써 일반적으로 mel-spectrogram을 활용하는데, 이는 time-frequency axis를 따라 high-correlated 되어 있기 때문에 acoustic model로 예측하기 어려움VQTTS일반적인 mel-spectrogram이 아닌 self-supervised Vector-Quantized acoustic feature에 대해 acoustic model로써 txt2vec..
Paper/TTS
2024. 4. 30. 09:35
반응형