

반응형
 [Paper 리뷰] AutoTTS: End-to-End Text-to-Speech Synthesis through Differentiable Duration Modeling
[Paper 리뷰] AutoTTS: End-to-End Text-to-Speech Synthesis through Differentiable Duration Modeling
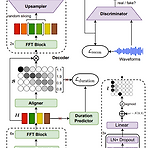
AutoTTS: End-to-End Text-to-Speech through Differentiable Duration ModelingText-to-Speech 모델은 일반적으로 external aligner가 필요하고, decoder와 jointly train 되지 않으므로 최적화의 한계가 있음AutoTTSInput, output sequence 간의 monotonic alignment를 학습하기 위해 differentiable duration method를 도입Expectation에서 stochastic process를 최적화하는 soft-duration mechanism을 기반으로 하여 direct text-to-waveform synthesis 모델을 구축추가적으로 adversarial train..
Paper/TTS
2024. 5. 30. 13:54
반응형