
반응형
 [Paper 리뷰] DelightfulTTS2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
[Paper 리뷰] DelightfulTTS2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
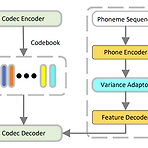
DelightfulTTS2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders일반적으로 text-to-speech는 mel-spectrogram을 intermediate representation으로 사용하는 cascaded pipeline을 활용함BUT, acoustic model과 vocoder는 개별적으로 training 되고, pre-designed mel-spectrogram은 sub-optimal 하다는 한계가 있음DelightfulTTS2Automatically learned speech representation과 joint optimization을 활용한 end-to-end text-to-speech 모..
Paper/TTS
2024. 7. 1. 09:59
반응형