
반응형
 [Paper 리뷰] MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors
[Paper 리뷰] MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors
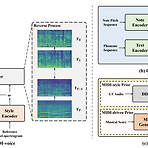
MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors기존의 Singing Voice Synthesis 모델은 unseen speaker와 fundamental frequency를 부정확하게 예측하므로 낮은 합성 품질을 보임MIDI-Voice더 나은 singing voice style adaptation을 위해 MIDI-based prior를 score-based diffusion model에 적용특히 MIDI-driven prior를 생성하여 note information을 반영하고 고품질의 style adaptation을 지원추가적으로 expressive synthesis를 위해 DDSP-based MIDI-sty..
Paper/SVS
2024. 5. 13. 10:29
반응형