

반응형
 [Paper 리뷰] UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
[Paper 리뷰] UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
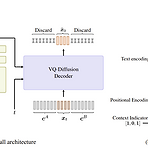
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and VocodingSemantic token과 acoustic token으로 나누어진 discrete speech token을 활용하면 text-to-speech의 성능을 향상 가능대표적으로 VALL-E와 SPEAR-TTS는 짧은 speech prompt에서 추출된 acoustic token에 대한 autoregressive continuation으로 zero-shot speaker adaptation이 가능함- BUT, 해당 autoregressive 모델은 순차적으로 수행되므로 speaker editing에는 적합하지 않고, audio code..
Paper/TTS
2024. 4. 6. 11:54
반응형