

반응형
 [Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
[Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
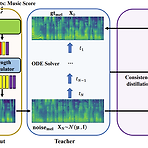
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency ModelDenoising Diffusion Probabilistic Model은 음성 합성에서 우수한 성능을 보이고 있지만, 고품질의 sample을 얻기 위해서는 많은 iterative step이 필요함- 결과적으로 추론 속도 저하로 이어짐CoMoSpeechSingle diffusion sampling step만으로 고품질의 합성을 수행하는 Consistency model-based 음성 합성 모델Consistency constraint는 diffusion-based teacher model에서 consistency model을 distill 하기 위해 사용됨논문 (MM 20..
Paper/TTS
2024. 4. 28. 12:14
반응형