
반응형
 [Paper 리뷰] DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
[Paper 리뷰] DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
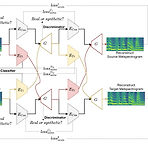
DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised LearningAny-to-Any voice conversion은 training data에서 벗어난 source/target speaker에 대해 voice conversion을 수행하는 것을 목표로 함- BUT, 기존의 disentangle-based model은 speaker/content style information를 얻는 과정에서 untangle overlapping 문제가 발생함DRVC (Disentangled Representation Voice Conversion)Content encoder, timbre encoder, generator로 구성된 end-to-e..
Paper/Conversion
2024. 8. 14. 09:39
반응형