

 [Paper 리뷰] FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder with Multiple STFTs
[Paper 리뷰] FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder with Multiple STFTs
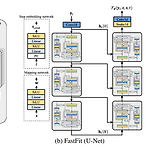
FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder with Multiple STFTsU-Net encoder를 multiple Short-Time Fourier Transform (STFT)로 대체하여 sample 품질을 유지하면서 더 빠른 합성 속도를 얻을 수 있음FastFit각 encoder block을 STFT로 대체하고 decoder block의 temporal resolution과 동일한 parameter를 사용해 skip connection으로 연결이를 통해 high-fidelity의 sample을 유지하면서 parameter 수와 생성 속도를 절반으로 줄임논문 (INTERSP..
 [Paper 리뷰] FC-U$^{2}$-Net: A Novel Deep Neural Network for Singing Voice Separation
[Paper 리뷰] FC-U$^{2}$-Net: A Novel Deep Neural Network for Singing Voice Separation
FC-U$^{2}$-Net: A Novel Deep Neural Network for Singing Voice Separation 혼합된 음악 신호에서 보컬과 반주(accompainment)를 분리하는 가창 음성 분리를 위한 신경망 FC-U$^{2}$-Net 주파수 축을 따라 Time-invariant fully connected layer가 추가된 2단계 중첩 U-Net 구조 Local/Global contextual information 및 주파수 축에 대한 음성 신호의 장거리 상관관계를 캡처 깨끗한 보컬 분리를 위한 ratio mask, binary mask를 결합한 loss function의 사용 논문 (TASLP 2022) : Paper Link 1. Introduction 가창 음성 분리(Si..