

반응형
 [Paper 리뷰] CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech Synthesis
[Paper 리뷰] CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech Synthesis
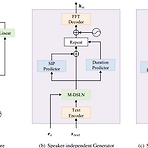
CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech SynthesisCross-lingual Text-to-Speech 성능은 여전히 intra-lingual 성능보다 떨어짐CrossSpeechSpeaker와 language information의 disentangling을 acoustic feature space level에서 효과적으로 disentangling 하여 cross-lingual text-to-speech 성능을 향상이를 위해 Speaker-Independent Generator와 Speaker-Dependent Generator를 도입하고 각 information을 개별적으로 처리함으로써 dis..
Paper/TTS
2024. 5. 27. 10:14
반응형